/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
- Missingo
В несгенерированных датасетах, как правило, имеется большое количество пустых или Null значений. Это может быть связано с разными причинами, такими как утечка данных, недоступность информации и т.п. Иногда, очень важно разобраться с такими «грязными» данными, прежде чем сформировать модель на их основе. Библиотека Missingo, основанная на Matplotlib, может помочь в выборе метода нормализации данных при помощи визуализации количества пропусков для каждого признака. На данный момент имеется четыре типа диаграмм для отображения – chart, heatmap, matrix и dendogram.
Импортируем датасет о дорожных происшествиях в Нью-Йорке (NYPD Motor Vehicle Collisions Dataset):

Импорт библиотеки и вывод матрицы первых 250 строк:

При работе с временными данными, можно указать периоды для отображения с помощью параметра freq:


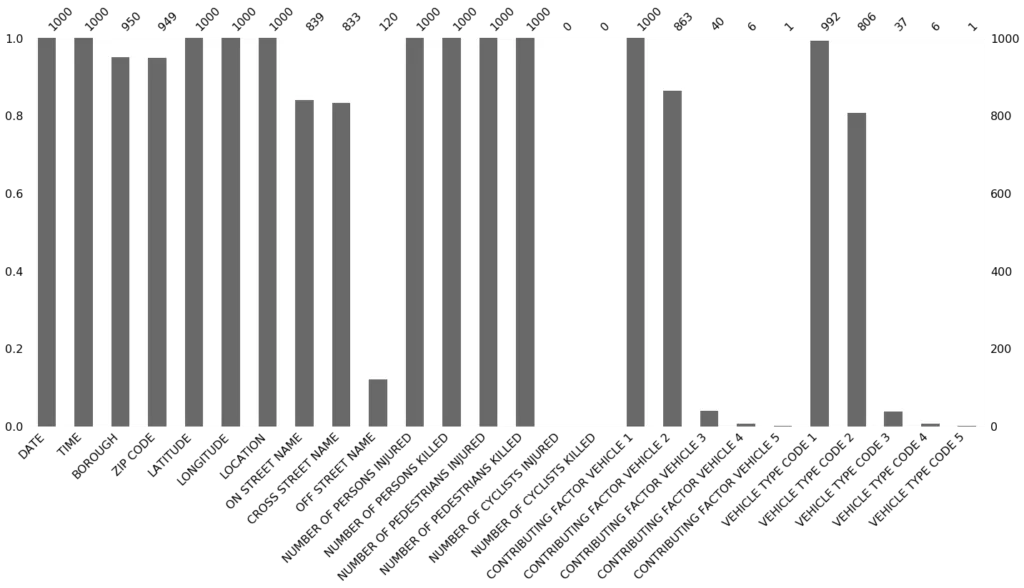
Визуализация в виде гистограммы:

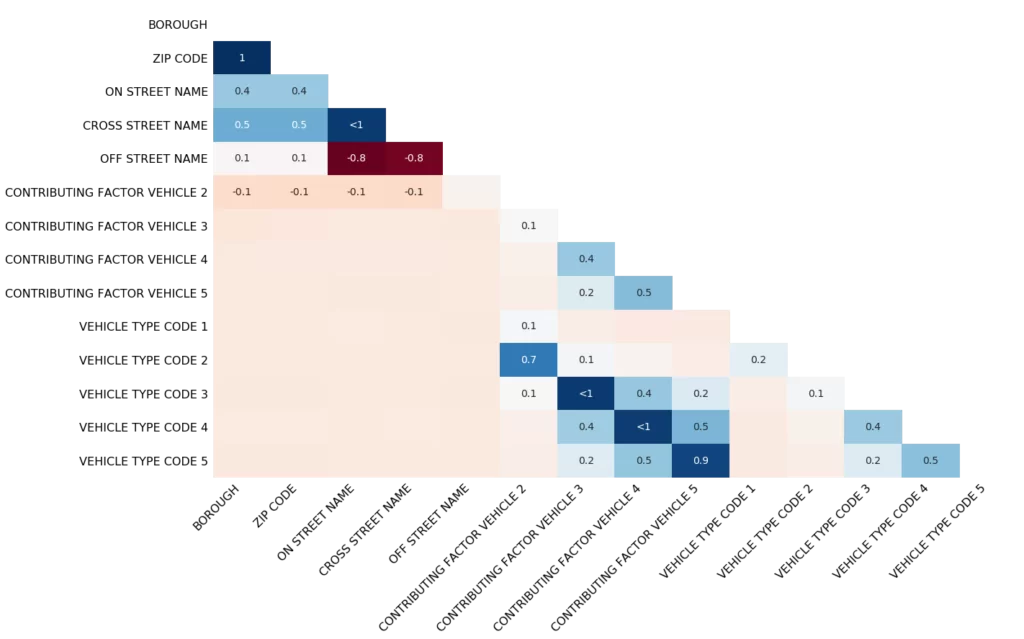
Визуализация в виде Heatmap:

