/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Кажется, что сегодня алгоритмы машинного обучения применяются чуть ли не в каждом втором приложении. Хотя подождите, не кажется: в наше время и правда сложно найти более или менее серьезную компанию, продукты которой полностью обходятся без нейросетей — помощников… Существуют даже интеллектуальные приложения для заметок!
На фоне всего этого очень сложно придумать что-то новое. Я очень долго думал, чего же инновационного придумать для того, чтобы все удивились. К сожалению, ничего такого в голову не пришло… Но в процессе размышлений я вспомнил, как часто в процессе написания диплома встречал сканы научных работ, которые пригодились бы в качестве источника. Жаль, что тогда я не знал про OCR — мне не пришлось бы вглядываться в текст и переписывать слово в слово нужный абзац. Но теперь знаю и расскажу вам!
Достаточно точное определение дает amazon.com на странице своего облачного сервиса AWS. Оптическое распознавание символов (OCR – Optical Character Recognition) – это процесс преобразования изображения текста в машиночитаемый текстовый формат. Например, при сканировании бланка или квитанции, компьютер сохраняет скан в виде файла изображения. Текстовый редактор невозможно использовать для редактирования, поиска или подсчета слов в файле изображения. OCR помогает преобразовать изображение в текстовый документ, содержимое которого хранится в виде текстовых данных. Технология применяется для цифровизации любых источников данных, содержащих текст — будь то автомобильный номер, паспорт, капча — что угодно.
С научной стороны все тоже довольно просто. Для создания алгоритма, способного преобразовать изображение в текст, необходимо сначала определиться с набором символов и собрать обучающую выборку. Хотите распознавать русский печатный текст или английский рукописный? Не проблема, в любом случае придется потрудиться над выбором и разметкой входных данных. Дальше — обучение модели. Для решения задач распознавания текста зачастую используют сверточные и рекуррентные нейронные сети.
На рисунке указан пример архитектуры сверточной НС, взятый из статьи на researchgate:
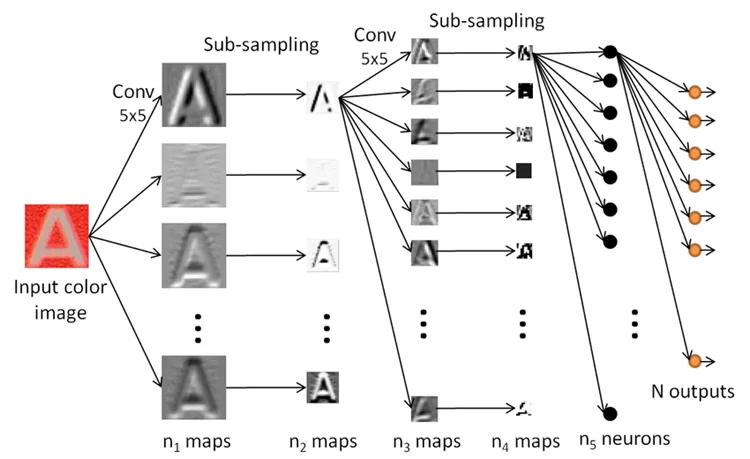
На Хабре, NTA и многих иностранных ресурсах в открытом доступе есть работы, подробно изучающие процесс обучения таких моделей и их технические аспекты.
В данной статье будет рассмотрено практическое применение этой технологии в простой и практичной оболочке телеграм-бота. Предвосхищая обвинения в плагиате, признаю: это не единственный продукт в своем роде. Есть платные и бесплатные платформы, позволяющие с разным уровнем качества и удобства преобразовать картинку в текст. Есть даже пара сомнительных неактивных ботов в телеграм. Но чего нет — так это простой и понятной инструкции по созданию своей системы. Этим и займемся.
Для решения задачи нам понадобится компьютер, который мы будем использовать в качестве сервера для приема и обработки команд и сообщений. На устройстве нужно будет установить Python и используемые модули.
Для осуществления OCR будем использовать простой и популярный Tesseract с их библиотекой для pytesseract в связке с Pillow:
pip install Pillow, pytesseractКроме pytesseract, необходимо установить саму программу и русский язык: гайд по установке.
