/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 10 мин.
При работе с постоянно растущим потоком данных, довольно часто возникает необходимость проверить, не появляются ли какие-либо аномалии, будь то фродовые мошеннические операции или произвольно возникающие ошибки из-за периодически напоминающих о себе багов внутри самой инфраструктуры или, как это часто бывает, человеческого фактора. Большинство перечисленных событий не являются статистически частыми, что вносит их в рамки редких, даже аномальных, и которые необходимо как-то фиксировать и устранять.
Я хочу поделиться способом решения задач классификации, а именно поиска аномалий, при помощи неприспособленного, на первый взгляд, для этого инструмента — автоэнкодера.
Для начала необходимо поставить задачу, обозначить граничные условия, которые характеризуют её. В качестве базы был взят датасет под названием: “Dataset: Rare Event Classification in Multivariate Time Series (ссылка)”, типом решаемой задачи будет обучение без учителя, неизвестно заранее, где находятся аномалии. Датасет является многомерным временным рядом, в котором по времени записываются несколько потоков данных. Такой тип данных часто встречается в производственных процессах, в которых несколько датчиков собирают данные во времени, таким образом, одному моменту времени соответствует несколько значений от разных датчиков. В упомянутом источнике представлены данные с работы сенсоров на заводе, связанном с целлюлозно-бумажной промышленностью, где ключевым событием для поиска является обрыв бумаги, что приводит к финансовым убыткам на производстве. Такое событие является достаточно редким, и в данных на 18399 строк происходит всего 124 раза, то есть в 0,6% случаев, что характеризует датасет как достаточно несбалансированный.
Способом решения такой задачи мной выбран определенный тип архитектур, а именно автоэнкодер.
Напомню, автоэнкодер (autoencoder) — это тип искусственной нейронной сети, используемый для эффективного воссоздания входного сигнала на выходе, путем кодирования входа в минимальное по размеру представление, используя входящие в его архитектуру энкодер — для сжатия и декодер — для “разжатия”.
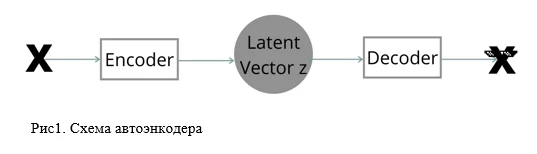
Чаще всего подобный тип нейросетей применяется для создания эмбеддингов, удаления шумов, понижения размерности и в областях генерации картинок.
Принципом работы в текущей постановке будет то, что автоэнкодер выучит распределение данных, которое ему дать, то есть, создаст единое скрытое представление того явления, которое пойдет на вход. В данном случае на вход нейросети отправится тонна временных рядов, которые не связаны с целевым событием (имеют лейбл 0, на практике подаются те неразмеченные данные, в которых уверены, что аномалий нет), то есть не связаны с надрывом бумажного полотна. В результате появится нейросеть, что без ошибок воссоздает не аномальные сессии и, одновременно с этим, имеет сложности в примерах, где нужно восстановить данные с какими-то отклонениями. Наличие высокого значения функции ошибки при восстановлении будет играть роль маркера для входных данных, указывая на аномалии.
Прежде чем пускаться в нейронные сети, продемонстрирую загрузку данных и то, какая часть из них понадобится. Какой-то особенной предобработки или фичаэкстрактинга не будет. Для демонстрации достаточно тех данных, что представлены (весь код можно найти по ссылке).
