/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
Бывает, что написали код, а он долго отрабатывает, хотя делает все верно. В таком случае предлагаем провести профилирование программы и заглянуть в стек вызовов. Процесс профилирования кода – сбор характеристик работы программы, таких как время выполнения отдельных фрагментов, число верно предсказанных переходов и т.д. Использование данного инструмента поможет нам увидеть скрытые проблемы в коде, и подскажет, на что необходимо обратить внимание в первую очередь.
Для профилирования кода разработано множество инструментов на различных языках программирования, например, CProfiler, но в рамках данной публикации мы использовали YAPPI (Yet Another Python Profiler) – библиотека для профилирования кода с поддержкой многопоточности и асинхронности, разработанная на языке программирования С.
Yappi обладает наиболее гибким API, позволяющим профилировать как весь код, так и отдельные его части. Более подробно о данной библиотеке, вы можете узнать, из документации по ссылке.
Используя данную библиотеку, мы построим отчет о работе программы и визуализируем его для наглядности. Визуализацию отчета проведем при помощи библиотеки gprof2dot. Выбранная нами библиотека является одной из не многих, кто может проводить визуализацию стека вызовов. К недостаткам данной библиотеки можно отнести неспособность прорисовать весь граф стека вызовов, в случае, когда он очень длинный. Однако этот недостаток легко нивелируется преимуществами, которые предоставляет библиотека:
- чтение большого числа форматов файлов профилировщиков;
- обрезка узлов и ребер ниже определенного порога;
- эффективное использование цветов для привлечения внимания к «особенным точкам»;
- работа на любой платформе, где присутствует Python и Graphviz.
Для более детального знакомства с данной библиотекой, предлагаем пройти по ссылке.
Посмотрим применение этих библиотек на практике. Для демонстрации возможностей мы используем два различных примера кода, в которых могут потенциально скрываться ошибки, места с наибольшим временем исполнения и т.д.
В качестве первого примера воспользуемся программой, которая осуществляет поиск дубликатов.
Рассмотрим различные варианты решения этой задачи. Исходными данными выступает список продуктов длиной в 20000 позиций с дубликатами.
Самый простой и банальный вариант решения задачи – перебор всех значений. Для этого определим функцию find_duplicates(), которая сначала считывает список продуктов из файла, а затем вызывает функцию поиска дубликатов для каждого товара в списке. Часть кода программы приведена ниже, полная версия программы доступна в репозитории GitHub по ссылке.
import yappi
# Указываем тип подсчета времени
yappi.set_clock_type('wall')
def read_file(src):
with open(src, encoding='utf-8') as fd:
return fd.read().splitlines()
def is_duplicate(item, item_list):
for product in item_list: # Перебираем весь список товаров в поиске дубликата
if item.lower() == product.lower():
return True
return False
def find_duplicates(src='products.txt'):
products = read_file(src)
duplicates = [] # Создаем пустой список для хранения дубликатов
while products:
product = products.pop() # Извлекаем последний элемент из списка
if is_duplicate(product, products):
duplicates.append(product) # Пополняем список дубликатов
return duplicates
# Начало профилирования
yappi.start(builtins=True)
find_duplicates()
# Конец профилирования
yappi.stop()
# Получаем отчет со статистикой
ypstats = yappi.get_func_stats()
# Сортируем отчет
ypstats.sort(sort_type='ttot', sort_order="desc")
# Выводим отчет в консоль
ypstats.print_all()
# Сохраняем отчет в файл в формате pstat
ver = 'products1'
ypstats.save(f"./stats/stats_pver_{ver}.stats", type="pstat")
Параллельно с программой мы использовали yappi для сбора статистик работы кода. Для запуска профилировщика необходимо использовать команды start и stop. Мы использовали функцию start() с параметром builtins. Он позволяет включить в расчет встроенные функции. Функция stop() останавливает профилирование. Его можно продолжить, снова вызвав start() в последующей части кода. Функция set_clock_type(‘wall’) производит измерение времени. Измеряем wall time, а не cpu time, так как для данного эксперимента не имеет смысла производить замеры времени с тиками процессора. Время возвращается в секундах.