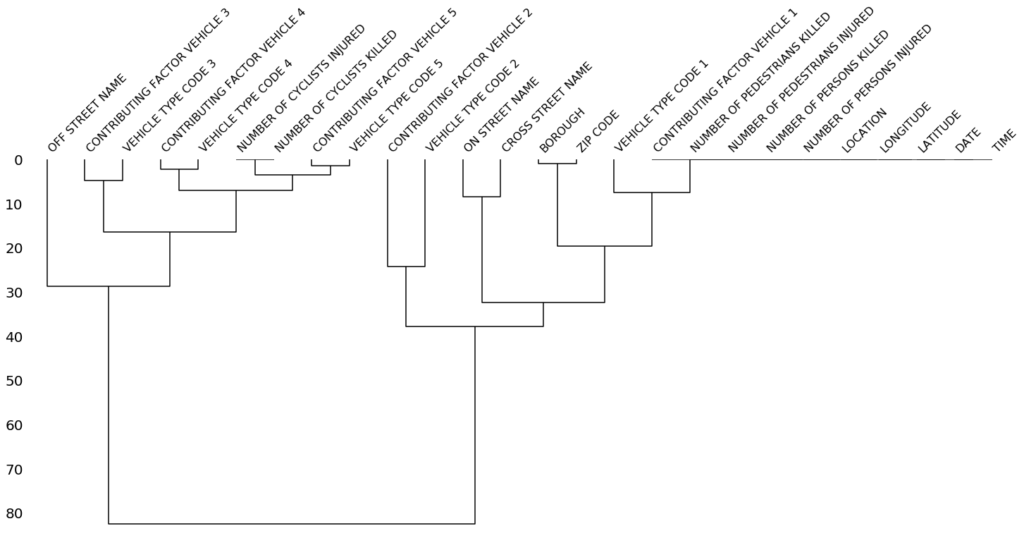
Визуализация в виде Dendrogram:

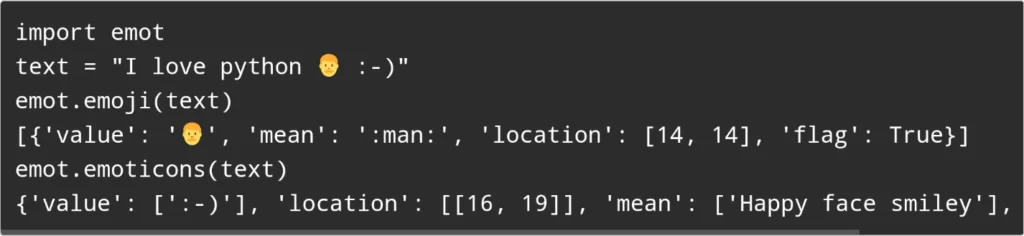
2. Emot
Эмоджи используются в интернете повсеместно. При решении задач NLP их обработка может оказаться очень утомительным занятием. Данная библиотека поможет избавиться от смайликов и трансформировать их в текст. На входе получает объект типа string, на выходе – список из словарей.
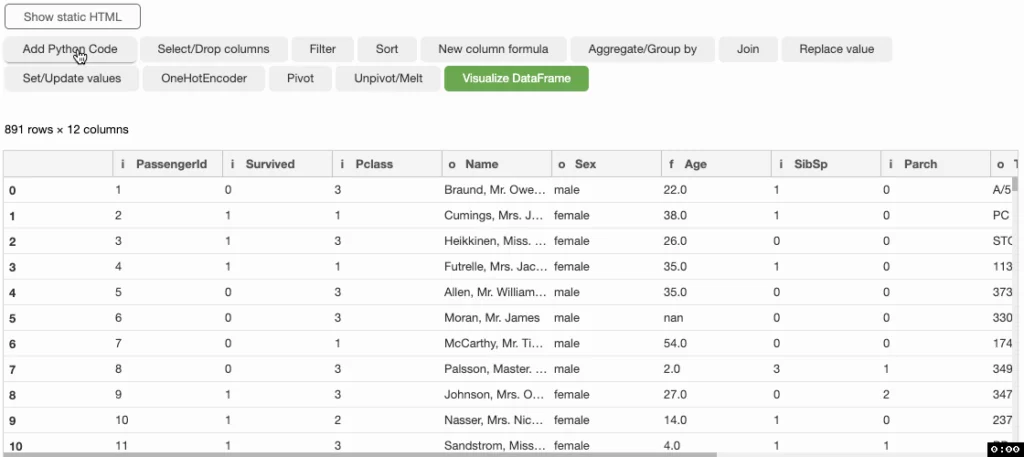
3. Bamboolib
Анализ и визуализация информации – это важные и трудозатратные составляющие процесса машинного обучения. Bamboolib – графический интерфейс для работы с датафреймами pandas, применяемый в Jupiter Notebook и JupyterLab. Предназначен для изучения, отображения и контроля данных. На самом деле, даже человек не обладающий развитыми компетенциями в области программирования может использовать данный GUI для получения необходимой информации. Однако, Bamboolib не имеет открытого кода, что означает необходимость его приобретения после бесплатного 14-дневного периода использования.
Intro в Bamboolib на Youtube:
4. Ppscore
Полное название – Predictive Power Score. Библиотека создана разработчиками Bamboolib и является альтернативой корреляционной матрице. Может определять линейные и нелинейные зависимости признаков в датасете.
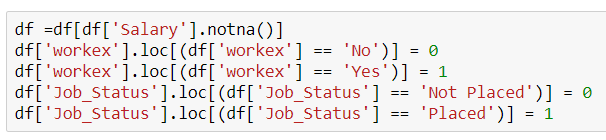
Импортируем необходимые библиотеки:
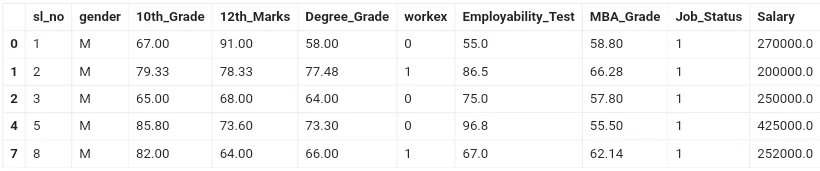
Используем датасет об устройстве не работу аспирантов после получения докторской степени:

