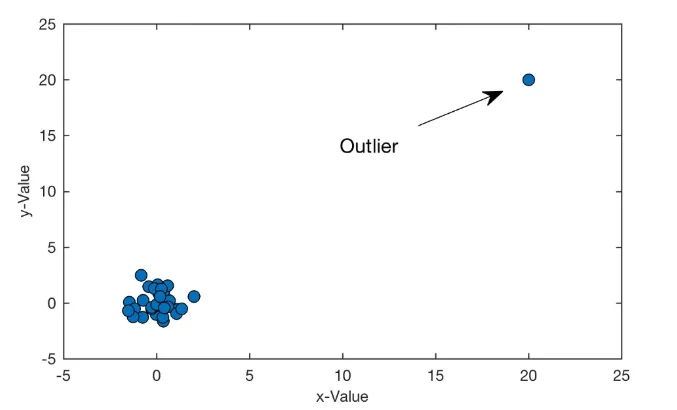
24.02.2022, Мушта Вячеслав, г. Ростов-на-дону Обнаружение новизны изображений с помощью Python и библиотеки scikit-learn
В статье расскажу, как с помощью библиотек scikit-learn, opencv, numpy, imutilsс выявить новизну входных изображений. Многие программы требуют наличия возможности решить, принадлежит ли новый объект тому же распределению, что и существующие объекты (это промежуточный результат), или его следует рассматривать как новизну. Часто эта возможность используется для очистки реальных наборов данных.
/img/star (2).png.webp)
/img/news (2).png.webp)










/img/event.png.webp)