Для сбора статистики используем функцию get_func_stats(), которая возвращает статистику в виде списка объектов. Полученную статистику мы сортируем в обратном порядке по полному времени выполнения функции (ttot):
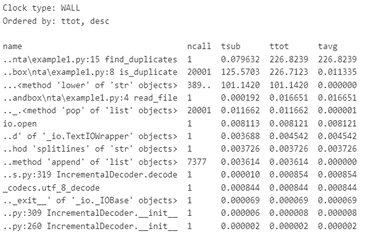
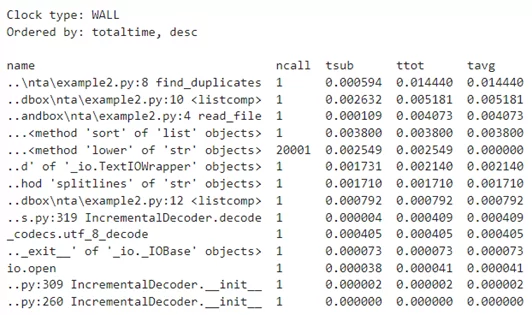
Полученная таблица с результатами профилирования имеет следующую структуру:
● name — имя вызываемой функции.
● ncall — целое число, показывающее количество вызовов функции. Это могут быть два числа через слеш. В таком случае одно число показывает количество вызовов функции без учета вызовов подфункций, а другое — общее количество вызовов функции, включая подфункции.
● tsub — время выполнение функции, исключая вызовы подфункций.
● ttot — полное время выполнения функции.
● tavg — среднее время одного выполнения функции.
В построенном отчете в первую очередь смотрим на колонки с названием функции и ttot. Все время работы программа провела в функции find_duplicates(). Однако, большая часть времени работы find_duplicates() затрачивается на исполнение is_duplicates(), которая вызывается внутри нее. Это видно в колонке tsub, которая показывает время выполнения без учета подфункций. Поэтому в оптимизации предположительно нуждается функция is_duplicates().
Полученные результаты сохраним в файл с расширением .stats, для последующей визуализации. Визуализацию отчета, произведем при помощи библиотеки gprof2dot. Для этого в терминале запустим команду:
gprof2dot -f pstats stats_pver_products1.stats | dot -Tpng -o output.pngЧто означает данная команда?
gprof2dot – обращение к пакету gprof2dot;
—f – ключ для указания формата;
pstats – выбор формата входного файла;
stats_pver_products1.stats – путь к входному файлу, который необходимо визуализировать;
dot —Tpng – преобразование входного файла, в изображение;
—o – ключ выходного файла;
output.png – путь к выходному файлу.
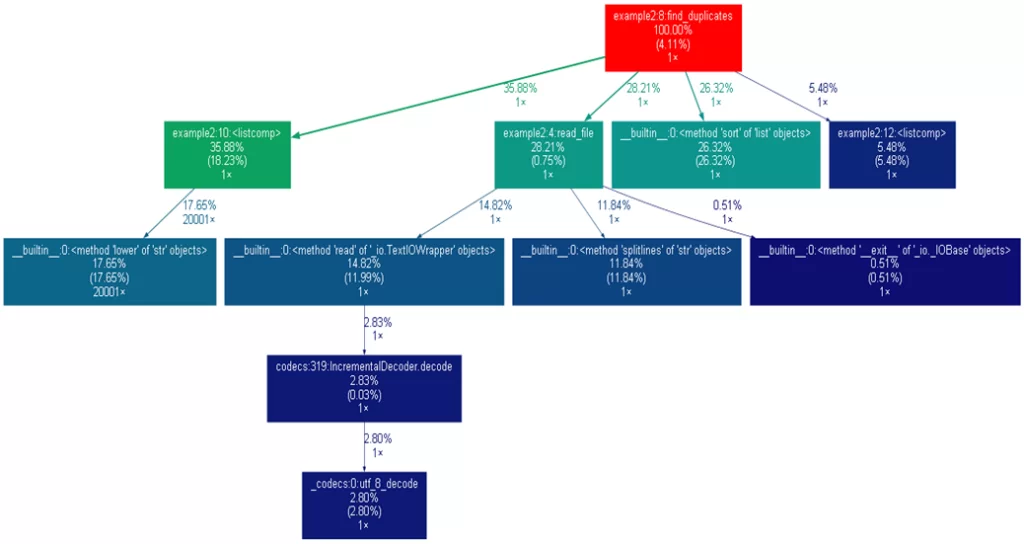
Проанализируем полученный граф:

Что показано на графе?
Функции на графе показаны в виде прямоугольников, на которых содержится следующая информация:
- Процентная доля занимаемого этой программой времени из общего времени выполнения программы, включая вызовы подфункций.
