/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Как часто вы сталкиваетесь с необходимостью выгрузить в MS Excel более миллиона строк? Все фильтры на выгрузку уже были наложены ранее, но, увы, она до сих пор «не проходит по габаритам». Перед нами встает дилемма – делить, или … воспользоваться готовыми решениями для python, не изучая python!
Речь сегодня пойдет о трех библиотеках, которые позволяют писать код и при этом не писать его, а также оперировать внушительными объемами данных с минимальными знаниями английского языка или синтаксиса пресловутых «панд» (здесь и далее «панды»: pandas – open-source библиотека для python для работы с табличными данными – прим. автора). Для примера будем использовать объявления о продаже автомобилей Toyota с известного сайта.
Первая библиотека, с которой хотелось бы Вас познакомить – Bamboolib. Не секрет, что панды питаются бамбуком, и, как за всякое пропитание, за него нужно платить. Да, у Bamboolib есть платная версия, в которой реализована поддержка Apache Spark, а также есть возможность использовать свои внутренние библиотеки и нет ограничения по плагинам, в остальном же достаточно бесплатной версии.
Устанавливаем:
pip install — upgrade bamboolib — userИмпортируем:
import bamboolib as bamРаботаем:
bamПосле этого появляется графический интерфейс и возможность открыть .csv файл…

… и работать с ним через GUI, как с обычным Excel. Считанная таблица:
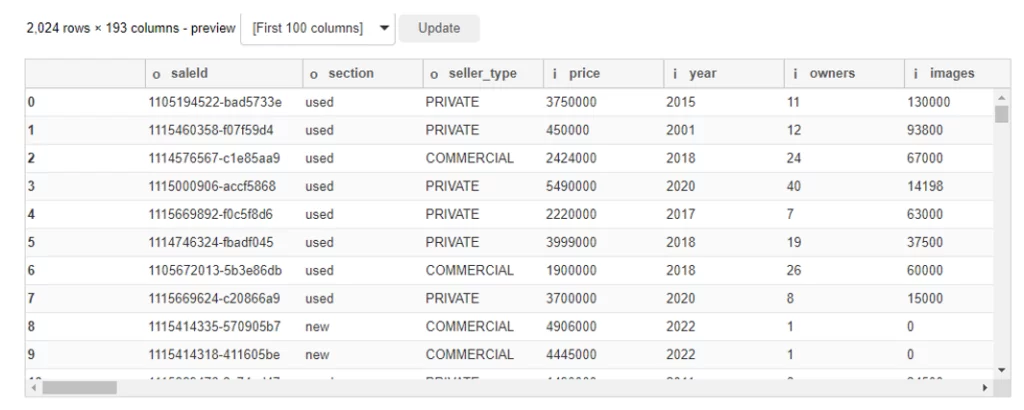
Обратите внимание:
- таблица имеет категориальные признаки оснащения автомобиля – «допы» вынесены в колонки, из-за чего фрейм «раздут» до 193 (!) столбцов. В обычном случае таблица не поместилась бы в стандартный вывод тетради и нам бы пришлось использовать параметр display.max_columns, чтобы посмотреть на все поля, но здесь полоса прокрутки уже есть.
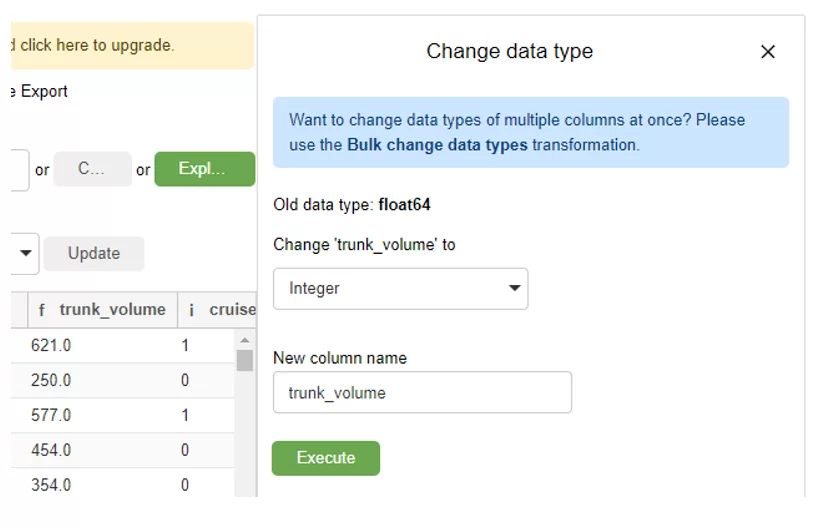
- Названия столбцов содержат префикс, на скриншоте видны «o» и «I» — так нам сообщают, что типы данных в столбцах это object и int соответственно. Долгота, широта, расход топлива и объем топливного бака «f» – float. Объем бака при этом не имеет отличных от 0 значений после точки и его можно конвертировать в int просто кликнув по столбцу, выбрав из выпадающего списка целочисленный тип и нажав Execute.
