/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Недавно мне потребовалось сделать большую выборку данных (несколько млн. записей) возник вопрос, как сохранить полученный результат для последующей обработки, т.к. на Hive выгрузить такой объем не представлялось возможным. Задача была решена с помощью DS-машины(DatalabAI), c использованием формата хранения данных — Parquet.
Отвечу на вопросы:
- Какие бывают форматы данных
- Для чего нужны разные форматы
- Чем лучше Parquet
- Примеры работы на практике с форматом Parquet
Обработка больших данных значительно увеличивает нагрузку на систему хранения. Hadoop хранит данные избыточно для достижения отказоустойчивости. Кроме дисков, нагружаются процессор, сетевые ресурсы, системы ввода-вывода данных. По мере роста объема данных значительно увеличивается и стоимость их обработки и хранения.
Различные форматы файлов в Hadoop используются для решения именно этих проблем. Выбор подходящего формата файла может дать существенные преимущества:
- Более быстрое время чтения.
- Более быстрое время записи.
- Разделяемые файлы.
- Поддержка эволюции схем.
- Расширенная поддержка сжатия
В Hadoop поддерживаются различные форматы файлов
Текстовые / CSV-файлы – повсеместно распространенный формат для обмена данными между Hadoop и внешними системами. Файлы в данном формате занимают значительный объем места так как не поддерживают сжатия, что приводит к существенным затратам на чтение данных файлов. Структура файла жестко связана с последовательностью полей и не хранит метаданные. Человеко-читаемый формат.
Записи в формате JSON – в отличие от CSV каждая строка представляет JSON базу данных, что позволяет разделять файл на части. Метаданные хранятся совместно с данными, что позволяет эволюционировать схеме. Также, как и CSV не поддерживает сжатие и занимает значительный объем места. Человеко-читаемый формат.
Файлы Avro — универсальный формат хранения данных в Hadoop. Данные хранятся построчно. Метаданные хранятся с данными, позволяют задавать независимую схему чтения данных. Можно переименовывать, удалять, изменять, добавлять типы данных полей. Поддерживают сжатие блоков.
RC-файлы — первый столбчатый формат в Hadoop, обладает значительными возможностями сжатия. Повышает производительность, не позволяет менять структуру. Для сохранения файлов требуется значительный объем вычислений.
Файлы ORC – это значительно оптимизированный формат файлов RC. Достигнут выдающийся размер сжатия, но также не поддерживается эволюция схемы.
Файлы Parquet – вариант столбчатых форматов, был придуман основателем Hadoop Дагом Каттингом в проекте Trevni. Также, как и все колончатые форматы обладает преимуществами сильного сжатия данных. Поддерживает частичную эволюцию схемы. Бинарный формат.
Parquetиспользует архитектуру, основанную на «уровнях определения» и уровнях повторения, что дает возможность эффективно кодировать информацию. Очень эффективно сохраняются пустые значения. Метаданные хранятся отдельно от данных.
Благодаря многоуровневой системе разбиения файлов на части реализуется параллельное исполнение важных Big Data операций (MapReduce, ввод-вывод, кодирование и сжатие)
Parquet поддерживает следующие типы данных:
- BOOLEAN – 1-битный логический;
- INT32 – 32-битные подписанные числа;
- INT64 – 64-битные подписанные числа;
- INT96 – 96-битные подписанные числа;
- FLOAT – IEEE 32-битные значения с плавающей точкой;
- DOUBLE – IEEE 64-битные значения с плавающей точкой;
- BYTE_ARRAY – произвольно длинные байтовые массивы.
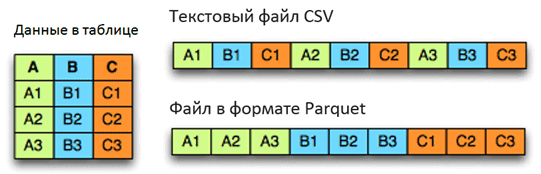
Чтобы показать, как это работает, я продемонстрирую на следующем наборе данных:
['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Почти все реализации Parquet используют для сжатия словарь по умолчанию.
Таким образом, закодированные данные выглядят следующим образом:
dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Индексы в словаре дополнительно сжимаются алгоритмом кодирования повторов:
dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
Например исходные данные, которые занимают более 1 Гб в pandas.DataFrame, со сжатием с помощью словаря занимает всего 1.5 MB
Таким образом формат Parquet:
- доступный формат для любого проекта в экосистеме Hadoop, независимо от выбора платформы обработки данных, модели данных или языка программирования
- Сокращает количество операций ввода-вывода.
- Извлекает определенные столбцы, к которым вам нужно получить доступ.
- Занимает меньше места.
Pyspark по умолчанию поддерживает Parquet в своей библиотеке, поэтому нам не нужно добавлять какие-либо библиотеки зависимостей.
Перехожу к практическим задачам, все примеры буду делать на DS машине(DatalabAI).
Создание тестового фрейма данных
Запускаю PySpark Notebook и открываю новую Spark сессию:
import pyspark
from pyspark.sql import SparkSession
spark=SparkSession.builder \
.appName("parquetFile").getOrCreate()
Формирую тестовый набор данных используя списки данных
data =[("Иванов","Иван","Иванович","11-11-11","М",50000),
("Петрова","Мария","Петровна","22-22-22","Ж",50000),
("Рублев","Рубль","Рублевич","33-33-33","М",60000),
("Сидорова","Анна","Сидоровна","44-44-44","Ж",50000),
("Рыбакова","Мария","Рыбаковна","55-55-44","Ж",40000)]
columns=["фамилия","имя","отчество","телефон","пол","зарплата"]
С помощью метода DataFrame и ранее подготовленных списков создаю тестовый DataFrame
df=spark.createDataFrame(data,columns)
df.show()
+--------+-----+---------+--------+---+--------+
| фамилия| имя| отчество| телефон|пол|зарплата|
+--------+-----+---------+--------+---+--------+
| Иванов| Иван| Иванович|11-11-11| М| 50000|
| Петрова|Мария| Петровна|22-22-22| Ж| 50000|
| Рублев|Рубль| Рублевич|33-33-33| М| 60000|
|Сидорова| Анна|Сидоровна|44-44-44| Ж| 50000|
|Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000|
+--------+-----+---------+--------+---+--------+
Сохранение фрейма данных в формат файла Parquet
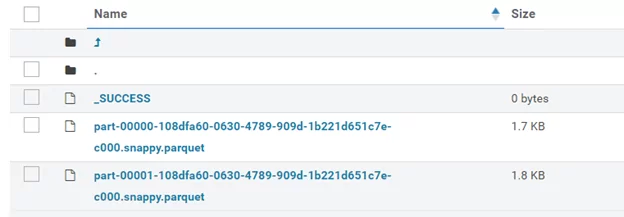
Теперь создам файл в формате Parquet из фрейма данных. Для этого вызываю функцию parquet() в качестве параметра передаю путь и имя файла, обратите внимание на режим mode(«overwrite») он заставит систему перезаписать файл в случае если такой уже существует:
df.write.mode("overwrite")\
.parquet(r"/tmp/output/people.parquet")
В результате получаю каталог с именем people.parquet и содержащий файлы Parquet:

Если есть необходимость добавить данные в существующий файл можно использовать режим mode(‘append’):
df.write.mode('append').parquet("/tmp/output/people.parquet")Чтение данных из файла Parquet в датафрейм
Привожу пример чтения данных:
df2=spark.read.parquet("/tmp/output/people.parquet")
df2.show()
+--------+-----+---------+--------+---+--------+
| фамилия| имя| отчество| телефон|пол|зарплата|
+--------+-----+---------+--------+---+--------+
| Иванов| Иван| Иванович|11-11-11| М| 50000|
| Петрова|Мария| Петровна|22-22-22| Ж| 50000|
| Рублев|Рубль| Рублевич|33-33-33| М| 60000|
|Сидорова| Анна|Сидоровна|44-44-44| Ж| 50000|
|Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000|
+--------+-----+---------+--------+---+--------+
Выполнение SQL-запросов DataFrame на Parquet файле
Загружаю наш parquet файл в датафрейм и создаю временное представление, далее считываю данные с помощью SQL запроса:
df=spark.read.parquet("/tmp/output/people.parquet")
df.createOrReplaceTempView("ParquetTable")
df2 = spark.sql("select * from ParquetTable where `зарплата` = 40000 ")
df2.show()
+--------+-----+---------+--------+---+--------+
| фамилия| имя| отчество| телефон|пол|зарплата|
+--------+-----+---------+--------+---+--------+
|Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000|
Создание таблицы из Parquet файла без использования датафрейма.
Создам временную таблицу из parquet файла с помощью SQL команды и далее прочитаю информацию из нее:
spark.sql("CREATE TEMPORARY VIEW PERS USING parquet OPTIONS (path \"/tmp/output/people.parquet\")")
spark.sql("SELECT * FROM PERSON").show()
+--------+-----+---------+--------+---+--------+
| фамилия| имя| отчество| телефон|пол|зарплата|
+--------+-----+---------+--------+---+--------+
| Иванов| Иван| Иванович|11-11-11| М| 50000|
| Петрова|Мария| Петровна|22-22-22| Ж| 50000|
| Рублев|Рубль| Рублевич|33-33-33| М| 60000|
|Сидорова| Анна|Сидоровна|44-44-44| Ж| 50000|
|Рыбакова|Мария|Рыбаковна|55-55-44| Ж| 40000|
+--------+-----+---------+--------+---+--------+
Создание таблицы в формате Parquetна Hive

Для того, чтобы узнать путь созданной таблицы, использую команду, приведенную ниже, путь будет находиться в параметре location:

Далее привожу пример чтения созданной таблицы на DS машине и сохранение в CSV файл. Обратите внимание на знак «*», он обязателен, т.к. по умолчанию создается партицированный parquet файл. После прочтения таблицы в датафрейм, преобразую его в формат Pandas и сохраняю в формате в CSV:
df=spark.read.options(inferSchema="True",header=True")\
.parquet(r"hdfs://arnsdpsbx/user/team/team_sva_oarb/hive/tablename/*")
df_res = spark_df.toPandas()
df_res.to_csv('test.csv', sep='~', encoding='cp1251', index = False)
Заключение:
Рассказал про файлы данных apache parquet в Spark, чем отличаются от других форматов, а также показал как работать с данными файлами на практике.