- В скобках указан процент от общего времени выполнения, затраченного только на эту функцию, без учета времени, затраченного на выполнение подфункций.
- Количество вызовов функции.
Стрелки показывают иерархию вызовов, а над стрелками указаны количество вызовов дочерней функции и процент от общего времени выполнения.
В зеленый цвет окрашены функции с наименьшим временем выполнения из тех, что представлены на графе, в красный — функции с наибольшим временем выполнения.
Наше предположение подтвердилось. Просматривая статистику работы функции is_duplicates(), мы видим, что 44 процента ее время выполнения приходится на метод понижения регистра в сравнении названий товаров, который вызывается порядка 400 миллионов раз. Здесь и кроется корень проблемы.
Как это можно пофиксить? Например, уменьшить регистр один раз для всех товаров при чтении из файла и избавиться от lower() при сравнении. Тогда данная функция вызовется 20000 раз вместо 400 миллионов. Внесем данное изменение в код, и запустим его одновременно с профилировщиком, для построения обновленного отчета. Пример скорректированного кода приведен ниже:
def find_duplicates(src='products.txt'):
products = read_file(src)
products = [product.lower() for product in products]
duplicates = [] # Создаем пустой список для хранения дубликатов
while products:
product = products.pop() # Извлекаем последний элемент из списка
if is_duplicate(product, products):
duplicates.append(product) # Пополняем список дубликатов
return duplicates
Проведем повторный запуск программы и просмотрим полученный отчет профилировщика.
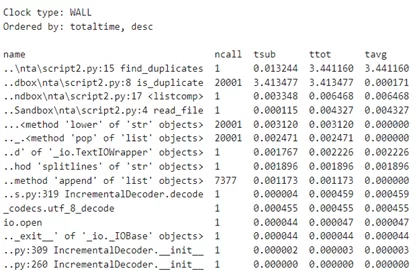
Проведя данную оптимизацию, мы получили кратное увеличение производительности. Функция is_duplicates() все еще занимает большую часть времени работы программы, при этом являясь очень простой. Для полной уверенности построим граф, который подтверждает наше предположение:

Теперь is_duplicates() нам не нужна. Проведем оптимизацию функции поиска дубликатов: будем проверять товар с оставшимися без него в списке. Пример кода, с данной оптимизацией приведен ниже:
def find_duplicates(src='products.txt'):
products = read_file(src)
products = [product.lower() for product in products]
duplicates = [] # Создаем пустой список для хранения дубликатов
while products:
product = products.pop() # Извлекаем последний элемент из списка
if product in products:
duplicates.append(product) # Пополняем список дубликатов
return duplicates
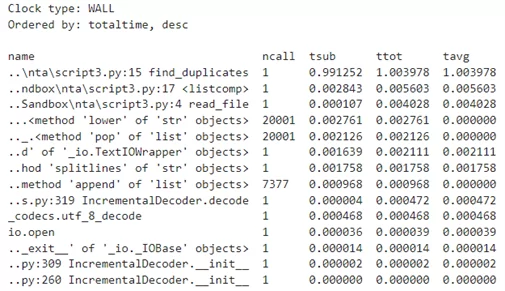
Сравним показатели текущего отчета с полученным при первом запуске программы. Очевидно кратное увеличение производительности и значительное сокращение времени выполнения кода:
Так же отметим изменение структуры графа после проведенных оптимизаций.
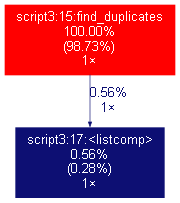
Очевидно, что больше всего времени в программе тратится на проход по всем элементам списка товаров, и в текущей версии это делается 2 раза. Поэтому при увеличении размера списка, сложность возрастет экспоненциально. Как можно это исправить? Отсортируем список товаров.
Теперь мы знаем, что одинаковые товары в списке будут идти друг за другом, и можем найти дубликаты линейным образом. Пробежимся по списку, сравнивая каждый следующий элемент с предыдущим. Оптимизированный код программы выглядит в этом случае так:
def find_duplicates(src='products.txt'):
products = read_file(src)
products = [product.lower() for product in products]
products.sort()
duplicates = [product1 for product1, product2 in zip(products[:-1], products[1:]) if product1 == product2]
return duplicates
Проанализируем отчет и граф после проведенной оптимизации. Трудно не заметить значительное увеличение производительности и значительное сокращение времени, которое составило порядка 10000 раз.
