/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Netron поддерживает как наиболее популярные фреймворки глубокого обучения – Keras и PyTorch – так и менее известные, и даже scikit-learn.
Установка в виде сервера для python производится стандартным образом через pip. Также можно установить netron в виде отдельной программы командой.
winget install -s winget netron
(для Windows) или
snap install netron
(для Linux).
Теперь рассмотрим два базовых сценария использования данного инструмента. В первом случае возьмем готовый файл с архитектурой модели (без весов, но с Input слоем, в противном случае визуализация получится малоинформативной). Для примера выберем одну из сравнительно простых моделей классификации с небольшим количеством слоев – VGG-16
Если Netron был установлен как отдельно стоящая программа, для начала работы достаточно дважды кликнуть на файл. В случае использования сервера python импортируем библиотеку и запускаем сервер через нее:
import netron
model_path = './ vgg16_dim_ordering_tf_kernels.h5'
netron.start(model_path, 30000)
Вторым аргументом здесь указан порт, на котором запустится сервер. Если не указать его, система выберет незанятый порт по умолчанию (например, 8080). Также можно выбрать выведение логов в консоль (по умолчанию отключено) и отключить автоматический запуск браузера (по умолчанию включен). Остановка производится командой
netron.stop()Теперь можно рассмотреть модель! При старте блоки будут расположены вертикально, что может быть не совсем удобно при большом количестве слоев, поэтому поменяем ориентацию графа на горизонтальную, в результате получим такую картину:

Рассмотрим ближе один из сегментов:

Как видим, на схеме представлены как размеры входного и весовых тензоров, так и используемые активации и пулинги. Данную информацию можно дополнить, выбрав в меню опции Show Names и Show Attributes.
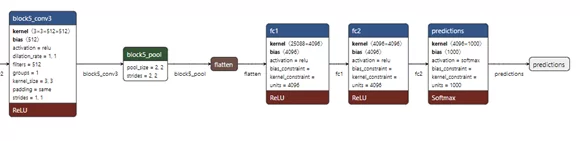
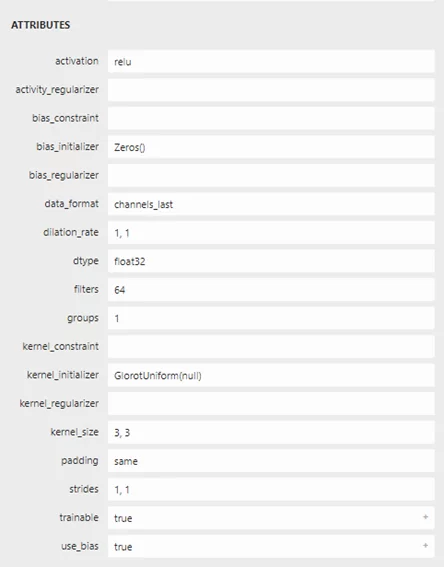
Теперь на схеме показываются также имена слоев и их параметры. Еще больше информации (используемый метод инициализации весов и др.) можно получить для каждого отдельного узла, просто кликнув по нему (иллюстрация не полная):
В качестве второго сценария использования рассмотрим ситуацию, когда самостоятельно пишем архитектуру нейросети (или один из модулей). Приведенный код (для написания используется PyTorch) реализует один из блоков модели классификации Inception. Как известно, особенностью данной архитектуры является использование сверток сразу нескольких размерностей в одном блоке с последующей конкатенацией. Для освоения подобной архитектуры хорошая визуализация придется как нельзя кстати.
import os
import numpy as np
import netron
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
class NaiveBlock(nn.Module):
def __init__(self, inp_ch: int = 256, out_ch: tuple = (128, 192, 96)) -> None:
super().__init__()
self.cov1x1 = nn.Conv2d(in_channels=inp_ch, out_channels=out_ch[0], kernel_size=1)
self.cov3x3 = nn.Conv2d(in_channels=inp_ch, out_channels=out_ch[1], kernel_size=3, padding=1)
self.cov5x5 = nn.Conv2d(in_channels=inp_ch, out_channels=out_ch[2], kernel_size=5, padding=2)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=(1, 1), padding=1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
branch1 = F.relu(self.cov1x1(x))
branch2 = F.relu(self.cov3x3(x))
branch3 = F.relu(self.cov5x5(x))
branch4 = self.maxpool(x)
out = torch.cat((branch1, branch2, branch3, branch4), 1)
print(f'Total feature maps: {out.shape[1]} of size: {out.shape[2:]}')
return out
Теперь экспортируем модель в файл:
naive_b = NaiveBlock().eval()
x = torch.Tensor(np.random.normal(size=(256, 28, 28)))
model_path = os.path.join('my_folder', inception_block.onnx')
torch.onnx.export(naive_b, torch.unsqueeze(x, 0), model_path,
input_names=['input'], output_names=['output'], opset_version=10)
После этого запускаем сервер стандартным образом через команду
netron.start(model_path)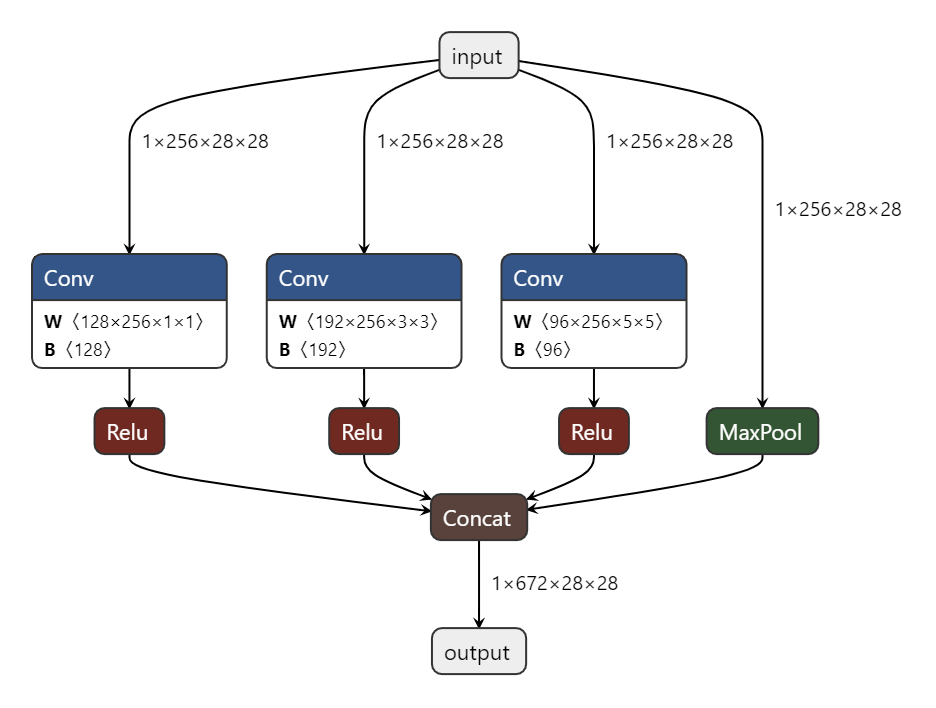
В случае множественных входов инструмент приобретает еще большую ценность.
В случае, когда у нас нет возможности установить или запустить Netron на своем компьютере, можно воспользоваться веб-версией. Также существует вариант запуска в Google Colab. Для этого после установки python-версии Netron необходимо запустить следующий код:
from google.colab.output import eval_js
port = 30000
netron.start(model_path, port)
print(eval_js(f"google.colab.kernel.proxyPort({port})"))
В результате на экран будет выведена ссылка, пройдя по которой, вы попадете на страницу Netron, запущенного из виртуальной машины Colab.
Таким образом, визуализация может быть полезна сразу в нескольких сценариях работы с моделями машинного обучения. Полученные графы можно также экспортировать в файл и делиться с коллегами. Это поможет сделать вашу работу быстрее и проще.