/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
В процессе решения задачи при работе с данными нередко возникает ситуация, когда получение реальных данных сложно, к примеру, если речь идет о конфиденциальной информации, либо сбор данных занимает большое количество времени, либо просто необходимо протестировать проект с данными, которые соответствуют определенным критериям. Для решения ситуации мы можем искусственно сгенерировать данные с помощью языка программирования.
Существует множество пакетов для генерации данных, таких как DataSynthesizer, pydbgen, Mimesis, SDV, plaitpy, TimeSeriesGenerator, Gretel Synthetics, Scikit-learn, Mesa и др. Рассмотрим три самых интересных, в плане функциональности и простоты использования, способа генерации синтетических данных с помощью пакетов Python.
- Faker
Faker — это пакет Python, разработанный для упрощения генерации синтетических данных. Данный пакет прост и интуитивно понятен в использовании. Установим пакет и попробуем:
pip install FakerЧтобы использовать пакет Faker для генерации данных, необходимо инициализировать класс. Дополнительно укажем параметр локализованной области для экземпляра ru_RU, чтобы данные сгенерировались на русском языке (параметр по умолчанию en_US).
from faker import Faker
fake = Faker("ru_RU")
После инициализации сгенерируем 5 имен:
for _ in range(5):
print(fake.name())
Вениамин Давыдович Котов
Марфа Геннадиевна Никонова
Кириллов Севастьян Аксёнович
Анжела Юрьевна Романова
Зимина Наталья Анатольевна
Когда мы используем атрибут .name из класса Faker, результатом является имя, фамилия и отчество человека. Синтетические данные генерируются случайным образом каждый раз при запуске атрибута. С помощью пакета можно также сгенерировать адрес, работу, кредитный рейтинг и многое другое. С полным списком можно ознакомиться в документации.
2. SDV
SDV или Synthetic Data Vault — это пакет Python для генерации синтетических данных на основе предоставленного набора данных. Сгенерированные данные будут иметь те же свойства формата и статистику, что и предоставленный набор данных. SDV генерирует данные, применяя математические методы и модели машинного обучения. С помощью SVD можно обработать данные, даже если они содержат несколько типов данных и отсутствующие значения.
Для начала установим пакет.
pip install sdvДля примера возьмем датасет Stroke Prediction Dataset от Kaggle с данными для прогнозирования инсульта.
import pandas as pd
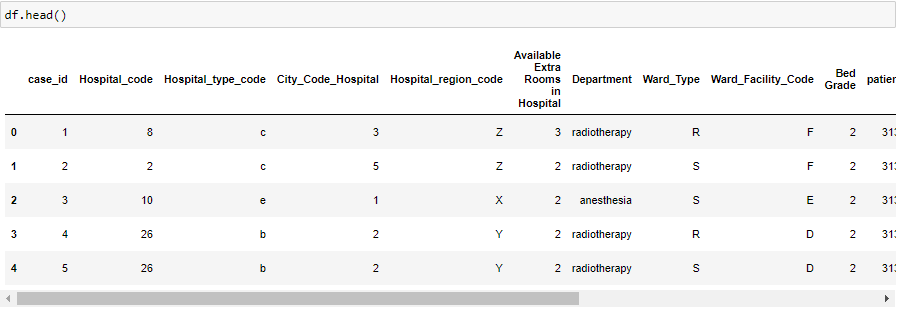
data = pd.read_csv('healthcare-dataset-stroke-data.csv')
data.head()

Наш датасет готов, теперь сгенерируем синтетические данные на основе набора данных. Используем для этого одну из доступных моделей SVD Singular Table (https://sdv.dev/SDV/user_guides/single_table/models.html), GaussianCopula. Создадим экземпляр класса и вызовем метод fit, передав наши данные.
from sdv.tabular import GaussianCopula
model = GaussianCopula()
model.fit(data)
После того как наша модель обучена, вызываем метод sample, указав количество строк, которые хотим сгенерировать, например, 1000.
sample = model.sample(1000)
Однако, нам необходимо, чтобы данные в колонке с идентификатором были уникальными. Для этого передадим в параметр модели primary_key нашу колонку id.
model = GaussianCopula(primary_key='id')
model.fit(data)
После генерации, мы получим данные с уникальными id.
Теперь вопрос, а насколько хороши сгенерированные синтетические данные? Воспользуемся функцией evaluate из SDV. Эта оценка будет сравнивать реальный набор данных с синтетическим набором.
evaluate(data, sample)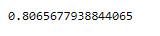
Результатом вызова функции является число от 0 до 1, которое показывает насколько похожи две таблицы: 0 — худший результат, 1 — наилучший возможный результат.
Функция оценки применяет набор предварительно настроенных метрических функций и возвращает среднее значение оценок, полученных по каждой из них.