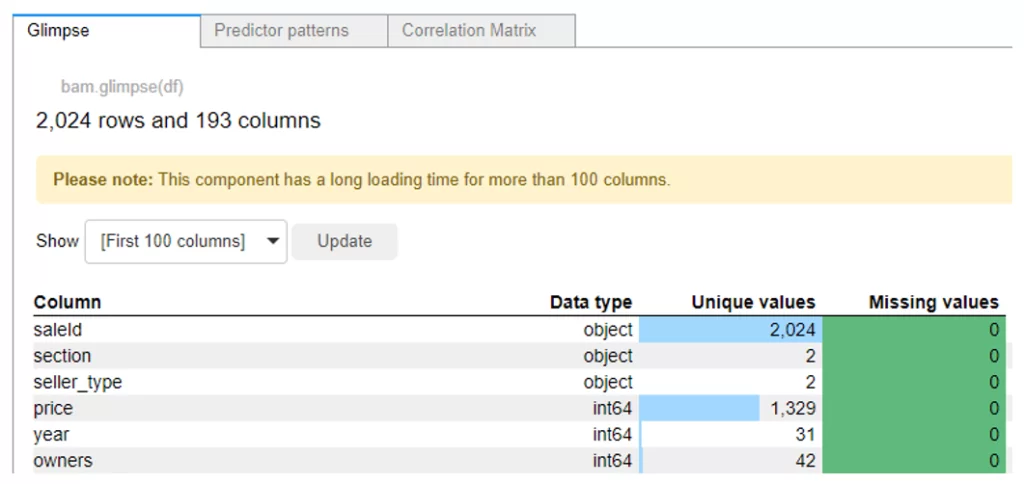
Большая зеленая кнопка «Explore DataFrame» позволит нам увидеть как типы данных всех остальных столбцов, так и количество пропусков и уникальных значений, а в соседних вкладках обнаруживаются тепловая карта и матрица корреляций.
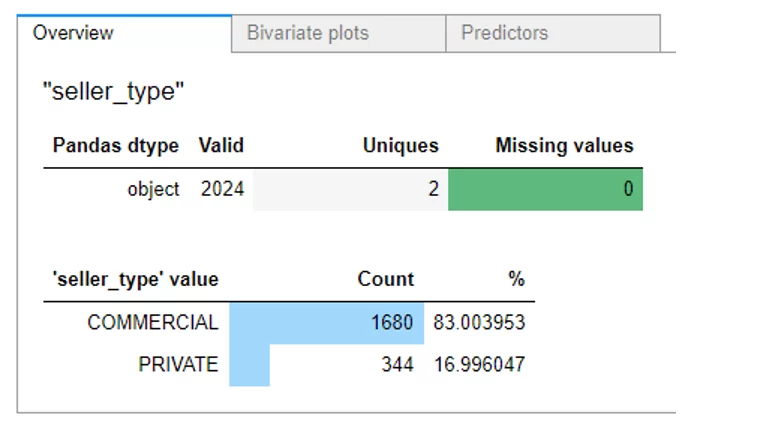
Если необходимо детально познакомиться со статистиками содержимого в столбце Seller_type, проваливаемся в него одним кликом и видим распределение, а в соседних вкладках взаимозависимости.
