/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 9 мин.
Биометрия везде. Современные мегаполисы в России и мире окутаны сетями камер, подключенными к различным системам распознавания лиц. Насколько это правильно с точки зрения этики — каждый решает сам, но факт в том, что такие методы не только помогают раскрывать преступления, но и предотвращать их совершение.
С каждым годом расширяется область применения таких систем. Например, пользователи могут приобрести у Google систему Nest — Nest Cam IQ Indoor, стоимостью 349 долларов с интеграцией в умный дом и возможностью распознавания лиц по подписке (за 10 долларов в месяц). И отечественных аналогов для частного пользования немало. Различные СКУД (системы контроля и управления доступом) от Ростелекома, HikVision, VisionLabs и других фирм. Описание зачастую мутное, опыт работы в реальных условиях можно найти на YouTube по запросу «Умный домофон не пускает мужчину домой».

Да, назначение систем с технологиями распознавания лиц может быть разным, но все они имеют два главных недостатка: завышенная цена и отсутствие приватности. Разберем подробнее второй пункт.
Существует несколько методов реализации системы определения биометрических данных в реальном времени: анализ видеопотока на удаленном сервере, на камере с передачей данных на сервер, на локальном устройстве с подключенной камерой.
Наиболее распространена первая схема реализации. Работает она так: камера передает видеопоток на сервер, там специализированное ПО в реальном времени выполняет анализ видеопотока и сравнивает полученные изображения лиц с базой лиц эталонов. Недостатки такой системы — высокая нагрузка на сеть, ограничение по количеству подключенных камер на один сервер.
При применении 2 технологии, анализ изображения будет производится на самом устройстве — камере, а на сервер будут передаваться обработанные метаданные. Недостаток такой системы — очень высокая стоимость камер, способных обработать изображение. Зато можно подключить практически неограниченное количество устройств к удаленному серверу.
Третий метод лучше всего подходит для личного пользования. Именно он будет рассмотрен в этой статье. Он отличается от первого локальным использованием. Из этого вытекает большое преимущество – данные биометрии не передаются третьим лицам, хранятся на локальном устройстве пользователя. Основной недостаток – таких систем почти нет в продаже.
Обычно в качестве базы для локальной системы распознавания лиц используется компьютер или ноутбук с мощным графическим ускорителем. Предпочтительны видеокарты Nvidia из-за архитектуры CUDA, позволяющей существенно увеличить вычислительную производительность системы.
Вопреки расхожему мнению, алгоритмы распознавания лиц могут работать и на системах с небольшой вычислительной мощностью. Как например одноплатный микрокомпьютер Raspberry PI 4B с производительностью старого андройд смартфона. Именно такой микрокомпьютер с 4гб оперативной памяти и 4-ядерным процессором частотой 1.5 ГГц был использован в данном проекте.

В качестве алгоритма распознавания лиц была использована библиотека face-recognition для python. Эта библиотека работает с моделью распознавания лиц от dlib. Устанавливается достаточно просто (cv2 для отображения картинки с камеры):
pip install face-recognition, opencv-pythonПомимо простоты установки, данный модуль не требует от устройства высокой производительности и по его использованию написано огромное количество гайдов. Основная часть заключена всего в нескольких строчках, а часть распознавания лиц из кода системы выглядит следующим образом:
import face_recognition
import numpy as np
import cv2
# векторные представления лиц, имена, user_id в БД
known_face_encodings, known_face_names, known_face_uids = [], [], []
def run_rec():
video_capture = cv2.VideoCapture(0, cv2.CAP_DSHOW)
while video_capture.isOpened():
# чтение кадра с камеры
ret, frame = video_capture.read()
# уменьшение разрешения (для быстродействия)
divideint = 2
small_frame = cv2.resize(frame, (0, 0),
fx=1 / divideint, fy=1 / divideint)
# уменьшение размерности матрицы изображения, аналог [:, :, ::-1]
rgb_small_frame = cv2.cvtColor(small_frame, cv2.COLOR_BGR2RGB)
# обрабатывается каждый 3й кадр (для быстродействия)
if process_this_frame % 3 == 0:
# расположение лиц
face_locations = face_recognition.face_locations(rgb_small_frame)
# преобразование лиц в векторы
face_encodings = face_recognition.face_encodings(rgb_small_frame,
face_locations)
# сравнение обнаруженных лиц с лицами в базе
for face_encoding in face_encodings:
name = "Unknown"
# вычисление векторного расстояния (мера схожести векторов)
# known_face_encodings -
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding)
# определение индекса максимально похожего лица
best_match_index = np.argmin(face_distances)
# проверка на степень похожести
# похожи если векторное расстояние расстояние меньше 0.6
if face_distances[best_match_index] < 0.6:
# имя обнаруженного лица для пользователя
name = known_face_names[best_match_index]
# user_id лица для внутреннего использования
uid = known_face_uids[best_match_index]
Тестирование системы производилось на базе данных ORL, содержащей изображения лиц с небольшими изменениями освещения, масштаба, пространственных поворотов, положения и различными эмоциями. База представляет собой 400 фотографий 40 разных людей. Все фото представлены в градации серого.

Обычно эта база используется для обучения алгоритмов распознавания лиц, но я решил проверить качество работы и быстродействие алгоритма на основе face-recognition. В результате, алгоритм, работающий на Raspberry PI 4B смог обнаружить 376 лиц за 7 секунд.
import os
import glob
import face_recognition
import time
start = time.time()
faces_folder_path = './orl_faces'
cnt = 0
for f in glob.glob(os.path.join(faces_folder_path, "*.jpg")):
print("Processing file: {}".format(f))
#загрузка фото
img = face_recognition.load_image_file(f)
#обнаружение лица на фотро
face_locations = face_recognition.face_locations(img)
#подсчет
# face_locations - список элементов (лиц)
# в списке столько элементов, сколько лиц на фото
print("Number of myfaces detected: {}".format(len(face_locations)))
if len(face_locations) != 0:
cnt += 1
print(f'total myfaces detected {cnt}')
print(f'total seconds spent {int(time.time() - start)}')
Так, например, компьютер на процессоре Intel Core I5 смог обнаружить те-же 376 лиц примерно за 2 секунды.
Но показатели этого теста можно рассматривать только в контексте скорости обнаружения лица в кадре. Неотъемлемой частью алгоритма распознавания лиц является сравнение лица в кадре с лицами в базе системы. Для этого необходимо преобразовать картинку в векторное представление и сравнить со всеми лицами в базе. К тому же, необходимо было организовать подключение к базе данных с постоянным обновлением данных в ней. Для управления базой данных была использована СУБД SQLite. Она отличается от других СУБД простотой настройки и удобством использования в малопроизводительных платформах, как Raspberry PI. Через постоянные обращения к базе и определяется принадлежность лица в объективе камеры системы к лицам, добавленным в систему как авторизованные пользователи; осуществляется логирование посещений. Эти части алгоритма (векторное преобразование, обращение к базе, сравнение обнаруженного лица с лицами в базе) и представляют собой самую ресурсоемкую его часть. Обращение к базе:
def get_db():
conn = sqlite3.connect("face_db.sqlite3")
cursor = conn.cursor()
cursor.execute("SELECT * FROM FRS")
facecount = cursor.fetchall()
known_face_encodings = []
known_face_names = []
known_face_uids = []
face_in_home = []
for i in range(len(facecount)):
a = pickle.loads(facecount[i][5])
known_face_encodings.append(a)
known_face_names.append(facecount[i][1])
known_face_uids.append(facecount[i][0])
face_in_home.append(facecount[i][10])
return known_face_encodings,
known_face_names,
known_face_uids,
face_in_home, conn
Кроме обнаружения и сравнения лица с находящимися в базе пользователей, есть еще одна часть работы алгоритма. Для проверки работы системы распознавания лиц необходима графическая интерпретация. То есть, для того чтобы увидеть, правильно ли лицо распознается и обнаруживается, необходимо транслировать на экран устройства потоковое видео и обрисовывать в нем границы объекта, распознанного как лицо.
import numpy as np
import cv2
# запуск камеры
video_capture = cv2.video_capture(0, cx2.CAP_DSHOW)
# изменение размеров и имени окна для показа изображения
video_capture.set(3, 800)
video_capture.set(4, 448)
сv2.namedWindow('Video', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Video', 800, 448)
# расположение краев прямоугольника, обозначающего лицо в кадре; имя
for (top, right, bottom, left), name in zip(face_locations, face_names):
# рисуем прямоугольник вокруг лица
cv2.rectangle(frame, (left, top), (right, bottom), (107, 168, 0), 2)
# рисует плашку под текст с именем пользователя
cv2.rectangle(frame, (left, bottom - 23), (right, bottom), (107, 168, 0), cv2.FILLED)
cv2.putText(frame, name, (left + 6, bottom - 6), cv2.FONT_ITALIC, 0.5, (0, 0, 0), 1)
# отображение состояния системы
cv2.rectangle(frame, (8, 5), (228, 64), (255, 255, 255), cv2.FILLED)
cv2.putText(frame, 'RECOGNITION IN PROGRESS', (10, 20), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 0), 2)
cv2.putText(frame, 'Model: face-recognition', (10, 40), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 0), 2)
В реальных условиях, при работе с потоковым видео, при наличии лица в кадре, данный алгоритм показывал скорость в 1-2 обработанных кадра в секунду (обнаружение лица, сравнение с лицами – эталонами):
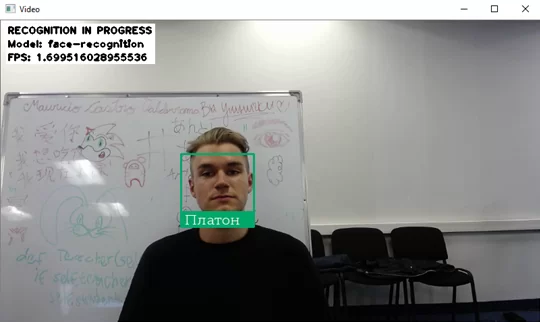
Без показа видео количество обработанных кадров поднялось до около-стабильных 2 FPS. Небольшое изменение, но очень важное в такой системе, реализуемой на одноплатном микрокомпьютере.
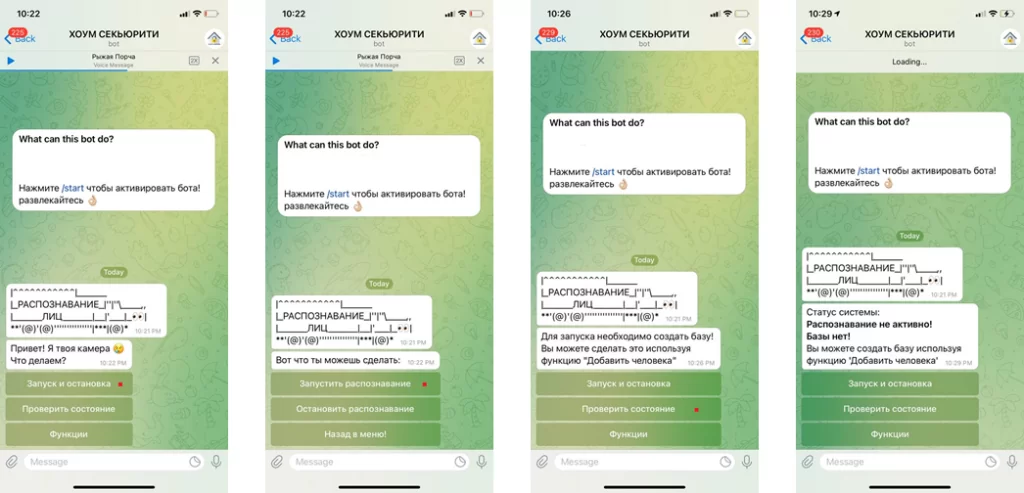
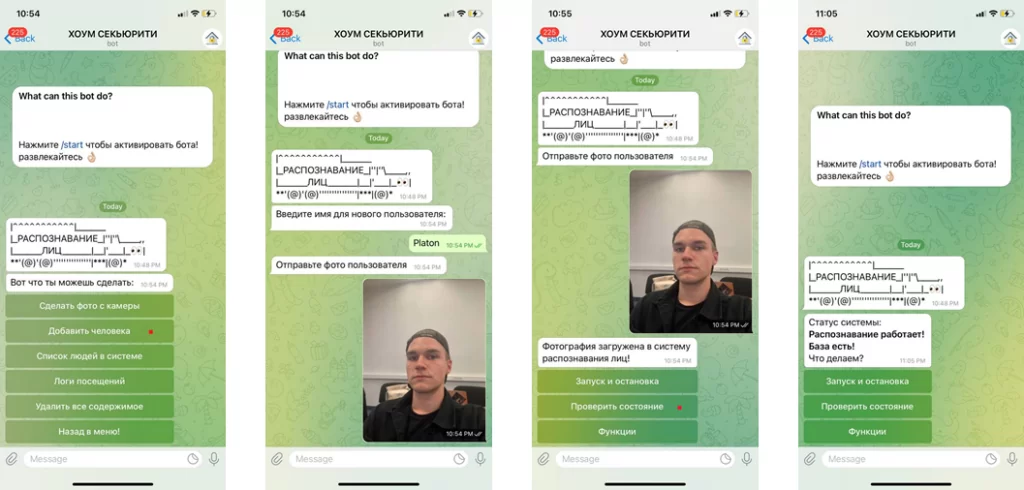
Поскольку проект позиционировался как домашняя система распознавания лиц, необходимо было реализовать удобный интерфейс управления и добавить некоторый функционал. Разработка любого приложения довольно ресурсоемкое занятие, требующее обширных знаний. Поэтому было принято решение вместо полноценного приложения создать чат-бота в мессенджере Телеграм с использованием библиотеки AioGram.
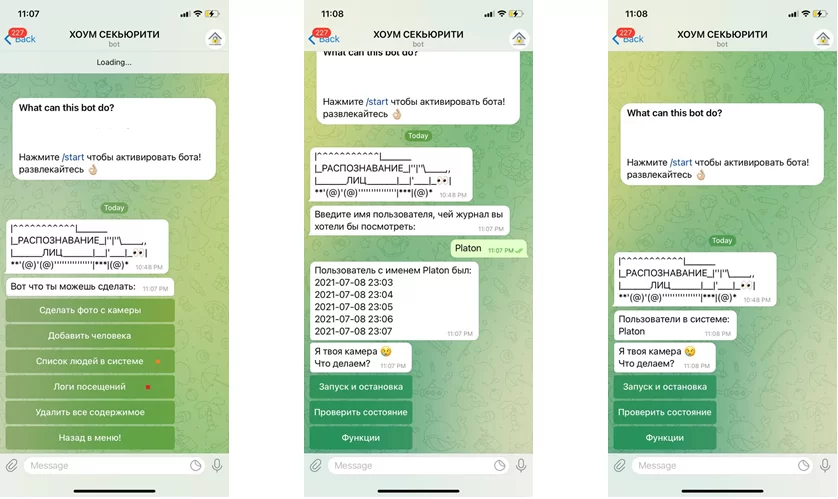
Бот находится на стадии MVP, но уже имеет достаточно разных функций для обеспечения автономной и относительно стабильной работы системы. В числе функций:
— включение/выключение функции распознавания лиц (для снижения нагрузки);
— создание и занесение в базу лиц через отправку фотографий чат-бота;
— проверка журнала посещения (только для пользователей, вручную добавленных в базу);
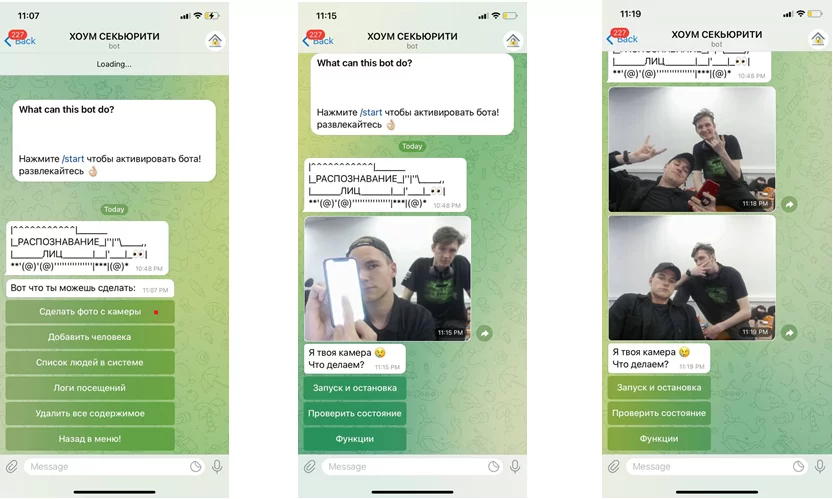
— получение фотографии с камеры системы распознавания в любой момент;
— ограничение доступа к функциям чат-бота неавторизованным пользователям.
Работа функций в чат-боте:
В заключении хочется сказать, что функционал системы по большому счету ограничен только воображением. И конечно же, навыками программирования. Несмотря на то, что мощность Raspberry ограничена, у неё очень много возможностей, вплоть до управления системой умного дома. Да, проект на данный момент далек от завершающей стадии, но уже можно с уверенностью сказать – домашняя система распознавания лиц возможна и на одноплатном микрокомпьютере.