Для того чтобы увидеть различные метрики, которые были применены, можно передать дополнительный аргумент aggregate=False. Результатом будет словарь с оценками, которые возвращала каждая из метрик. Для проверки доступно много метрик. Возьмем для примера статистические метрики (критерии Колмогорова–Смирнова и Хи-квадрат) и метрику обнаружения, основанную на классификаторе логистической регрессии.
from sdv.evaluation import evaluate
evaluate(data, sample, metrics=['CSTest', 'KSTest', 'LogisticDetection'], aggregate=False)

Статистические метрики сравнивают отдельные столбцы из исходной таблицы с соответствующими столбцами из сгенерированной таблицы и выводится среднее значение. KSTest используется для сравнения столбцов с непрерывными данными, а CSTest с дискретными данными.
Метрика LogisticDetection при помощи машинного обучения позволяет оценить насколько сложно отличить синтетические данные от исходных. Для этого реальные и синтетические данные перемешиваются и устанавливается значение, указывающее, являются ли данные реальными или синтетическими, а затем перекрестно проверяют модель машинного обучения, которая пытается предсказать это значение.
3. Gretel
Gretel или Gretel Synthetics – это пакет Python с открытым исходным кодом, основанный на рекуррентной нейронной сети для создания структурированных и не структурированных данных.
Чтобы установить пакет, запустите следующий код:
pip install gretel-syntheticsВоспользуемся модулем Batch из пакета Gretel. Этот модуль работает непосредственно с датафреймами данных Pandas и позволяет автоматически разбивать датафрейм на более мелкие датафреймы (по кластерам столбцов), выполнять обучение модели и генерацию для каждого фрейма независимо. Затем мы можем объединить все обратно в один окончательный набор синтетических данных. В связи с этим пакет хорошо подходит для наборов данных с высокой размерностью и количеством столбцов.
Импортируем класс DataFrameBatch и определим параметры для обучения модели.
from gretel_synthetics.batch import DataFrameBatch
from pathlib import Path
df = pd.read_csv ("https://gretel-public-website.s3.amazonaws.com/datasets/healthcare-analytics/hospital_ehr_data.csv")
checkpoint_dir = str(Path.cwd() / "test-model")
config_template = {
# Число итераций по всему предоставленному обучающему набору
"epochs": 54,
# Максимальная длина строки для обучения
"max_line_len": 2048,
# Максимальный размер токенов, который будет извлечен из входного набора данных
"vocab_size": 200000,
# Указываем разделитель для структурированного текста
"field_delimiter": ",",
# Перезапись
"overwrite": True,
# Структура каталогов будет создана в расположении “checkpoint_dir”. Внутри папки будет создано по одному каталогу “batch_N”, где N - номер набора, начиная с 0.
"checkpoint_dir": checkpoint_dir
}
Используемый набор данных представляет собой набор данных электронной медицинской карты больницы, доступный от Gretel.
Приступаем к обучению. Инициализируем класс, указав параметры – исходный датафрейм и параметры для обучения, так же можно указать параметр batch_size и задать число столбцов в наборе (по умолчанию разбивка производится автоматически). Функция create_training_data() создает датафрейм данных и файл «train.csv» для каждого набора. Функция train_all_batches() перебирает все наборы и обучает модели.
batcher = DataFrameBatch(df = df, config = config_template)
batcher.create_training_data()
batcher.train_all_batches()
Генерируем синтетические данные. Результатом функции generate_all_batch_lines() является словарь, который показывает, удалось ли сгенерировать данные в каждом наборе.
status = batcher.generate_all_batch_lines(num_lines=1000)
synthetic_df = batcher.batches_to_df()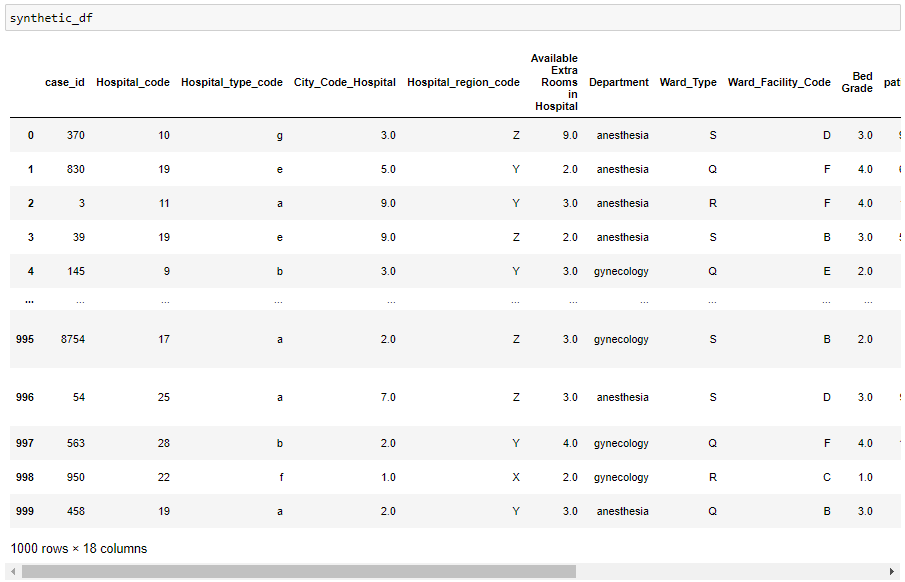
Набор синтетических данных получен!
