/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Морфологические анализаторы (они же морфологизаторы) в NLP выполняют базовые задачи, а именно определяют грамматические характеристики отдельных слов. На сегодня самые популярные python морфологизаторы это pymorphy и mystem.
По своей сути морфологизатор это словарь слов и их характеристик, это означает, что каждая словоформа каждого слова должна быть в нем представлена (для справки, в русском языке около 5 млн. словоформ). Сразу встает вопрос о структуре данных: как хранить данные используя меньше памяти и как быстро получать характеристики слов по ключам (словам). Упомянутый ранее pymorphy основан на конечных автоматах, а mystem – на префиксных деревьях. Ниже речь пойдёт о конечных автоматах.
Конечный автомат — это абстракция, состоящая из набора состояний (узлов) и переходов между ними. В один момент времени активным может быть только одно состояние, условия смены состояний представлены ребрами и помечаются меткой. Различают детерминированные и недетерминированные автоматы. В детерминированном по одной метке возможен переход только в одно состояние, в недетерминированном же наоборот – на одну метку может приходиться более одного перехода.
Автомат состоит из трёх видов состояний:
1) Начальное, круг с номером 0 – с него начинается работа автомата, может быть только одно;
2) Финальные, двойной круг – на них заканчивается работа конечного автомата (в них мы будем хранить информацию о слове);
3) Простые, обозначены кругом – промежуточные состояния.
Рассмотрим небольшой пример детерминированного конечного автомата, реализующего хранение трёх слов: деревня, дерево и дебри.
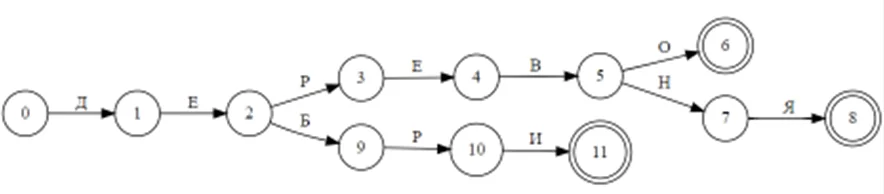
Как видно из рисунка слова «деревня» и «дерево» имеют общее начало «дерев», что позволяет «сэкономить» на хранении, также слово «дебри» имеет общую часть «де» с двумя другими. В финальных состояниях 6, 8 и 11 можно возможно хранение морфологической информации слов, если она общая для всех слов (например, мы храним только часть речи), то состояния 6, 8 и 11 можно заменить одним. Функционал конечных автоматов для языка python реализован в модуле DAWG. Установка модуля выполняется командой:
pip install DAWG-PythonНиже будет приведена реализация простого морфологизатора при помощи DAWG, который будет для слова, переданного на вход, возвращать его нормальную форму и часть речи. Для наполнения конечно автомата будет использован открытый корпус русского языка OpenCorpora, из которого возьмем все словоформы, их нормальных формы и части речи (список частей речи).
from dawg import BytesDAWG
import xml.etree.ElementTree as ET
ElementTree используется для считывания файла xml в котором хранится корпуса текста. Чтобы не считывать файл целиком, реализуем генератор, возвращающий кортеж. Первый элемент кортежа — словоформа, второе – строка с нормальной формой слова и его частью речи, разделённые нижним подчёркиванием. Например, (“деревом”, “дерево_NOUN”), где NOUN – существительное.
def fill_dawg(fpath):
for event, elem in ET.iterparse(fpath):
if elem.tag == 'lemma':
lemma_node = [node for node in elem if node.tag == 'l'][0]
lemma = lemma_node.get('t')
gramemma = lemma_node[0].get('v')
for ch_node in elem:
if ch_node.tag == 'f':
word = ch_node.get('t')
yield word, bytes(str(f'{lemma}_{gramemma}'), 'utf8')
где fpath – путь к корпусу текста.
Создание конечного автомата и его наполнение реализует следующий код:
bytes_dawg = BytesDAWG(fill_dawg (fpath))Класс BytesDAWG принимает на вход итерируемые объекты, состоящие из пар ключ-значение. Теперь можем протестировать автомат. Посмотрим выдачу на одну из форм слова «деревня»:
bytes_dawg[‘деревней’]Вывод программы:
[b’\xd0\xb4\xd0\xb5\xd1\x80\xd0\xb5\xd0\xb2\xd0\xbd\xd1\x8f_NOUN’]Результат храниться в байтах, поэтому применим метод decode:
bytes_dawg[‘деревней’][0].decode(‘utf8’)Вывод программы:
‘деревня_NOUN’Результат соответствует ожиданиям: нормальная форма – деревня, часть речи – существительное.
Модуль DAWG можно использовать и в более практических задачах, например, для хранения больших словарей. Модуль оптимизирует хранение за счёт исключения дублей общих частей слов. Кроме того, в DAWG предоставляет возможность выполнять и другие операции, например, поиск по префиксу или поиск с заменами. Применение конечных автоматов не ограничивается морфологизаторами: они лежат в основе регулярных выражений, применяются в прописывание логики искусственного интеллекта в играх, используют в валидации UI моделей и т.д.