#загрузка данных
df = pd.read_csv('processminer-rare-event-mts - data.csv')
#убираем категорильные данные и данные о времени
df = df.drop(['time', 'x28', 'x61'], axis=1)
#разделение на трэин и валдиацию
x_train, x_val = train_test_split(df, train_size=0.7, shuffle=True)
#оставляем у трэина только значения с нормальными сессиями
x_train1 = x_train[x_train.y == 0].drop(['y'], axis=1)
#оставляем у валидации также значения с нормальными сессиями
x_val1 = x_val[x_val.y == 0].drop(['y'], axis=1)
#создаем валидацию для теста, в данном примере тестовыми данными
#будут служить данные с валидации, обогащенные целевыми примерами
x_test1 = x_val.drop(['y'], axis=1)
y_test1 = x_val.y
#стандартизация
x_train11 = StandardScaler().fit_transform(x_train1)
x_val11 = StandardScaler().fit_transform(x_val1)
x_test11 = StandardScaler().fit_transform(x_test1)
#перевод в тензора для работы с библиотекой torch
x_train11 = torch.FloatTensor(np.array(x_train11)).reshape(-1, 1, x_train11.shape[1])
x_val11 = torch.FloatTensor(np.array(x_val11)).reshape(-1, 1, x_val11.shape[1])
x_test11 = torch.FloatTensor(np.array(x_test11)).reshape(-1, 1, x_test11.shape[1])
#создание загрузчики в нейросеть
train_loader = torch.utils.data.DataLoader(x_train11, batch_size=2048)
val_loader = torch.utils.data.DataLoader(x_val11, batch_size=2048)
test_loader = torch.utils.data.DataLoader(x_test11, batch_size=1, shuffle=False)
Далее продемонстрирую три несложные имплементации различных вариантов АЕ, для которых не требуются размеченные данные, а именно: глубокий, сверточный и вариационный автоэнкодеры.
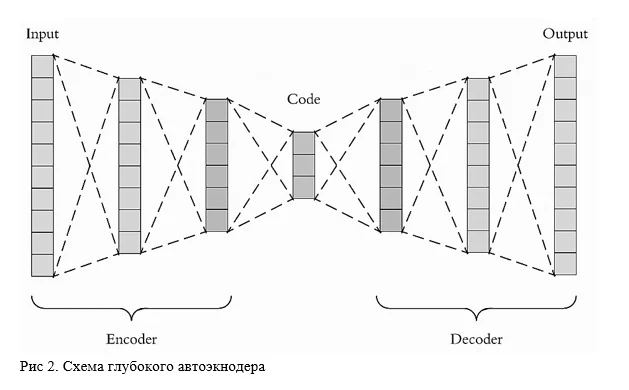
Начну с одного из самых простых — обычного глубокого автоэнкодера, представляющего из себя, часто зеркальные, энкодер и декодер, с более чем 2-мя полносвязными слоями и функциями активации. Схема на рисунке 2.
Пример класса, описывающего архитектуру:
class LinearAE(nn.Module):
def __init__(self):
super(LinearAE, self).__init__()
self.flatten = nn.Flatten()
# encoder
self.encoder = nn.Sequential(
nn.Linear(in_features=61, out_features=32),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.Linear(in_features=32, out_features=2)
)
# decoder
self.decoder = nn.Sequential(
nn.Linear(in_features=2, out_features=32),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.Linear(in_features=32, out_features=61)
)
def forward(self, x):
x = self.flatten(x).float()
latent_space = self.encoder(x)
reconstruction = self.decoder(latent_space)
return reconstruction
Код для тренировки нейронной сети с использованием torch, можно увидеть по ссылке выше. Там классический вариант для автоэнкодера, без каких-то замороченных деталей. Дальнейший инференс обученной модели выглядит следующим образом:
#получаем лосс по каждому временному ряду в валидационной части датасета
# там где лосс большой, там и аномальные данные
test_losses = []
with torch.no_grad():
for batch in tqdm(test_loader):
pred = model(batch.to(device)).cpu().numpy()
mae = np.mean(np.abs(pred - batch.numpy()))
# mse = mean_squared_error(pred.reshape(61), batch.numpy().reshape(61))
test_losses.append(mae)Но что такое большой лосс? Как найти эту границу, после которой идут аномальные данные? Определить ошибку можно способом выстраивания 99-999% перцентилей от полученного списка ошибок, или наглядно, построив график распределения ошибок и точечную диаграмму, затем выбрать границу, где есть какое-то скопление значений помимо основного, например, как показано на рисунке 3.
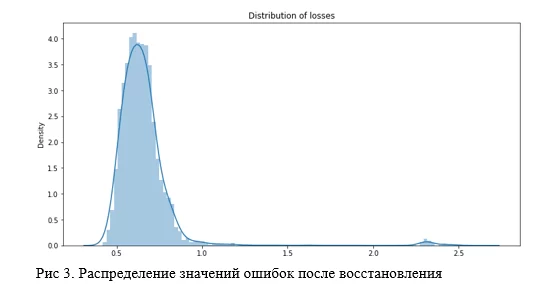
Так как значений аномальных мало, то распределение, которое нужно заметить, получается очень размазанным (на графике выше оно ещё заметно, но это может быть просто линия). В таком случае лучше подойдет точечная диаграмма, в части со сверточным автоэнкодером этот способ будет продемонстрирован наглядно.
#определение класса при заданной границе
y_pred = pd.Series(test_losses).apply(lambda x: 1 if x > pd.Series(test_losses).quantile(0.999) else 0)По итогу, стандартный автоэнкодер с 2-мя слоями с каждой стороны демонстрирует интересные результаты. Лучше всего для их характеристики подойдут confusion matrix и classification report от sklearn. В качестве полезной нагрузки напомню, что метрика ROC в данном случае абсолютно неинформативна и выдаёт качество в 99%.
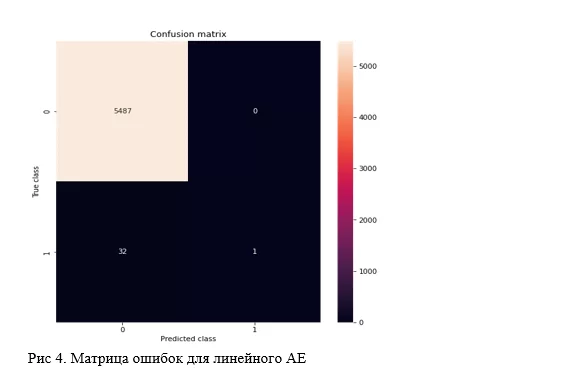
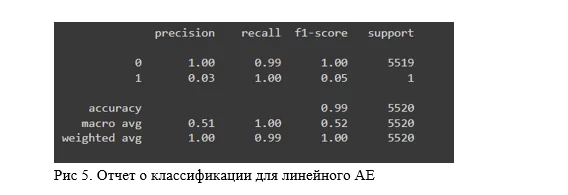
Данная версия смогла найти 1 аномалию из 33, но зато не ошиблась в определении нормальных временных рядов. Напомню, задача в данном случае детектировать 0,6% от общего объёма данных.
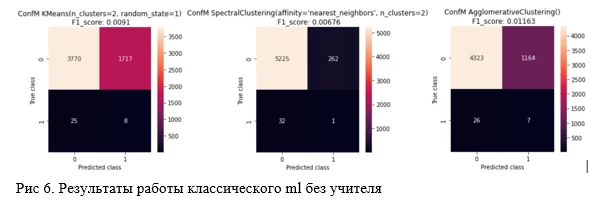
В качестве сравнения, продемонстрирую на рисунке 6 результаты использования некоторых классических алгоритмов машинного обучения без учителя, а именно KMeans, SpectraclClustering, AgglomeraticveClustering. Гиперпараметры и итоговый F1sore моделей можно наблюдать в заголовках представленных ниже матриц ошибок, и в прикрепленной ссылке.
Возвращаюсь к основной теме. Дальше была создана имплементация глубокого автоэнкодера, применяющего сверточные слои. Схема такой архитектуры показана на рисунке 7.
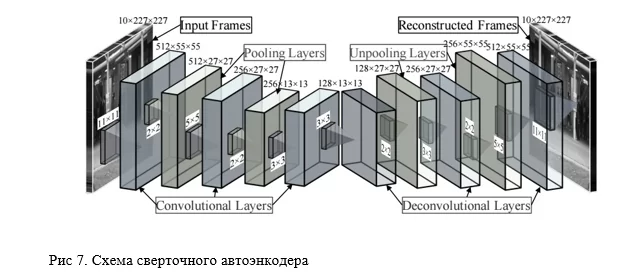
Стоит упомянуть, что в данной реализации я также использовал метод регуляризации весов dropout и функции активации leaky relu. Вариант подобной нейронной сети может выглядеть так:
class CNN_AE(torch.nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv1d(1, 32, kernel_size=7, stride=1, padding=3),
nn.LeakyReLU(),
nn.Dropout(0.2),
nn.Conv1d(32, 64, kernel_size=7, stride=1, padding=3),
nn.LeakyReLU(),
nn.Dropout(0.2),
nn.Conv1d(64, 2, kernel_size=7, stride=1, padding=3),
nn.LeakyReLU(),
)
self.decoder = nn.Sequential(
nn.ConvTranspose1d(2, 64, kernel_size=7, stride=1, padding=3),
nn.LeakyReLU(),
nn.Dropout(0.2),
nn.ConvTranspose1d(64, 32, kernel_size=7, stride=1, padding=3),
nn.LeakyReLU(),
nn.Dropout(0.2),
nn.ConvTranspose1d(32, 1, kernel_size=7, stride=1, padding=3),
)В итоге, результат получается лучше, чем у линейной структуры. Сеть определяет без ошибок 6 аномальных объектов, не называя аномальными ни одного обычного, что видно из матрицы ошибок:
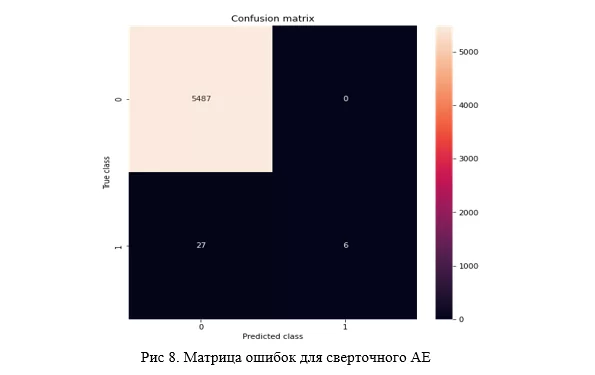
Причем, если построить точечную диаграмму по лоссам с границей в виде 999 перцентиля, то без усилий можно заметить те самые аномальные объекты:
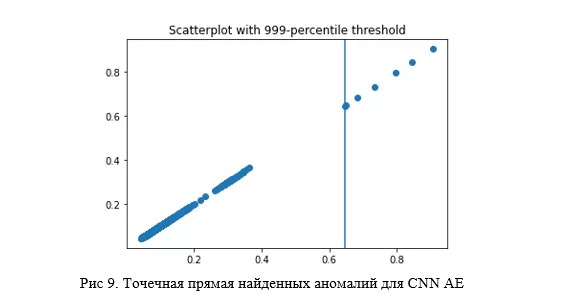
По такой диаграмме вполне оправдано судить об успешности кластеризации. Если все точки сливаются в одну линию, то явно что-то пошло не так, и это хороший повод повторить обучение алгоритма и вновь построить данную прямую.

И последним, реализуемым в этой работе видом автоэнкодера, будет его вариационная версия или просто VAE (Variational Autoencoder). Для VAE характерно не просто создание напрямую латентного пространства, а сначала моделирование его основных признаков, а именно: среднего значения и стандартного отклонения, которые соединяясь в особой функции потерь, одна часть которой отвечает за “близость” латентных представлений, а другая за качество реконструкции, уже создают нужное распределение данных, что позволяет хранить скрытые представления объектов в одной области значений. Это удобно при дальнейшем сэмплировании из него нужных объектов, особенно в случае использования варианта Conditional VAE.
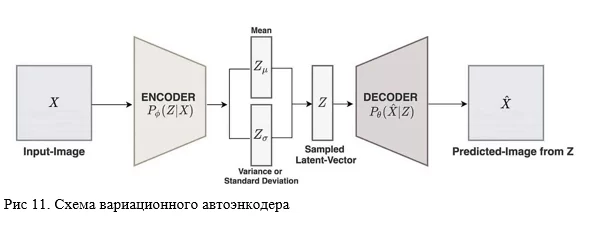
Ниже представлен класс для VAE. Функции ошибок и код тренировки можно найти по ссылке в ноутбуке.
class VAE(nn.Module):
def __init__(self):
super().__init__()
latent_dim = 4
self.encoder_1layer = nn.Linear(61, 32)
self.encoder_2layer_Mu = nn.Linear(32, latent_dim)
self.encoder_2layer_Logsigma = nn.Linear(32, latent_dim)
self.decoder_1layer = nn.Linear(latent_dim, 32)
self.decoder_2layer = nn.Linear(32, 61)
def encode(self, x):
x = self.encoder_1layer(x)
x = torch.relu(x)
mu = self.encoder_2layer_Mu(x)
mu = torch.relu(mu)
logsigma = self.encoder_2layer_Logsigma(x)
logsigma = torch.relu(logsigma)
return mu, logsigma
def forward(self, x):
#энкодер
mu, logsigma = self.encode(x)
#параметры распределения
std = torch.exp(0.5 * logsigma)
eps = torch.randn_like(std)
x1 = mu + (eps * std)
#декодер
z = self.decoder_1layer(torch.relu(x1))
z = torch.relu(z)
z = self.decoder_2layer(z)
reconstruction = torch.sigmoid(z)
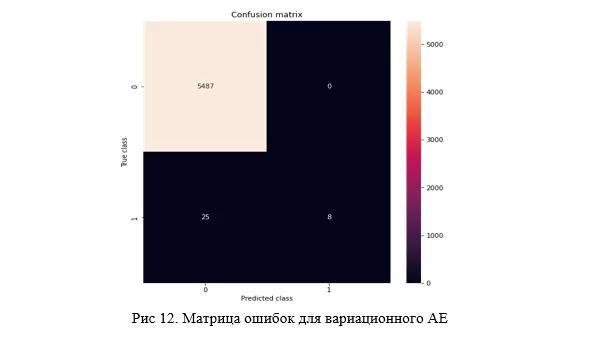
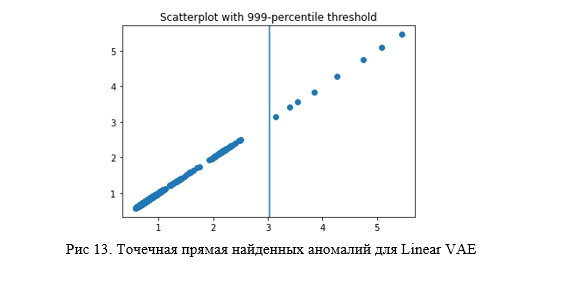
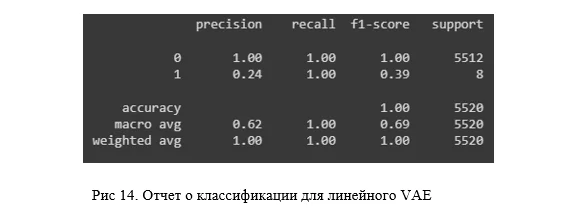
return mu, logsigma, reconstructionВ итоге результат не сильно, но превосходит первые два вида AE, а в плане простоты нахождения границы равен сверточному, что можно увидеть, как на матрице ошибок (рисунок 12), так и на точечном графике (рисунок 13).
Я пробовал использовать и другие виды, такие как: Denoising или шумоподавляющий AE, в котором искусственно зашумляются данные на вход, Sparse или разреженный AE, который представляет собой использование штрафующих коэфициентов над весами в оптимизаторе (L2), их комбинацию с VAE, но это не принесло существенных различий. В качестве вариантов дальнейшего улучшения представленных алгоритмов, вполне можно подумать над увеличением слоёв в нейронных сетях, либо использовать более современные варианты, например, автоэкнодеры с LSTM слоями или даже трансформеры, и не забыть про выделение дополнительных фич из данных. В общем, кого на что хватит)
В качестве вывода отмечу, что нейронная сеть показала себя достаточно неплохо в нетривиальной задаче без учителя по поиску аномалий с критически малым объемом ключевых значений, что характеризует её, конечно, не как панацею, но как вполне рабочий инструмент с широким кругом возможностей для модификации, который можно использовать совместно с другими алгоритмами в решении различного круга задач.
P.S. Ссылка на трактовку схемы, использованной в заголовке поста, по фильму «Разборки в стиле кунг-фу».