Слева от большой зеленой кнопки «Explore DataFrame» есть функция построения графиков. Я захотел узнать объявлений о продаже каких моделей больше всего:
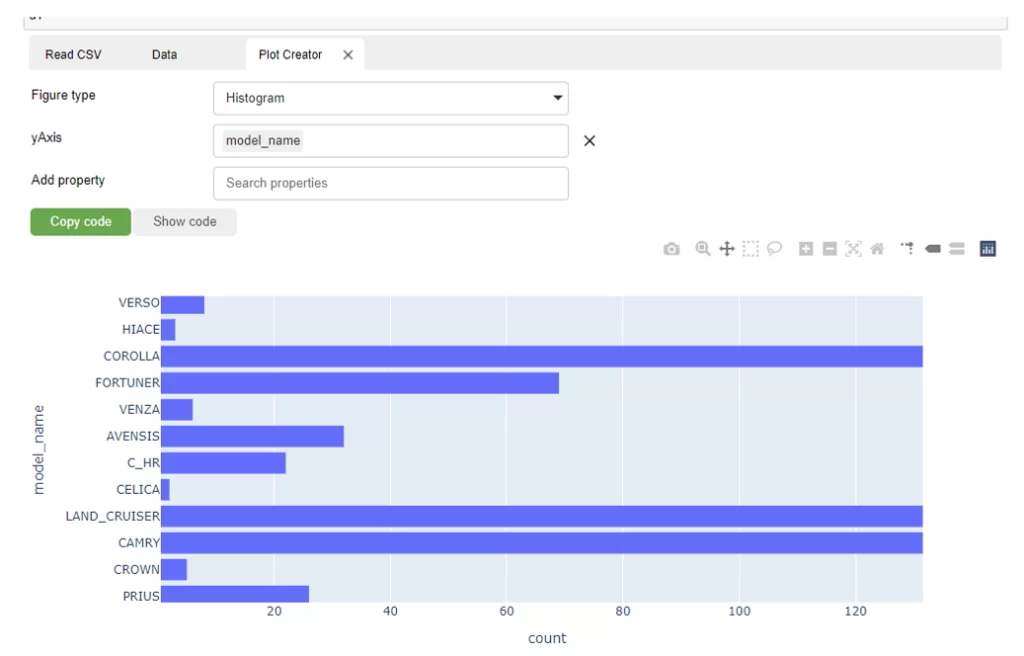
Визуализация с помощью plotly и ее контекстное меню справа в углу графика позволяют работать с графиком.
Разумеется, помимо EDA и визуализации в библиотеке есть и методы для работы с датафреймом. Если Вы знакомы с «пандами», то вас встретит привычный набор методов и функций, если же нет – достаточно будет начальных знаний английского языка – все доступные операции перечислены в выпадающем списке:
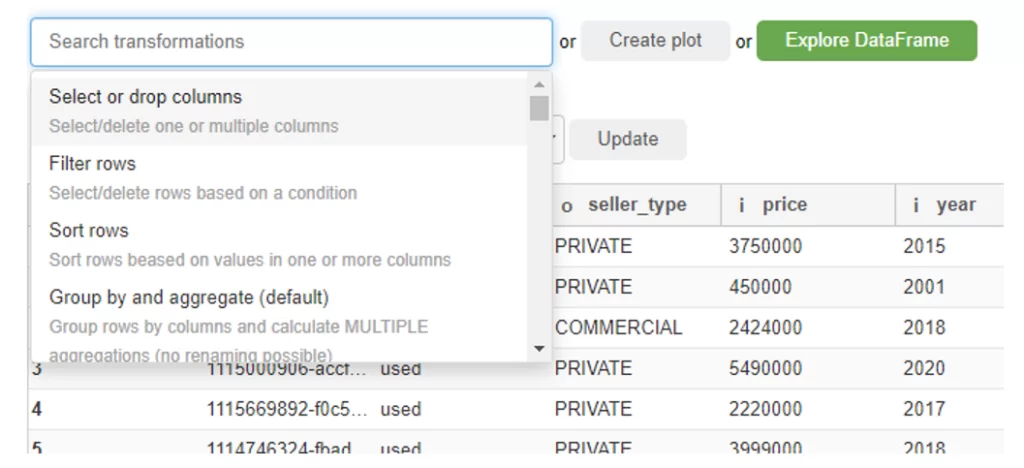
Удаление, переименование, сортировка, etc. При этом интерфейс фильтрации напоминает тот самый сайт-источник. Например, мы хотим просмотреть все объявления о продаже 5-дверных полноприводных Toyota в Самаре? Пожалуйста. Отсортировать по цене? Ничего проще 🙂 Удалить столбцы? Сию минуту 🙂
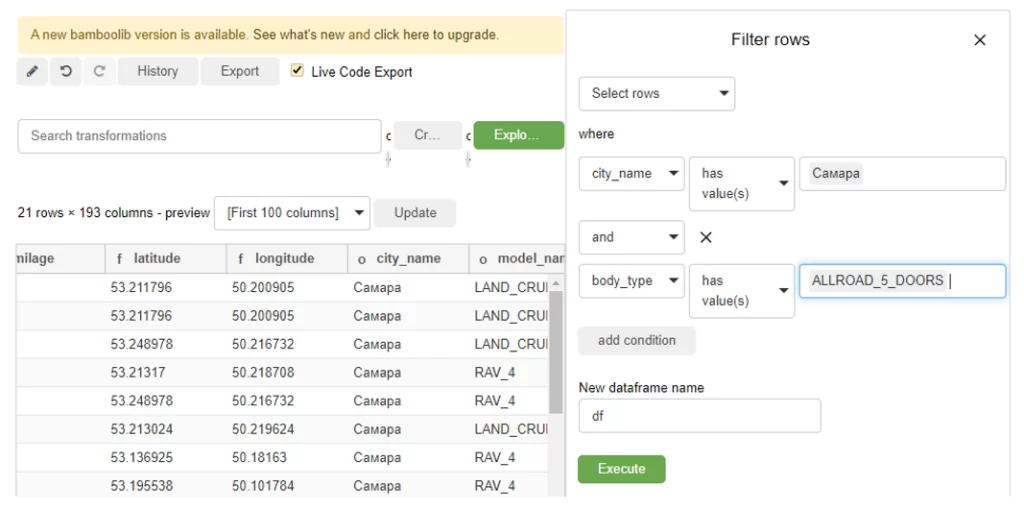
Также бывает полезна группировка, это делается достаточно просто, а в дополнение мы получаем код, который библиотека написала за нас (включая импорт «панд») – его можно сохранить и использовать в том числе и без установленной bamboolib!
import pandas as pd
df = pd.read_csv(r'C:\Users\olegs\Desktop\vato_ru.csv', sep=',', decimal='.')
df = df.loc[(df['city_name'].isin(['Самара'])) & (df['body_type'].isin(['ALLROAD_5_DOORS']))]