В качестве изюминки добавим переводчик. Используем библиотеку googletrans. Эта библиотека отправляет в сервис Google Translate исходный текст и язык, на который его нужно перевести. Stable версии библиотеки иногда могут работать некорректно, рекомендую установить:
pip install googletrans==3.1.0a0Еще нам понадобится модуль langdetect для осуществления функции автоматического перевода одной кнопкой:
pip install langdetectВоспользуемся библиотекой aiogram для связи с серверами telegram и создания функционального бота:
pip install aiogramПервым шагом для создания бота является получение api-ключа от платформы. Для этого обратимся к @botfather – это бот от телеграм для создания и настройки своего бота:
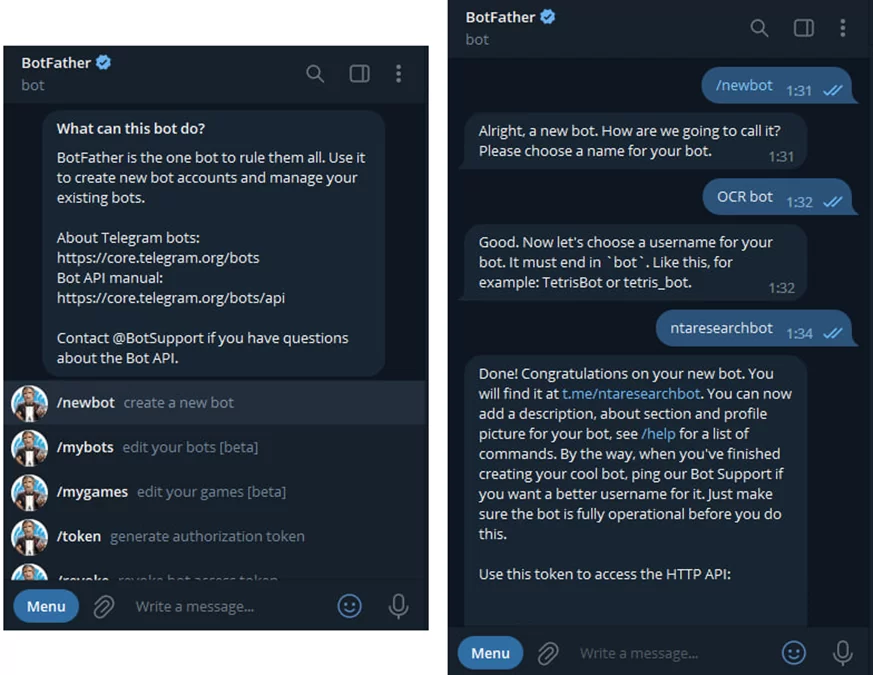
Здесь мы создали бота с именем “OCR bot”, ID “ntaresearchbot” и получили API токен для обмена информацией с серверами телеграм.
Перейдем к написанию кода. Для более глубокого понимания, рекомендую ознакомиться с данным ресурсом. В нем описаны многие из распространенных практик разработки ботов на платформе Telegram — в том числе те, что будут использованы далее.
Импортируем необходимые библиотеки, напишем код для постоянного опроса серверов телеграм. Не забудьте вставить свой API-ключ:
from aiogram import Bot, Dispatcher, executor, types
from aiogram.contrib.fsm_storage.memory import MemoryStorage
from aiogram.types.message import ContentType
bot = Bot(token='ваш токен', parse_mode=types.ParseMode.HTML)
storage = MemoryStorage()
dp = Dispatcher(bot, storage=storage)
if __name__ == '__main__':
print('Бот запущен!')