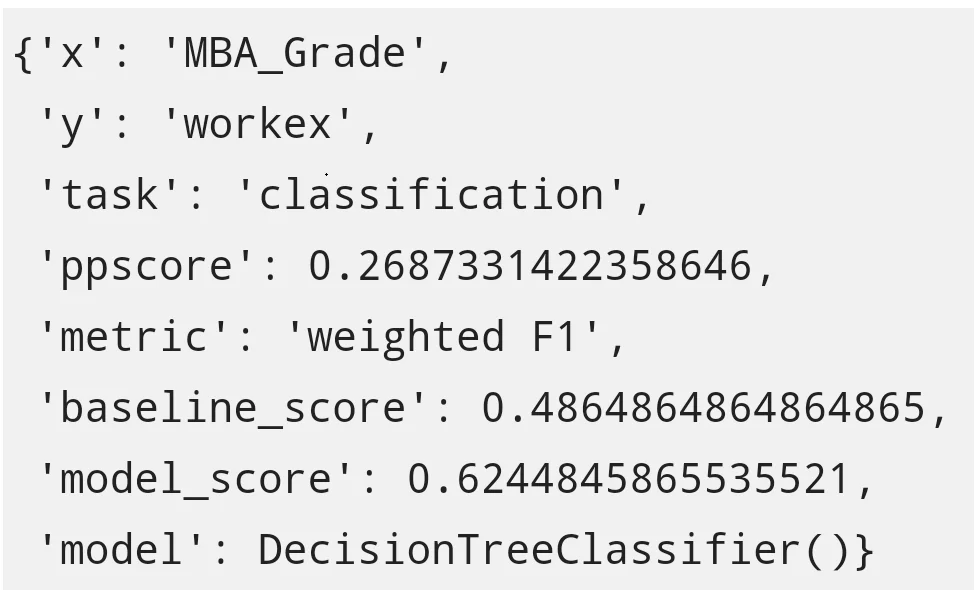
Отображение зависимости между двумя полями, чем ниже ppsscore, тем слабее взаимосвязь:

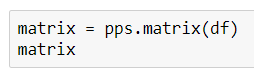
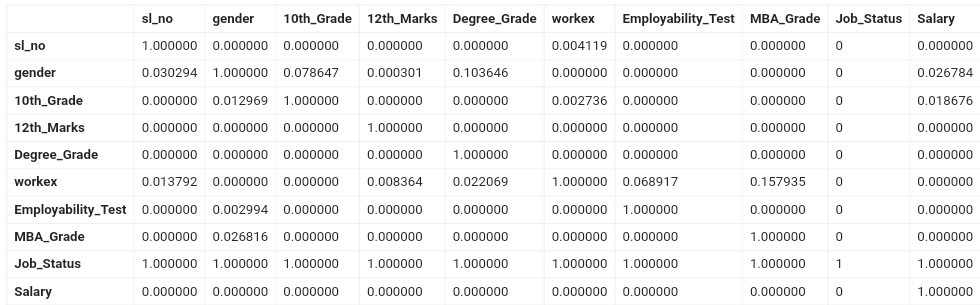
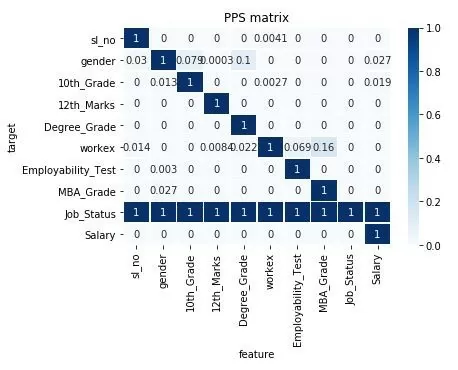
Для визуализации в виде heatmap создадим функцию:

5. AutoViz
Одна из самых недооцененных библиотек в DA. Автоматически визуализирует любые типы и объемы данных. Красивые диаграммы можно строить при помощи одной строки кода. Вы просто указываете расположения файла с данными (txt, JSON или CSV) и библиотека автоматически визуализирует их.
Инициализация класса:

Указываем источник данных:

После этого автоматически создается директория Autoviz plots, в которую сохраняются следующие диаграммы:
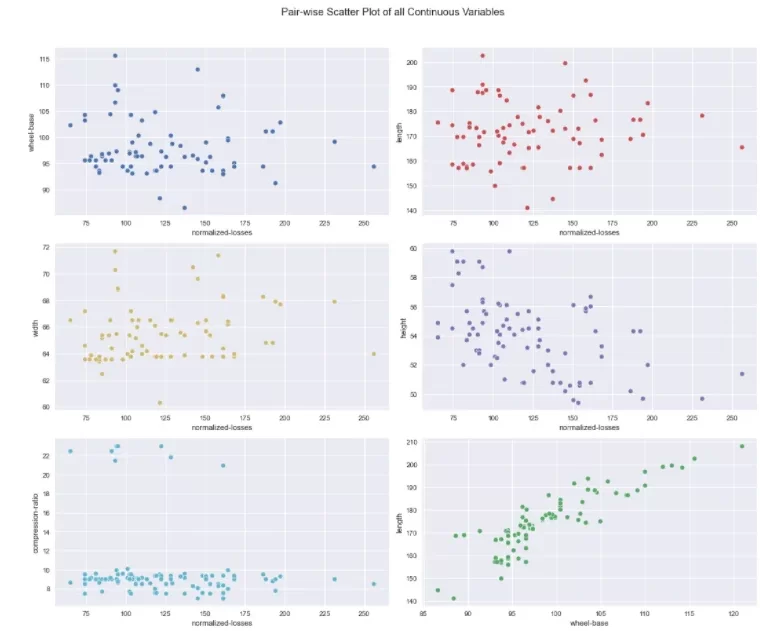
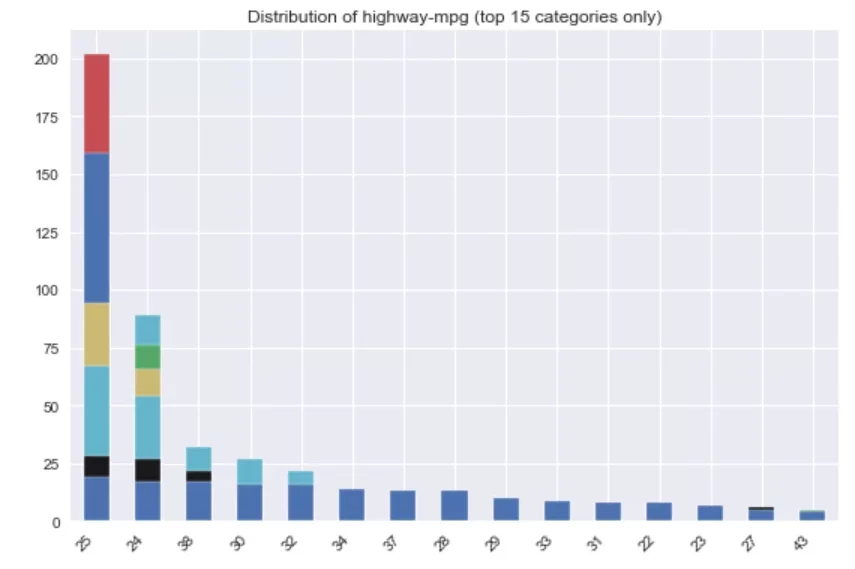
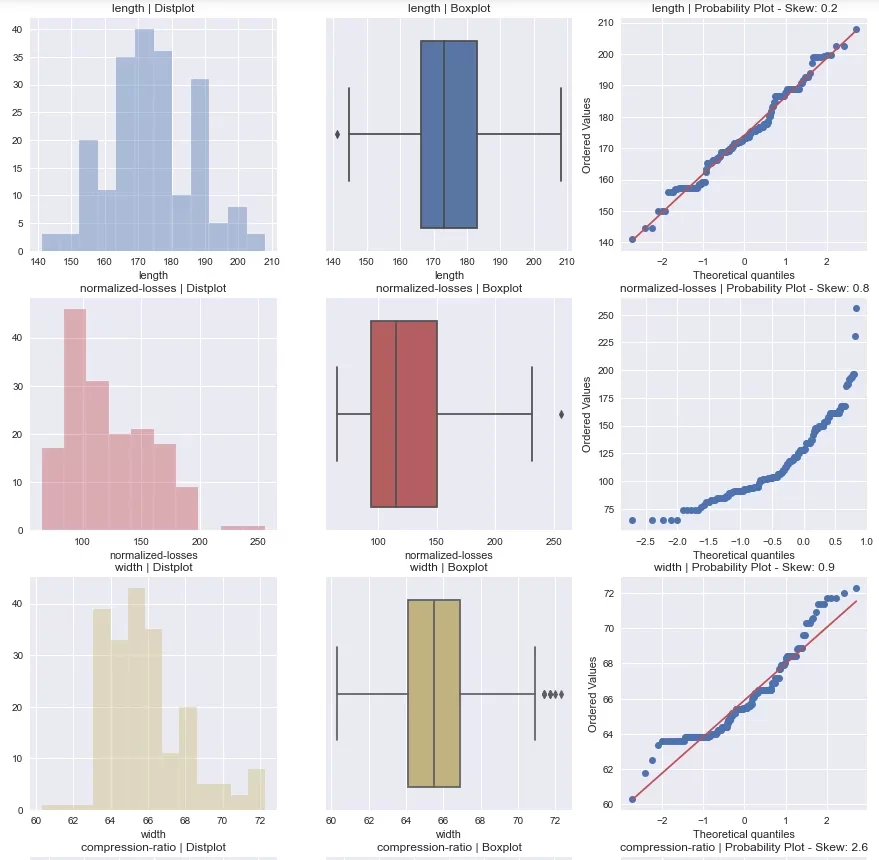
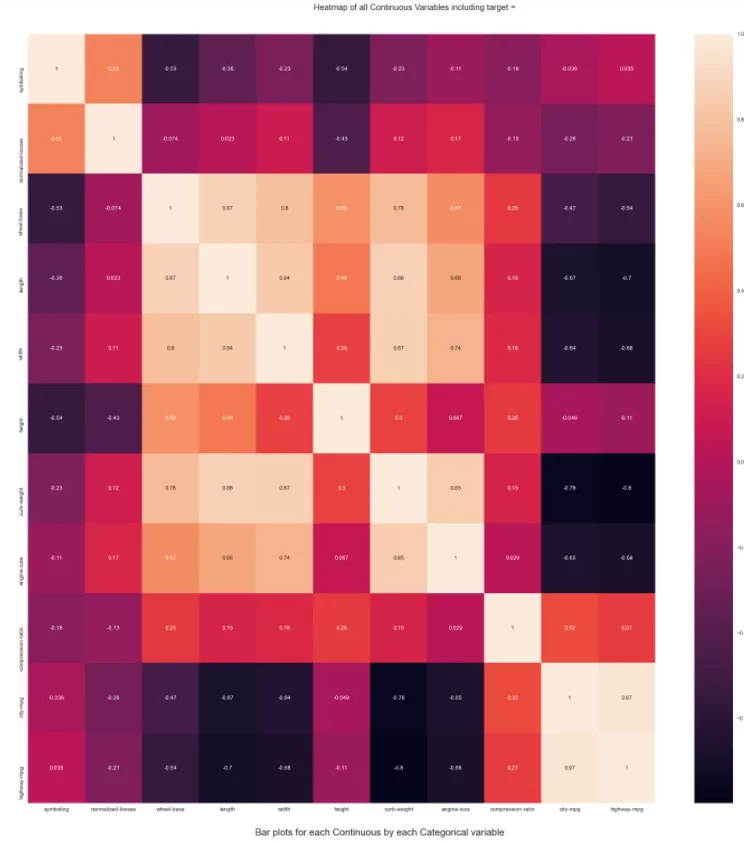
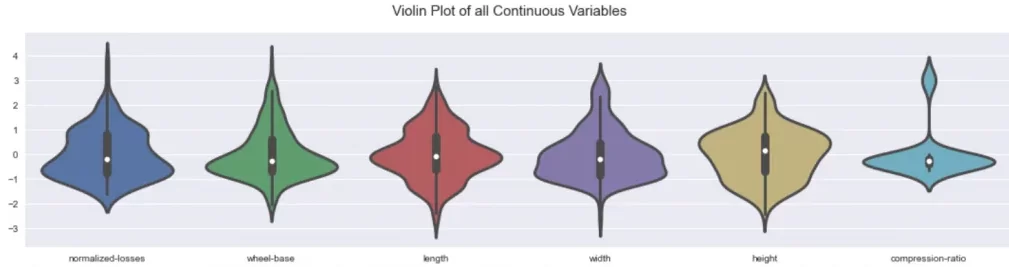
6. Numerizer
Интересный модуль для анализа текста. Он преобразует числа, написанные словами, в int и float. Например, конвертирует “forty-two” в 42 или “one billion and one” в 1 000 000 001. Из минусов – работает только с английским языком, но существует аналог для русского языка Word-to-Number-Russian.