Теперь с помощью пакета Gretel cгенерируем синтетические данные для Stroke Prediction Dataset и проанализируем их относительно данных полученных с помощью пакета SVD из пункта 2. Воспользуемся возможностями API интерфейса Gretel. Это очень удобный, интуитивно понятный и доступный интерфейс, который отлично подходит для быстрой генерации данных, даже с мобильного устройства. Загрузим данные и выберем параметры по умолчанию.
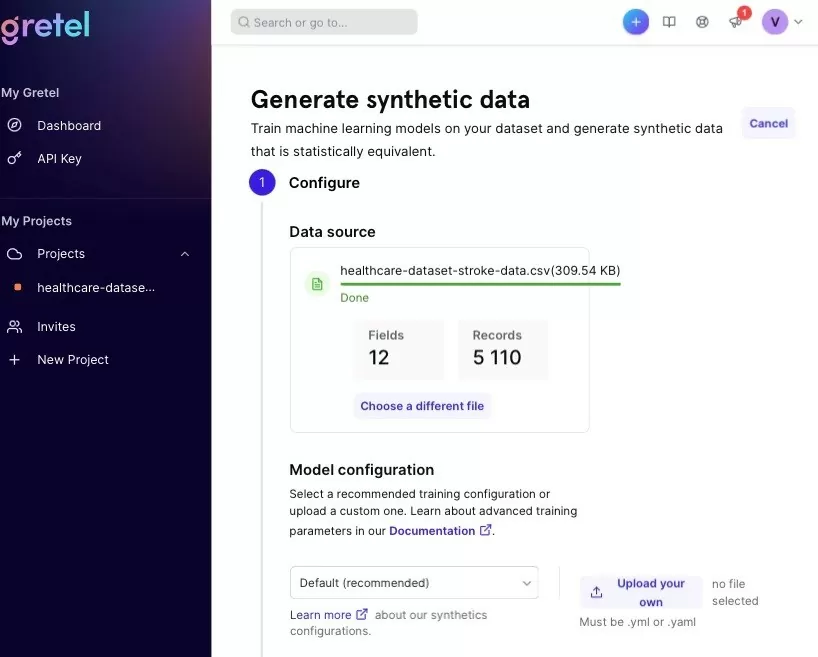
После обучения и генерации данных в интерфейсе Gretel можно посмотреть отчет о полученных синтетических данных: краткий и полный отчет, сохраненный в html-файл.
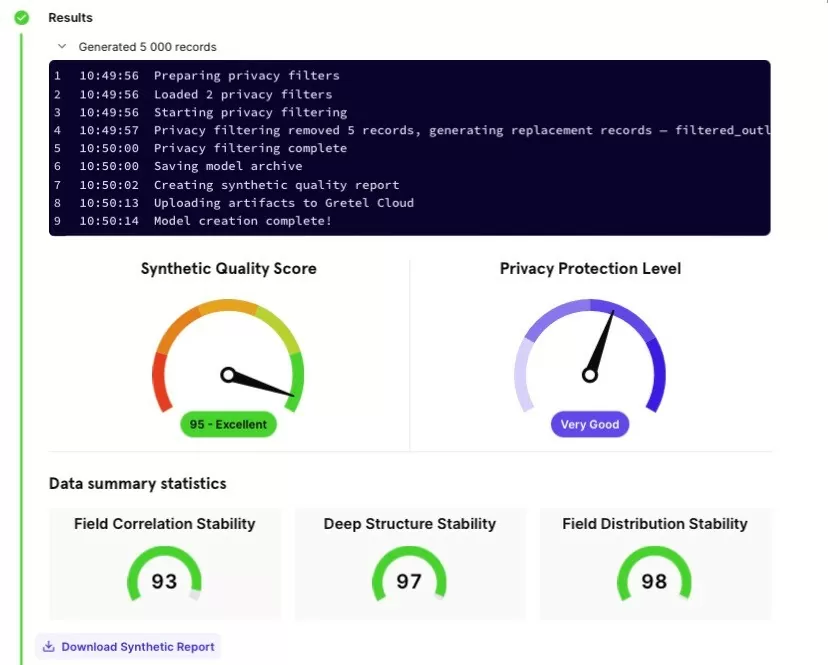
В полном отчете подсчитана сводная статистика, оценка качества синтетических данных, так же представлена таблица с показателями стабильности распределения по каждому полю таблицы и корреляционные матрицы.
Сравнивая время работы двух способов на одном датасете, получилось, что времени на обучение с помощью пакета Gretel уходит больше (SDV – 14,4 c, Gretel – 234 c), при достижении близких оценок качества.
Итак, мы разобрали 3 пакета языка Python для генерации данных – Faker, SDV и Gretel. Надеюсь вам окажется полезна данная информация для работы и тестирования ваших решений.
Благодарю за прочтение!