df = df.sort_values(by=['price'], ascending=[True])
df = df.drop(columns=['latitude', 'longitude'])
df
Как видим, «из коробки» нам предоставляется необходимый базовый набор операций с данными, включая такие вещи, как статистики и графики.
Аналогичным образом работает и библиотека Mito. Устанавливаем:
python -m pip install mitoinstaller
python -m mitoinstaller install
Импортируем:
import mitosheetРаботаем:
mitosheet.sheet()Как и у Bamboolib, у Mito есть корпоративная версия, PRO с дополнительным функционалом и бесплатная Open Source. Будем использовать последнюю, в которой помимо инструментов для исследования и трансформирования данных заявлена даже поддержка пользователей (ее не было в бесплатной версии Bamboolib).
После открытия GUI сразу же бросается в глаза различие в интерфейсе – команды выведены в «шапку», а также присутствует pivot table – сводные таблицы – и команды Undo и Redo (откатить/вернуть действие) и даже STEP HISTORY, которых не было в предыдущей библиотеке. Возможности группировки нет.
Наш датафрейм:
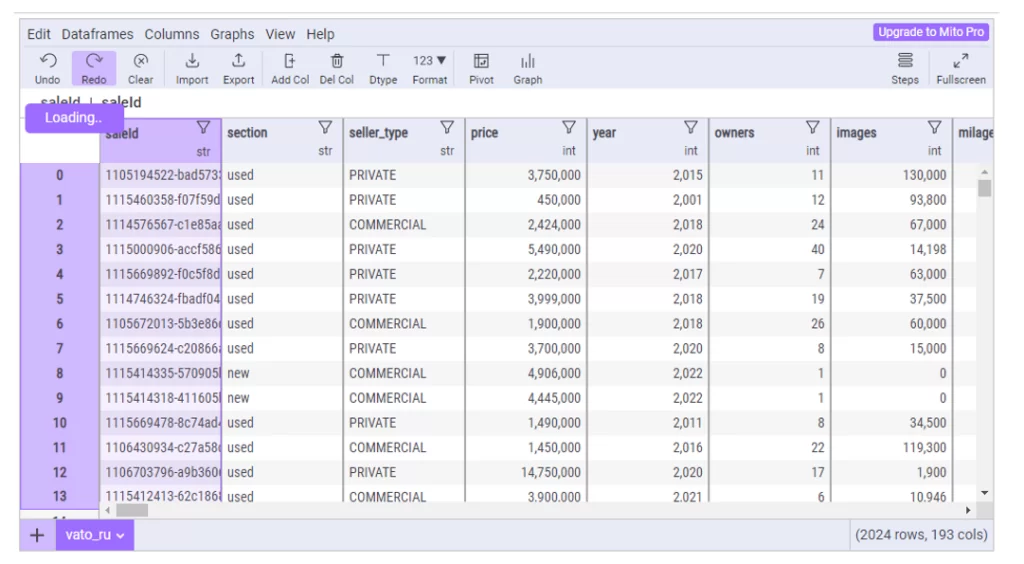
Полосы прокрутки на месте, в отличие от размерности. Изменить тип данных столбца (наименования которых здесь, кстати, отличаются) так же интуитивно просто – повторим те же манипуляции с фильтрацией, удалением колонок и т.д. и сравним код:
# Imported vato_ru.csv
import pandas as pd
vato_ru = pd.read_csv(r'C:\Users\olegs\Desktop\vato_ru.csv')
# Changed trunk_volume to dtype int
vato_ru['trunk_volume'] = vato_ru['trunk_volume'].fillna(0).astype('int')
# Filtered city_name
vato_ru = vato_ru[vato_ru['city_name'] == 'Самара']
# Sorted price in ascending order
vato_ru = vato_ru.sort_values(by='price', ascending=True, na_position='first')
# Filtered body_type
vato_ru = vato_ru[vato_ru['body_type'] == 'ALLROAD_5_DOORS']
# Deleted columns latitude
vato_ru.drop(['latitude'], axis=1, inplace=True)
# Deleted columns longitude
vato_ru.drop(['longitude'], axis=1, inplace=True)
С каждой манипуляцией фрейм так же перезаписывался (кроме удаления столбцов, но использован параметр inplace = True), а в случае необходимости отката нас спасает STEP HISTORY. Также среди незначительных отличий использование точного соответствия вместо .isin() при фильтрации (выпадающего списка, как в bamboolib, здесь нет) и ряд других, вдобавок каждое действие закомментировано.
Статистика менее подробная, но must have атрибуты присутствуют:
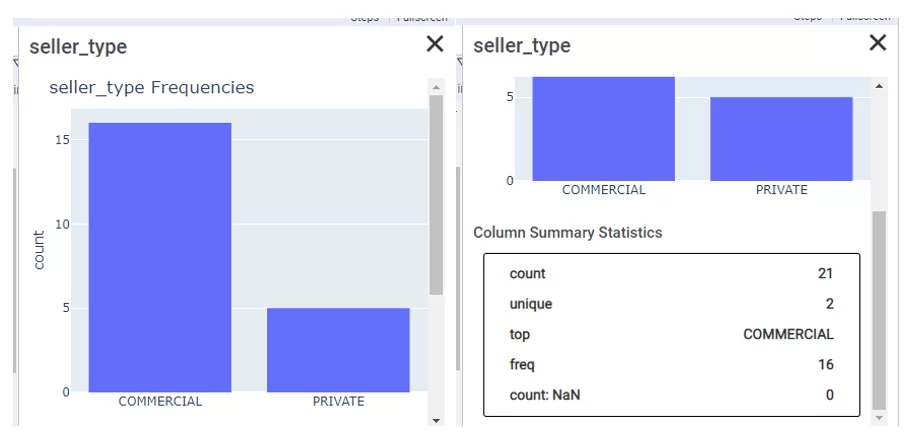
Корреляция/ковариация отсутствует. Функционал блока визуализации (также на plotly) достаточный.
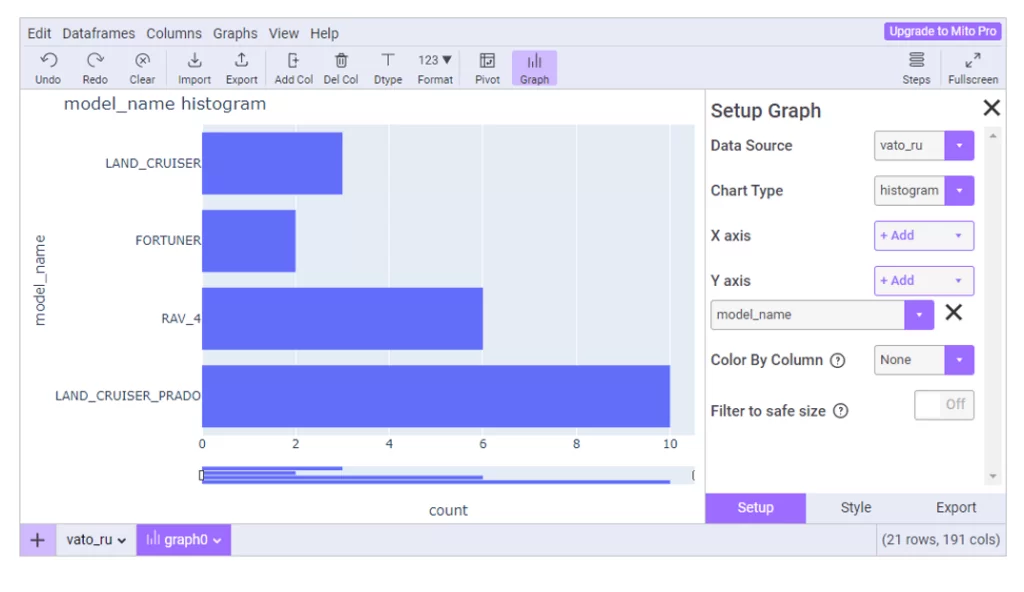
К плюсам можно также отнести то, что можно подгрузить несколько датафреймов, и они будут отображаться вкладками, как листы Excel.
Третья библиотека, которая предоставляет возможность интерактивного взаимодействия с данными на языке Python без знания языка Python — D-Tale. Она бесплатная.
Устанавливаем:
pip install dtaleИмпортируем:
import dtale
import pandas as pd
Работаем:
df = pd.read_csv(‘data.csv’)
d = dtale.show(df)
d.open_browser()
Да, нам действительно пришлось самим импортировать «панд», считать файл и даже вызвать пару функций из dtale, что, по сравнению с функционалом предыдущих библиотек, может показаться непростительно трудозатратным, но:
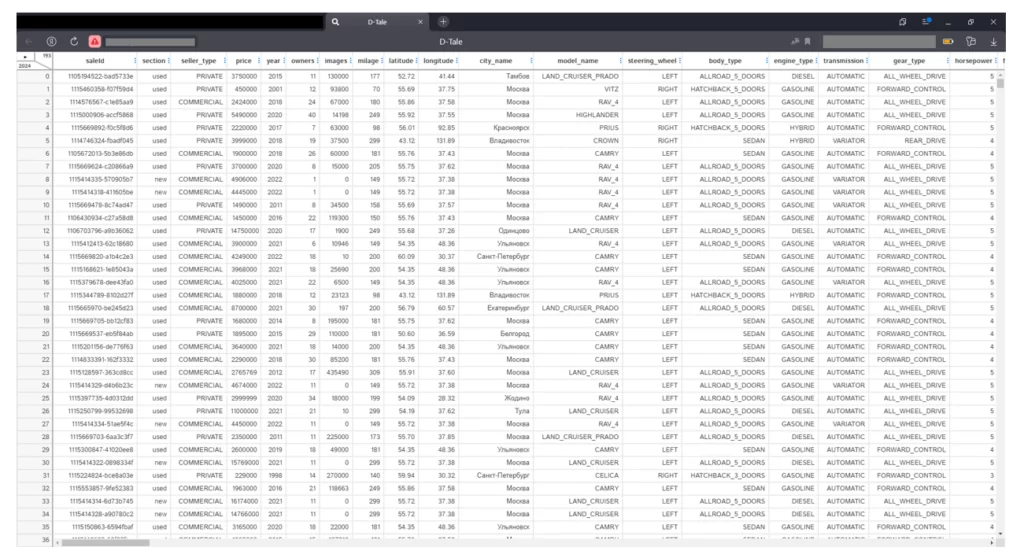
…фрейм сразу открывается в отдельном окне! Также сразу видим его размерность слева сверху и полосы прокрутки, но ни одной кнопки или тулбара. Все спрятано на кнопке в левом верхнем углу, при нажатии на которую открывается богатое меню функций – тепловая карта, корреляции, анализ пропусков, подсвечивание выбросов, графики, можно даже поставить темную тему. Сравните, как выглядят статистики (меню Describe) по столбцу «Тип продавца»:
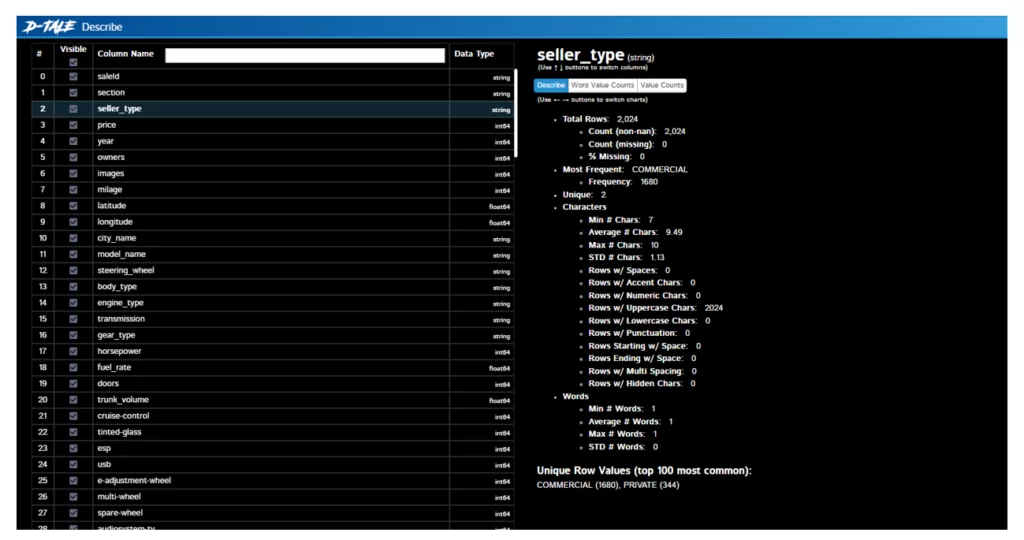
Соседняя вкладка с распределением значений:
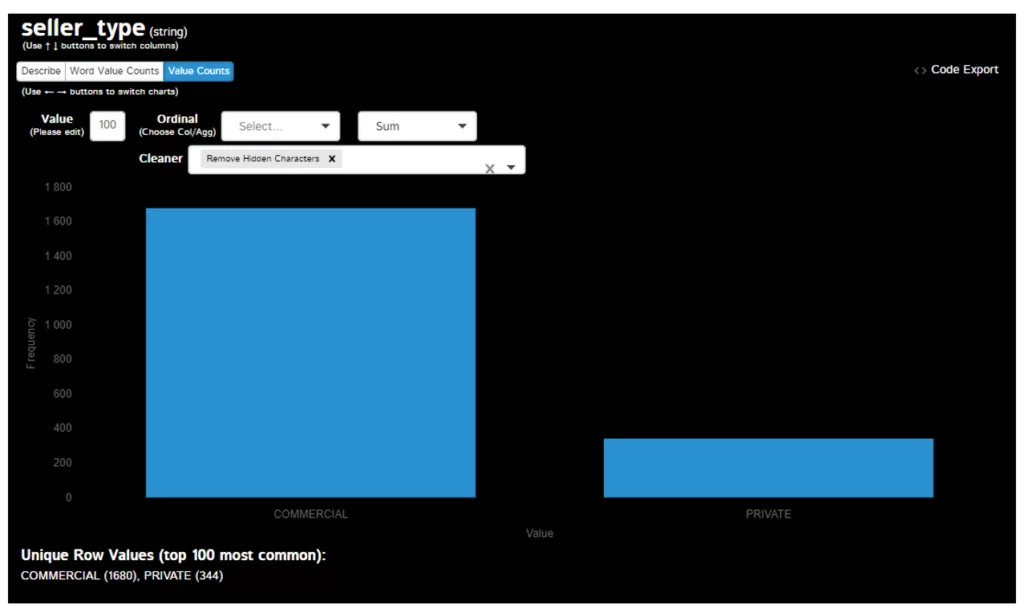
Функционал действительно впечатляет, из ранее упомянутых функций присутствуют не только pivot table и group by, но и transpose и resample:
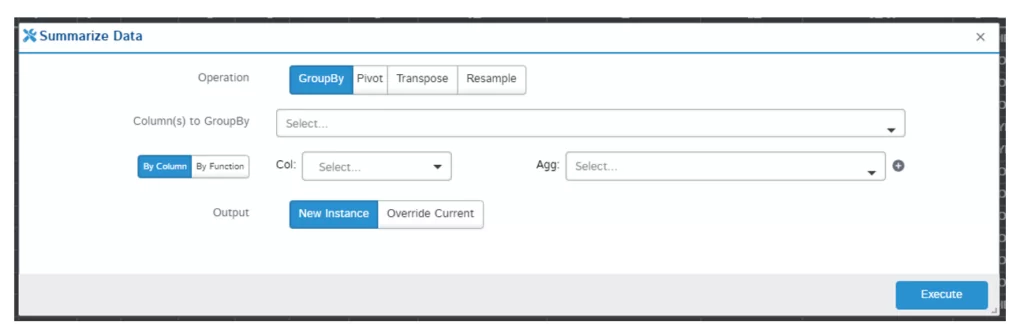
Множество поддерживаемых функций влечет за собой очевидное неудобство – для простейшей конвертации типа данных столбца необходимо сначала ее найти:
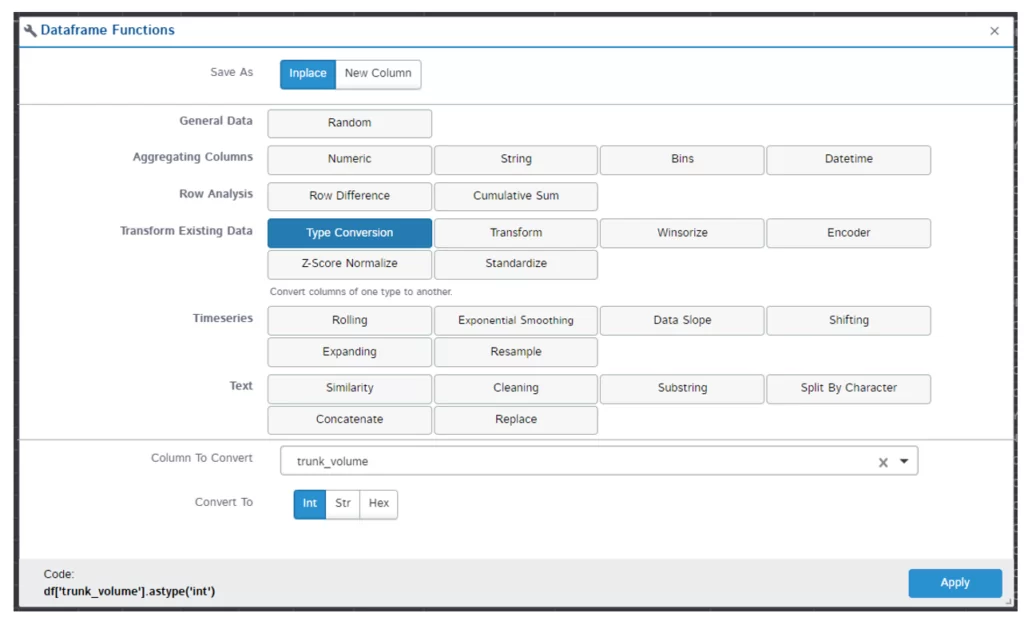
…а для фильтрации знать немного синтаксиса:
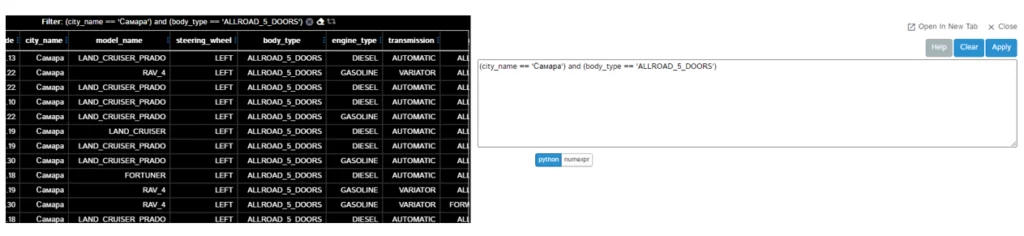
Я не буду подробно демонстрировать работу всех имеющихся функций, но проведу «традиционную» манипуляцию с датафреймом и выгружу получившийся код для сравнения:
df.loc[:, 'trunk_volume'] = pd.Series(s.astype('int'), name='trunk_volume', index=df['trunk_volume'].index)
df = df[[c for c in df.columns if c not in ['latitude']]]
df = df[[c for c in df.columns if c not in ['longitude']]]
df = df.query("""(city_name == 'Самара') and (body_type == 'ALLROAD_5_DOORS')""")
df = df.sort_values(['price'], ascending=[True])
Обратите внимание, что удаление столбцов происходит с использованием спискового включения, конвертация через Series, а для фильтрации используется функция .query(), что разительно отличает такой подход от ранее увиденных.
Как итог, с уверенностью можно утверждать, что на поле пользовательских интерфейсов для взаимодействия с данными есть инструменты, не требующие изучения языка программирования, но предоставляющие базовый, а иногда даже и расширенный арсенал для работы с таблицами. И арсенал этот достаточно велик для того, чтобы каждый нашел для себя библиотеку по потребностям – с user-friendly интерфейсом или упором на функциональность.