7. PyFlux
Анализ временных рядов, возможно, одна из самых часто встречающихся проблем в машинном обучении. PyFlux это open-source библиотека, созданная для решения таких задач при помощи построения ARIMA, GARCH, VAR и других моделей.
Импорт библиотек:

Загрузка датасета с курсом акций Yahoo:


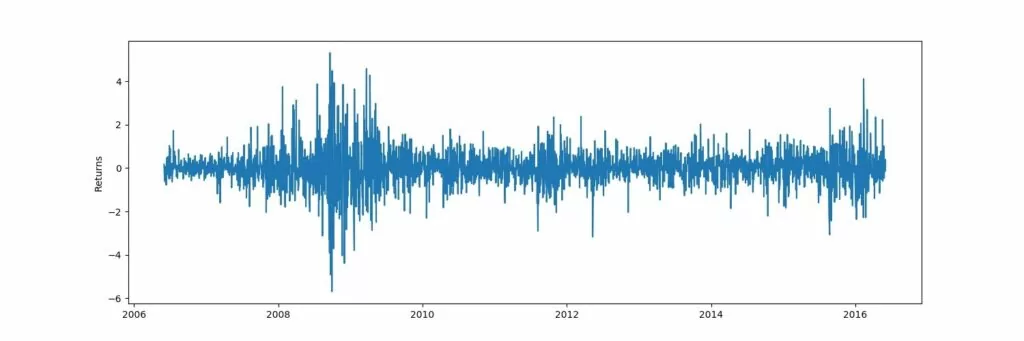
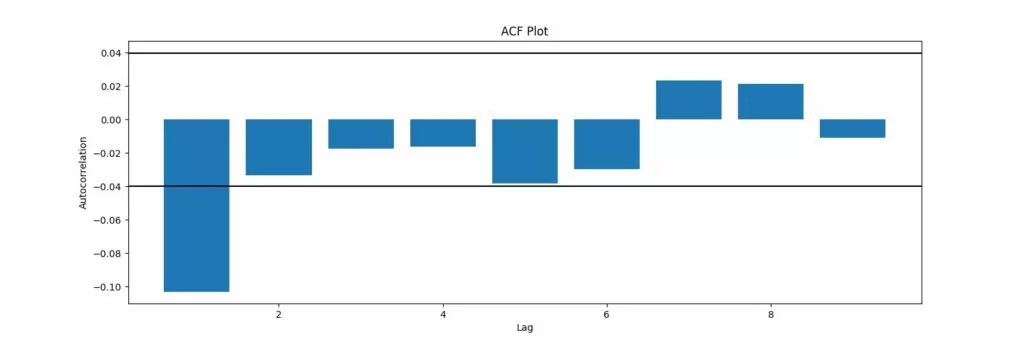
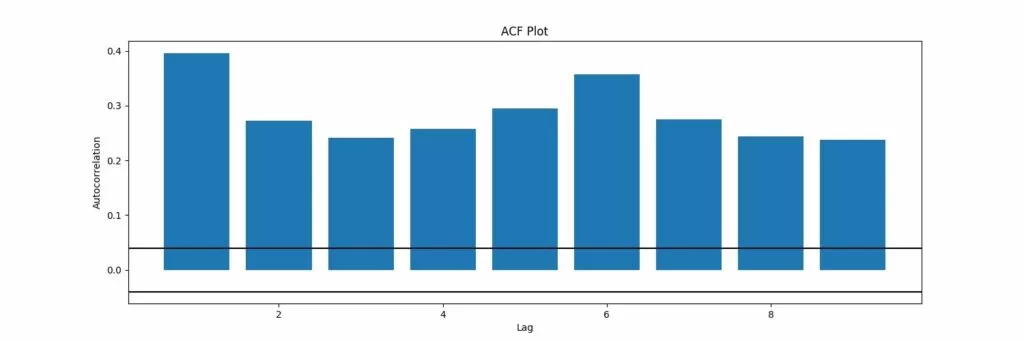
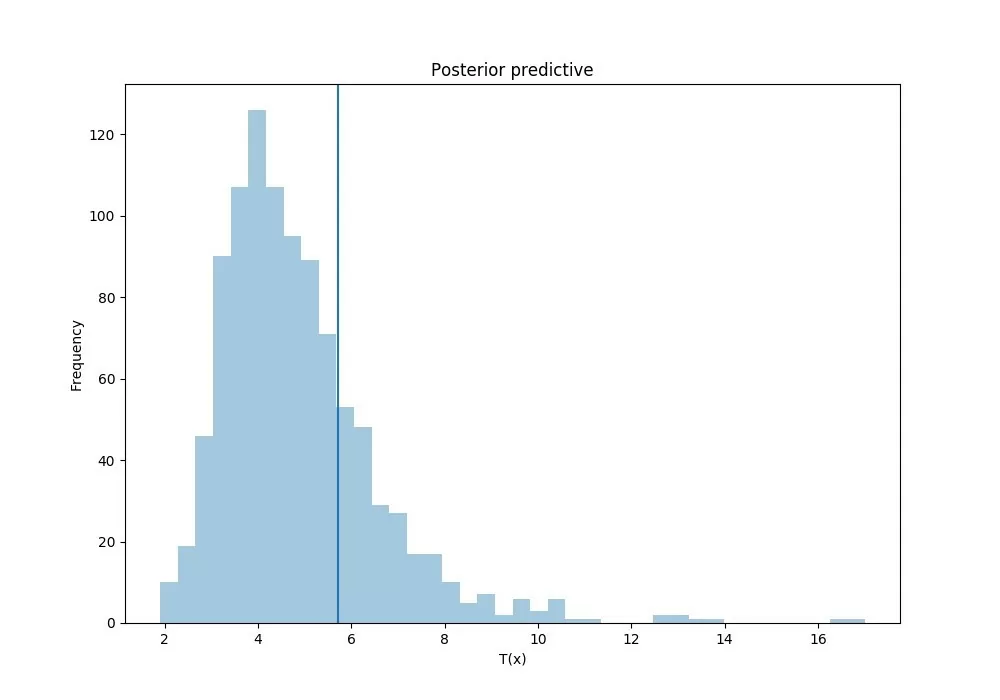
Обучение ARIMA модели, вывод результатов:

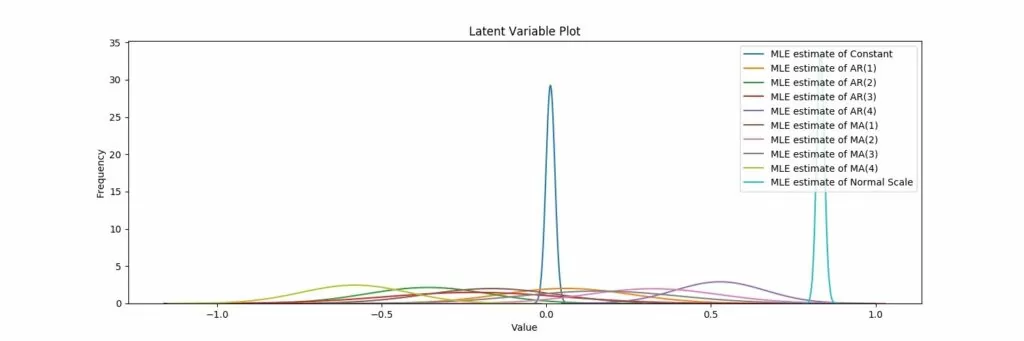

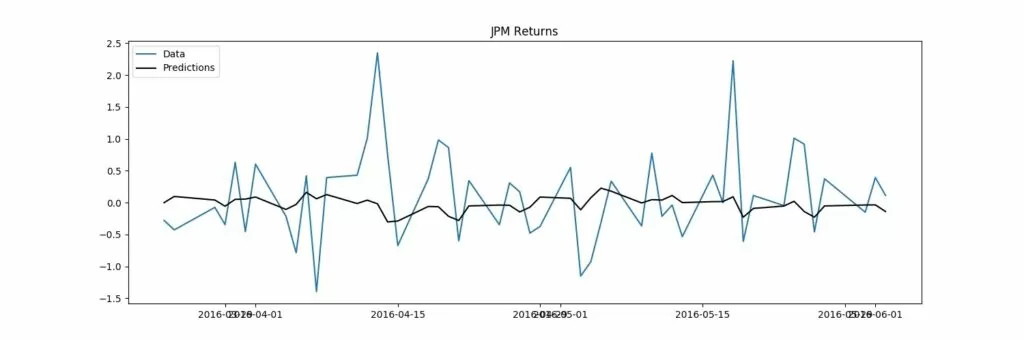
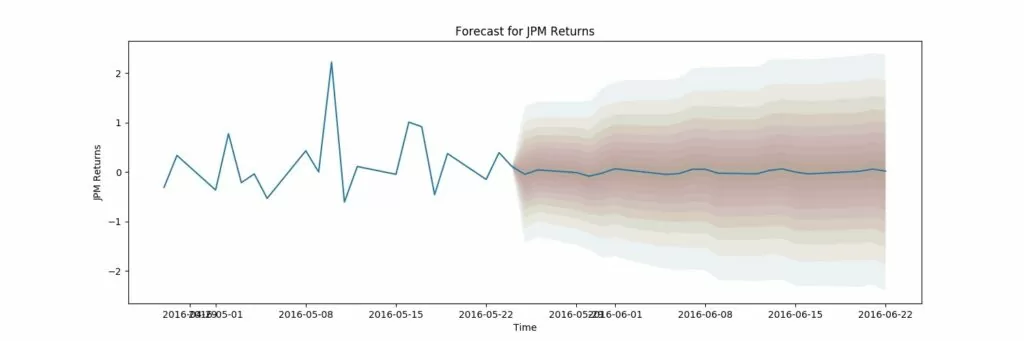
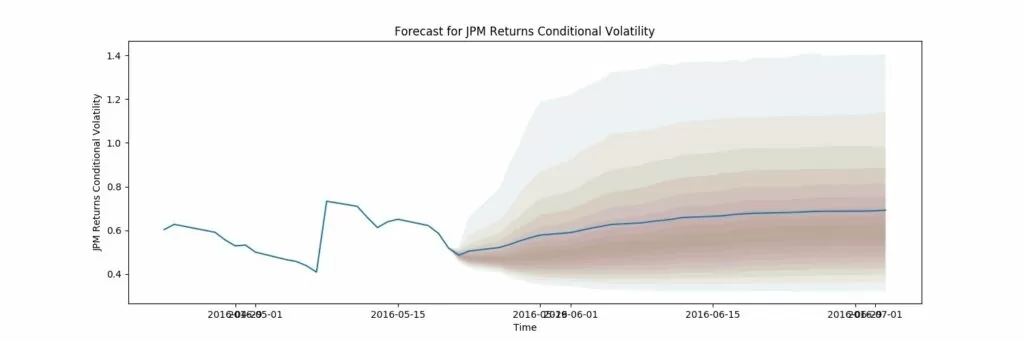
Обучение GARCH модели, вывод результатов:

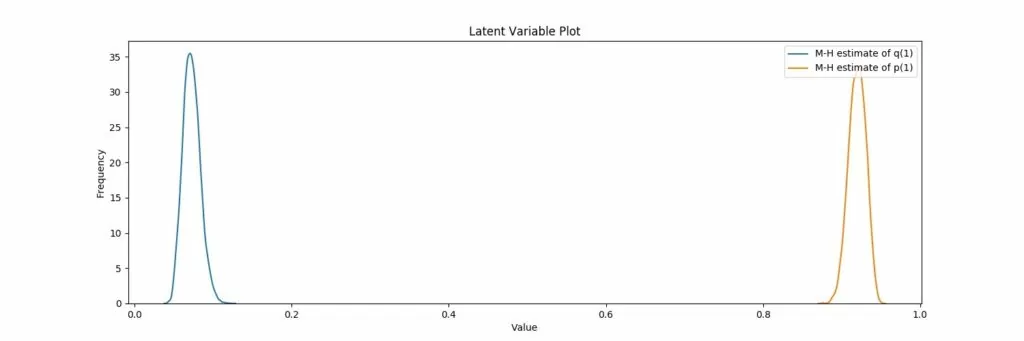
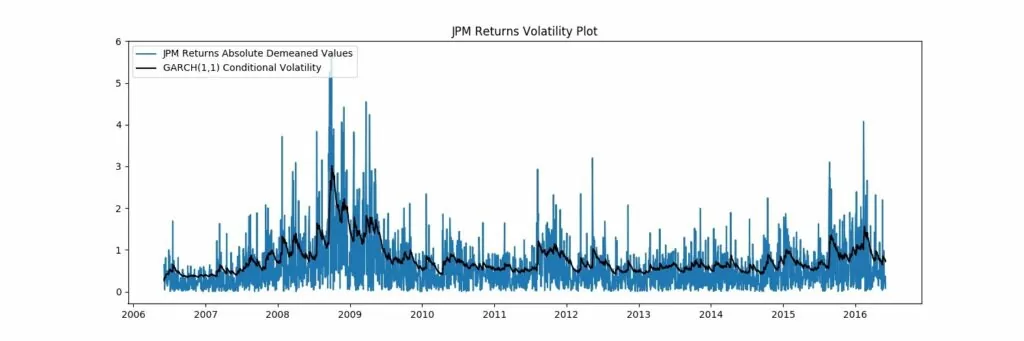
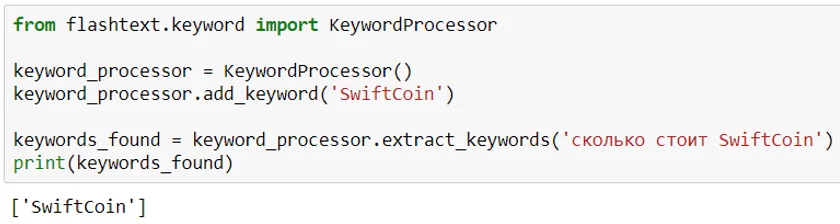
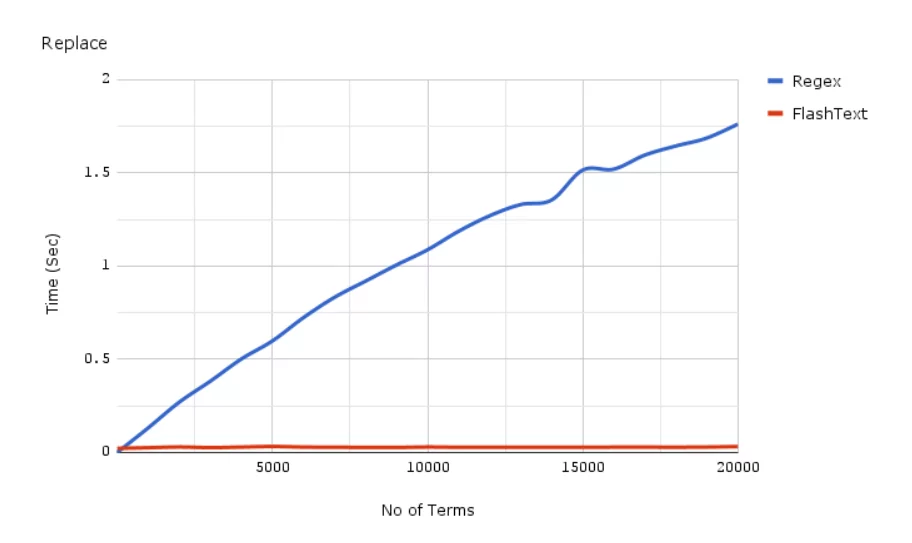
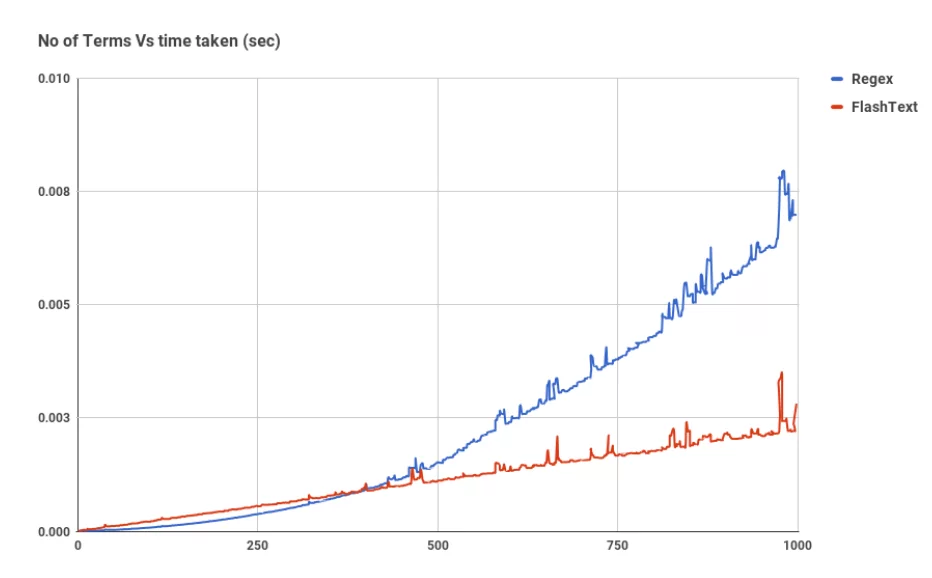
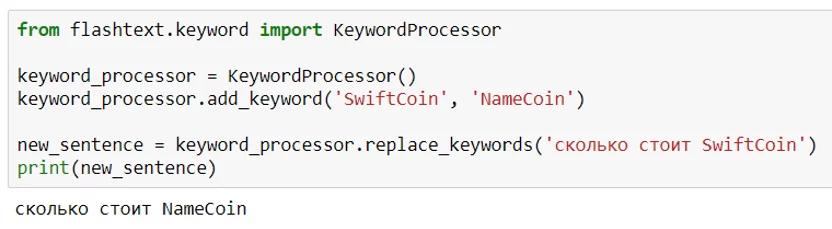
8. FlashText
Библиотека для поиска и замены слов в записях. Работает в 28 раз быстрее, чем regExp.
Пример замены слова:
Пример поиска слова: