/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Наверняка в жизни многих из нас были ситуации, когда мы смотрели на листочек или фотографию с красивой и нужной табличкой, но ничего не могли поделать. А потом смирившись перепечатывали ее в Word вручную. Если так, то присаживайтесь поудобнее, эта статья как раз для Вас!
Сначала, конечно же, нужно считать изображение в черно-белой гамме, после чего фильтром превратить изображение в набор исключительно черных и белых точек (рис.1).

А теперь давайте рассмотрим дальнейшие действия поподробнее. Первоочередной задачей в детектировании таблиц является определение ее границ. Но есть риски, что граница будет наклонной или ввиду плохого качества фото или сканирования – граница вовсе может прерываться. Учитывая эти риски, было принято решение сначала это изображение огрубить. Огрубление производится, сжимая изображение квадратами 2х2, до тех пор, пока на картинке не более 100 точек по широкой стороне (рис.2). В случае если в квадрате как минимум половина точек – черные, квадрат заменяется на черную точку, в противном случае – на белую.

В результате такой обработки невозможно разглядеть текст, но можно однозначно определить границы таблицы (рис.3).

На огрубленном изображении пересчитывается количество черных точек во всех строках и столбцах.
Когда мы получили список подсчетов черных точек по горизонтали и вертикали, недостаточно просто взять крайние не белые столбцы и строки, потому что на изображении может располагаться текст или «грязь» вне таблицы. Поэтому для определения границ применяется медианный фильтр или фильтр по среднему значению.
Выбор способа фильтрации зависит от значения медианы каждого списка отдельно. В случае, когда медиана списка превышает 25% от наибольшего значения в данном списке, применяется медианный фильтр, в противном случае – изображение содержит слишком мало черных точек и медианный фильтр будет мало информативен. Медианный фильтр заключается в поиске медианы по подсчитанным спискам и выборе строк и столбцов, превышающих значение медианного значения как минимум на 30% (рис.4). Списки строк и столбцов предварительно были разбиты на 4 секции и медианный фильтр показывает в каждой секции недостаточно темные ячейки. Для наглядности значения медианного фильтра по секциям отображены разными цветами: секция 1 – красный, секция 2 – зеленый, секция 3 – желтый, секция 4 — розовый.
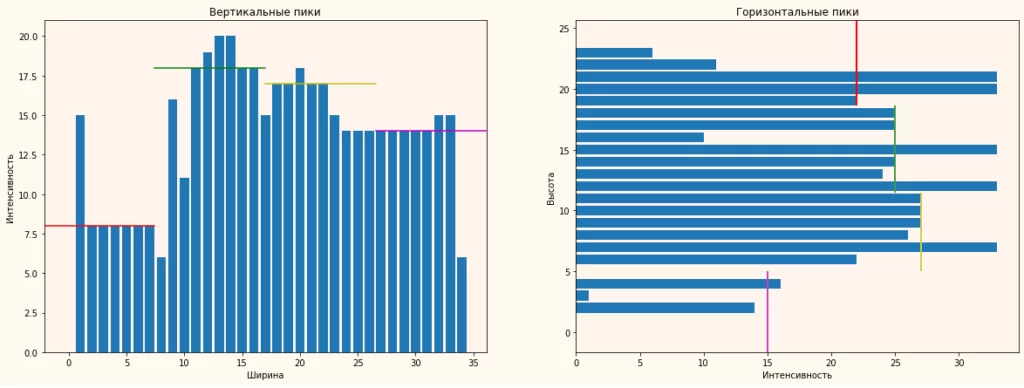
Фильтр по среднему значению так же разбивает списки на 4 секции, после чего определяет среднее значение непустых ячеек, а дальше оставляет только те столбцы и строки, значения которых превышают среднее значение.
После фильтрации списки интенсивностей черных точек ясно показывают, в каких областях располагаются наиболее черные строки и столбцы – в их пределах и располагается наша таблица (рис.3).
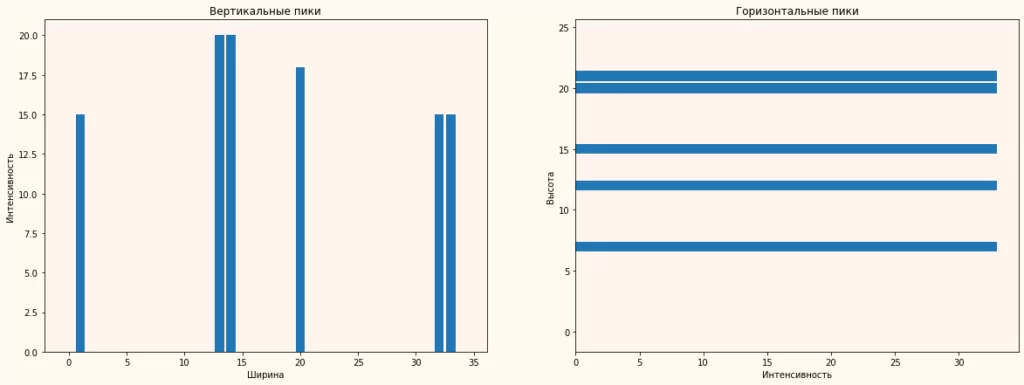
Для наглядности нарисуем контур на исходном изображении (рис.4) и посмотрим, что получилось.
Применимость метода
Для проверки условий применимости метода были сгенерированы тестовые наборы.
- Генерация загрязненных изображений с максимальной плотностью черных до 80%
Предварительно изображение было сеткой разбито а равные сектора и пропорционально контрастности черных точек каждого сектора сгенерированы изображения с шагом контрастности в 5% (рис.5), до тех пор, пока общая контрастность изображения не достигла 80%.

Для следующих пунктов изображение было предварительно загрязнено равномерно до 80% контрастности и восстановлено разными способами.
2. Регулярное загрязнение
Для данного тестового набора сгенерированы 100 изображений, восстановленных сеткой из наборов по 10 прямоугольников и каждый набор циклически смещен по изображению горизонтально (рис.6а), вертикально (рис.6б) или диагонально (рис.6в).



Рисунок 6 – Восстановленные изображения методом регулярных прямоугольников
3. Нерегулярное загрязнение
Для данного набора были сгенерированы прямоугольники, восстанавливающие площадь от 20 до 50% изображения (рис.7).

4. Восстановление по Мандельброту
Для данного способа было создано множество точек на основе функции Мандельброта. Из построенного множества был взят произвольный контрастный квадрат (рис.8).

Данный фрагмент накладывался на изображение одним из трех способов: вписывание фрагмента в изображение разным количеством раз (рис.9а), отражением сектора данного фрагмента (рис.9б) и регулярным вращением фрагмента на 45 градусов (рис.9в). В местах пересечения с полученной маской изображение восстанавливалось.



Рисунок 9 – Восстановленное изображение по множеству Мандельброта
После этого инструмент был протестирован на полученном тестовом наборе и определен предел контрастности изображения при детектировании таблицы. Предел контрастности составил 44,7%(рис.6). Под контрастностью стоит понимать отношение общего количества черных точек изображения к количеству белых.

После детектирования границ можно продолжить рекурсивно двигаться внутрь таблицы тем же способом, каждый раз разбивая ее на отдельные изображения, сохраняя координаты прямоугольников и снова находя наибольшие по интенсивности строки и столбцы.
Когда изображение разбито на отдельные ячейки и дальше делить его – некуда, применяется ORC Tesseract (рис.11).

Остается лишь собрать информацию в DataFrame и экспортировать в Excel. Желаю удачи!