/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Латентное размещение Дирихле – это тематическая модель, которая подразумевает, что каждый документ является коллекцией тематик, распределение которых соответствует распределению Дирихле. Если вы начнете поиск создания модели LDA на Python в Интернете, то вы скорее всего найдете реализацию через библиотеки Gensim и Scikit-Learn. Давайте сравним их.
Для демонстрации в качестве тестового датасета был выбран сборник школьных сочинений, содержащий 560 текстов. Тексты хранятся в JSON, причем есть несколько вариантов одного и того же файла, но с различными дополнительными параметрами. Нам важны только тексты, поэтому стоит отсеять файлы по имени (что было в моем случае) или же просто извлечь из архива только необходимые файлы. Можно также дополнительно отключить DeprecationWarning на будущее.
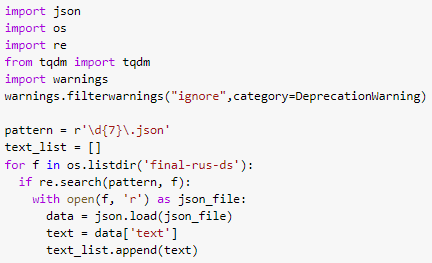
Далее необходимо избавиться от слов, не несущих много информации, (стоп-слов) и привести оставшиеся слова в текстах к начальной форме. В этом нам помогут модули spacy и nltk. Для модуля sрасу также понадобится пакет для работы с русским языком. Импортируем библиотеки, загружаем стоп-слова и создаем обработчик.
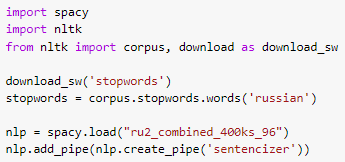
Основную смысловую нагрузку в предложениях несут существительные, глаголы, прилагательные и наречия, поэтому из всех слов нам нужны только попадающие под эти части речи. Помимо этого, мы избавляемся от стоп-слов.
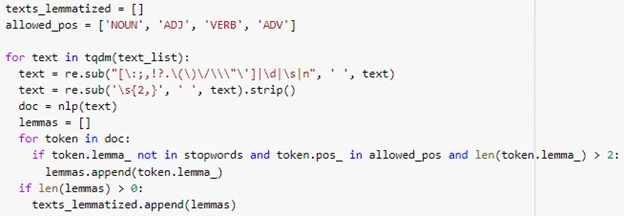
Теперь, когда у нас есть списки лемм, мы можем приступить непосредственно к тематическому моделированию.
Начнем с реализации LDA библиотеки Gensim. Первым делом нужно подготовить корпус и словарь:

Далее необходимо подобрать количество тем. Здесь стоит сказать про такой показатель модели как когерентность. Когерентность – это степень неслучайной схожести тем. Чем больше показатель когерентности, тем более связаны термины меж собой в темах и тем лучше модель.
Мы можем подобрать хорошую модель, обучив несколько моделей и выбрав ту, что имеет наибольшую когерентность.
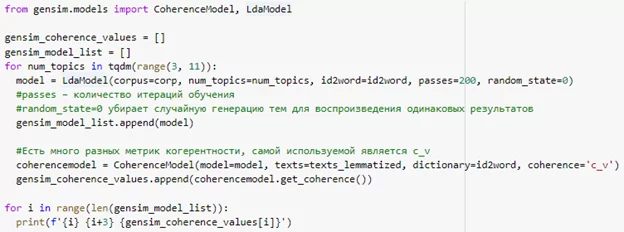
Модель с семью темами показала наибольшую когерентность, поэтому выбираем ее. Визуализация LDA модели осуществляем с помощью библиотеки pyLDAvis.
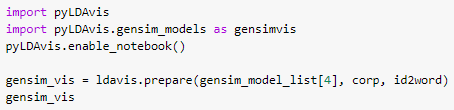
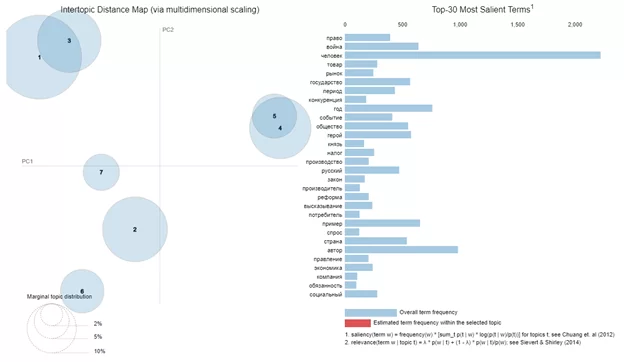
При наведении курсора на круг визуализатор показывает слова, относящиеся в найденной теме. У нас получился следующий результат: темы 1 и 3 можно назвать «литература», темы 4 и 5 – «история», 7 – «право», 2 – «обществознание» и 6 – «экономика».
На очереди Scikit-Learn. Мы можем использовать списки лемм, которые мы приготовили для Gensim. Небольшое отличие состоит в том, что Scikit-Learn использует целые тексты для подсчета слов по документам, поэтому мы просто соединим списки слов пробелами. В следующем участке кода из текста мы получим матрицу распределения слов по документам:
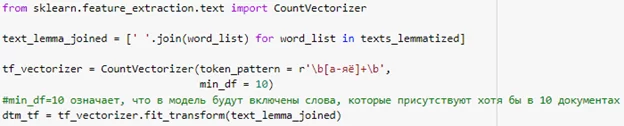
Теперь нужно снова подобрать оптимальное количество тем, как и в случае с Gensim. В Scikit-Learn нет возможности подсчитать когерентность модели. Тем не менее в библиотеке присутствует способ оценить качество модели LDA – метод sсоrе у класса LatentDirechletAllocation, возвращающий значение функции правдоподобия. Значение всегда будет негативным из-за особенностей работы алгоритмов машинного обучения. Чем больше значение функции (или иначе говоря, чем меньше значение по модулю), тем лучше модель.

Модель с шестью темами оказалась наиболее оптимальной. Визуализируем через pyLDAvis:

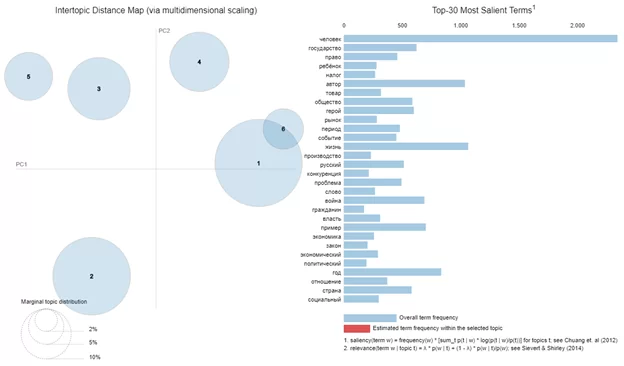
Темы 1 и 6 – «русская культура», 4 – «обществознание», 3 – «экономика», 5 – «политика», 2 – «история».
Сделаем выводы. LDA модели не один раз показали свою эффективность решения задач тематического моделирования. Gensim и Scikit-Learn смогли выделить примерно одинаковые темы из нашего датасета. Стоит сказать, что Scikit-Learn – это в некотором роде «швейцарский нож» для решения задач машинного обучения, в то время как Gensim – это библиотека, предназначенная именно для тематического моделирования. Тем не менее оба модуля хорошо справляются с этой задачей, поэтому решение использования Gensim или Scikit-Learn для создания LDA моделей остается за вами.
Оцените статью, если она вам понравилась, и оставляйте комментарии.
Просмотреть полный ноутбук Python можно на репозитории GitHub.