executor.start_polling(dp, skip_updates=False, timeout=100)
Получилось тело будущего бота. Теперь добавим обработчик команды “/start”. Эта команда будет служить для запуска бота:
@dp.message_handler(commands=['start'], state='*')
async def start_bot(message: types.Message, state):
uid = message.chat.id
await state.finish()
try:
await bot.send_message(uid, 'Привет! Вот доступный функционал:', reply_markup=initial_keyboard())
except Exception:
print(traceback.format_exc())
Как видно из кода обработчика команды /start, бот должен в ответ на получение команды отправить нам некое сообщение и reply_markup(). Этот reply_markup есть не что иное, как клавиатура для взаимодействия с ботом. Вставим функцию для создания клавиатуры перед обработчиком команд:
def initial_keyboard():
keyboard_markup = types.InlineKeyboardMarkup(row_width=1, resize_keyboard=True)
keyboard_markup.insert(types.InlineKeyboardButton(text='Распознать 🇷🇺 текст', callback_data=f'ocr_rus'))
keyboard_markup.insert(types.InlineKeyboardButton(text='Распознать 🇬🇧 текст', callback_data=f'ocr_eng'))
keyboard_markup.insert(types.InlineKeyboardButton(text='Переводчик', callback_data=f'translate'))
return keyboard_markup
В эту клавиатуру мы добавили 3 кнопки: ‘Распознать 🇷🇺 текст’, ‘Распознать 🇬🇧 текст’, ‘Переводчик’. Так это выглядит в боте:
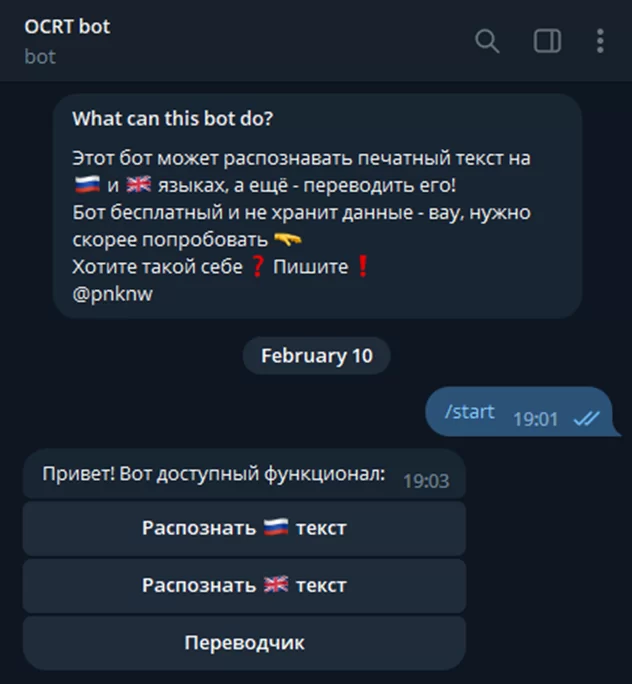
Красивые кнопки, еще и с эмодзи, ух! Но их нажатие сейчас ни к чему не приведет. Чтобы это исправить, необходим обработчик кнопок. Сначала посмотрите на код для создания клавиатуры – там у каждой кнопки есть своя callback_data. Это строка содержит информацию, которую мы можем использовать для создания новых обработчиков. Как /start, только немного по-другому:
@dp.callback_query_handler(lambda cb: cb.data.split('_')[0] == 'ocr')
async def pre_ocr(callback_query: types.callback_query):
cb = callback_query
uid = cb.from_user.id
try:
flag, flag_index = await getFlagIndex(cb.data.split('_')[1])
if flag_index == 0:
await lang.rusl.set()
else:
await lang.engl.set()
await bot.send_message(uid, f'Отправьте изображение с {flag} текстом...')
except Exception:
print(traceback.format_exc())
await bot.send_message(uid, 'Что-то пошло не так...', reply_markup=initial_keyboard())
Это обработчик нажатия кнопки, в callback_data которой есть строка ‘ocr’. Кроме этой строки, там содержится еще и информация о необходимом языке, на котором будет распознаваться текст. Для определения языка и его отображения, используем функцию getFlagIndex:
async def getFlagIndex(region):
flag = "🇷🇺" if region == "rus" else "🇬🇧"
flagindex = flags[region]
return flag, flagindex
Как вы можете заметить, в коде обработчика нет вызова клавиатуры. Но данные все еще нужно передать. Для этого воспользуемся «машиной состояний». Она поможет нам установить необходимые условия, чтобы следующий обработчик, проверив состояние, понял, что от него требуется. Более подробно о «машине состояний» и ее использовании написано в документации aiogram. Создадим ее, добавив следующий программный код перед обработчиками:
from aiogram.dispatcher.filters.state import State, StatesGroup
class lang(StatesGroup):
rusl = State()
engl = State()
transt = State()
В нашей «машине состояний» есть три состояния: русский язык, английский язык и переводчик.
Теперь, после нажатия кнопки «Распознать ru текст», состояние бота сменится с None на ‘lang:rusl’, а интерфейс нашего бота будет выглядеть так:
Теперь добавим обработчик изображений, учитывающий состояния для того, чтобы бот мог принять и преобразовать картинку в текст:
@dp.message_handler(content_types=ContentType.PHOTO, state=lang.rusl)
@dp.message_handler(content_types=ContentType.PHOTO, state=lang.engl)
async def handle_ocr_image(message, state):
uid = message.chat.id
current_state = await state.get_state()
try:
await bot.send_message(uid, f'Изображение обрабатывается...')
await message.photo[-1].download(destination_file=f'{uid}_photo.jpg')
if current_state == 'lang:rusl':
ocr_result = await processImage(uid, 'rus', curdir)
else:
ocr_result = await processImage(uid, 'eng', curdir)
await bot.send_message(uid, f'Готово! {ocr_result}', parse_mode='Markdown')
await state.finish()
await bot.send_message(uid, 'Доступный функционал:', reply_markup=initial_keyboard())
except Exception:
print(traceback.format_exc())
await bot.send_message(uid, 'Что-то пошло не так...', reply_markup=initial_keyboard())
Как видно из кода, обработчик сработает в случае отправки контента (только фотографий), вместе с условием, что состояние либо ‘lang:rusl’, либо ‘lang:engl’. Кстати, не забывайте про сброс состояний, иначе следующий обработчик, который не принимает состояния, может не сработать – сделайте await state.finish(). Еще в коде есть асинхронная функция processImage(). Она служит для преобразования изображений в текст, и для ее работы нам понадобится импортировать библиотеки pytesseract, pathlib и PIL:
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
from pathlib import Path
from PIL import Image
async def processImage(uid, lang, dir):
text = pytesseract.image_to_string(Image.open(f'{uid}_photo.jpg'), lang=lang)
Path(f'{dir}/userpic/{uid}_photo.jpg').unlink() # удаление картинки
return text
Теперь можно отправлять боту картинку. В ответ вернется текст с картинки, после чего бот предложит воспользоваться функцией распознавания заново:
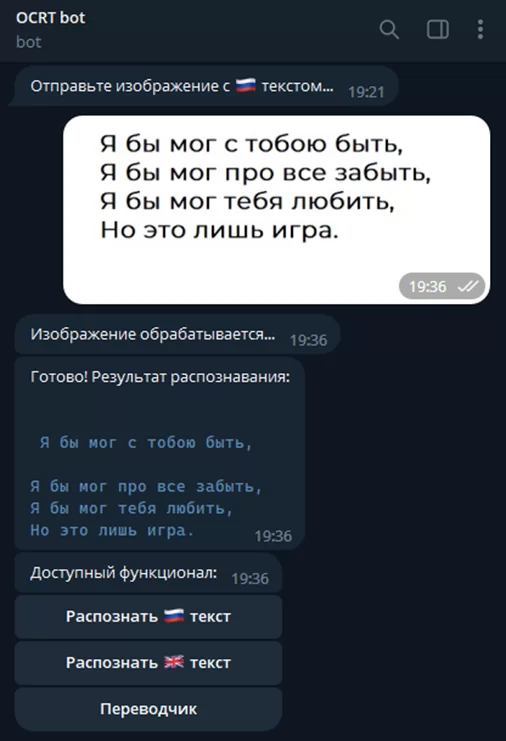
Распознавание работает. Кстати, благодаря функционалу telegram и некоторой магии, текст можно копировать, просто нажав на него. Теперь настроим переводчик. Для этого нам понадобится функция – обработчик callback_data из кнопки «Переводчик»:
@dp.callback_query_handler(lambda cb: cb.data == 'translate')
async def pre_translate(callback_query: types.callback_query):
cb = callback_query
uid = cb.from_user.id
try:
await lang.transt.set()
await bot.send_message(uid, 'Отправьте 🇷🇺 или 🇬🇧 текст, бот его переведет...')
except Exception:
print(traceback.format_exc())
await bot.send_message(uid, 'Что-то пошло не так...', reply_markup=initial_keyboard())
В этой функции мы задали состояние lang.transt. Теперь после нажатия кнопки «Переводчик» наш бот будет выглядеть так:
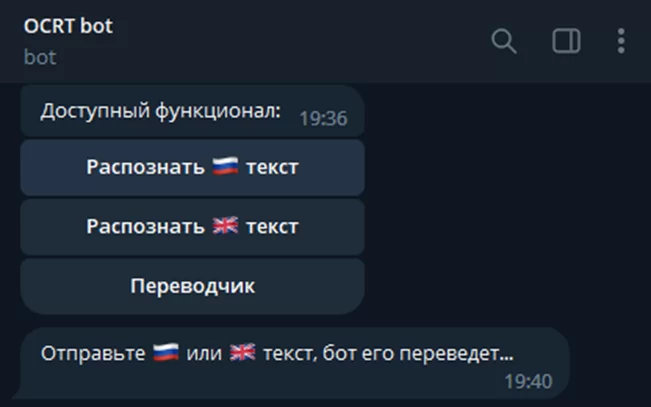
Ожидается отправка пользователем текста. Создадим обработчик и для этого:
@dp.message_handler(state=lang.transt)
async def handle_translate_text(message: types.Message, state):
uid = message.chat.id
text_to_translator = message.text
try:
await bot.send_message(uid, f'Текст обрабатывается...')
flag_origin, tr_result = await translateText(text_to_translator)
await bot.send_message(uid, f'Готово! Перевод с {flag_origin}: {tr_result}')
await bot.send_message(uid, 'Доступный функционал:', reply_markup=initial_keyboard())
await state.finish()
except Exception:
print(traceback.format_exc())
await bot.send_message(uid, 'Что-то пошло не так...', reply_markup=initial_keyboard())
Здесь используется функция translateText(). Для ее работы придется импортировать googletrans и langdetect. А для красивого отображения — вернем флаг, обозначающий исходный текст:
from googletrans import Translator
from langdetect import detect
async def translateText(inp):
dest = "ru" if detect(inp) == "en" else "en"
flag_origin = "🇬🇧" if detect(inp) == "en" else "🇷🇺"
tr = Translator()
result = tr.translate(inp, dest=dest).text
return flag_origin, result
Переведем текст в интерфейсе бота:
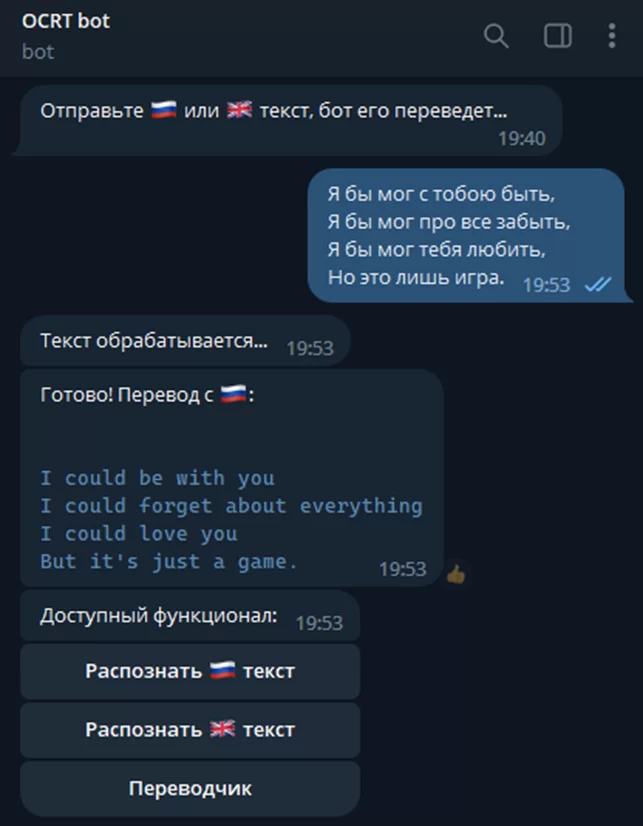
Таким образом, мы получили полезного бота, который не только может распознавать текст на двух языках, но и переводить его. В качестве сервера можно оставить включенный компьютер, микрокомпьютер или арендовать хостинг. Такой программе не нужно много вычислительной мощности, любого самого дешевого сервера хватит.
Спасибо за внимание! Пишите в комментариях, какой бот пригодился бы вам! А скачать и посмотреть полную версию кода можно по ссылке на GitHub!