Но довольно игрушечных примеров, давайте рассмотрим реальную задачу, в которой при помощи данного анализа нам удалось исправить ошибку в коде.
Задача: pipeline обработки изображения. Pipeline взят из программы, которая исполняется на микрокомпьютере Jetson Nano. Данная программа разработана в рамках написания дипломной работы Богдановой Юлии. Ее цель — открывать дверь людям из белого списка с помощью распознавания по лицу.
Задача, следующая:
- покадрово считывается видеопоток с камеры на двери;
- в кадре производится детекция лица модулем FaceDetector;
- найденное в кадре лицо распознается модулем FaceRecognizer;
- дверь открывается, если лицо в белом списке.
Сам белый список подгружается в самом начале из базы данных, к которой мы подключаемся модулем DBConnector. Код pipeline достаточно большой, поэтому вы можете ознакомиться с ним на GitHub по ссылке.
Для запуска работы профилировщика использовали функцию start() с параметром builtins = False. Он позволяет выключить из расчета встроенные функции. В нашем случае много времени отводится на функции показа видеопотока и др. вспомогательные моменты, которые необходимы только для проверки работоспособности программы. Поэтому они для нас не важны.
Запустим программу с использованием профилировщика и посмотрим отчет:

Из отчета не трудно увидеть, что больше всего по времени занимают внутренние функции библиотеки sqlalchemy, связанные с обращением к базе, так как программа открывает очередную сессию на время, когда ей нужно считать или записать данные в базу.
Вспомогательные функции из классов FaceDetector и FaceRecognizer даже не показаны на графе, так как занимают очень мало времени.

Визуализируем получившийся стек вызовов программы с помощью gprof2dot.
Результатом работы является граф, отражающий стек вызовов:
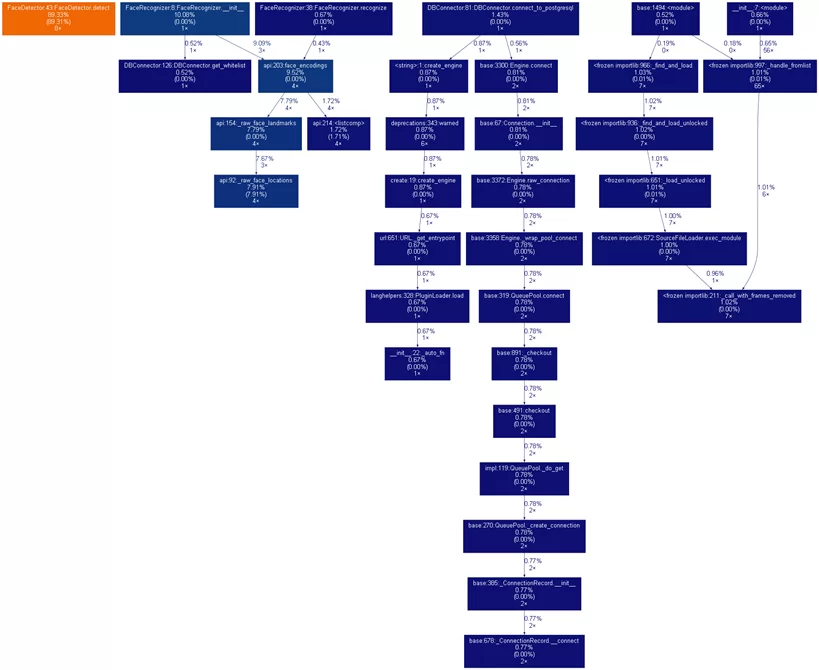
Проанализируем граф, и заметим, что подключение к базе выполняется дважды, а должно только один раз:
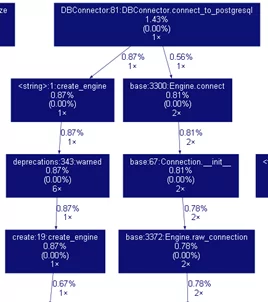
Посмотрев код, обнаружили, что при вызове функции connect_to_postgresql создается объект connection на основе объекта engine. Далее при осуществлении транзакций с базой, сессия вызывается опять с помощью engine, а не уже установленного connection. В местах совершения sql запросов заменили Session(engine) на Session(connection). В этом случае подключение производится только один раз, как и должно быть. С полной версией кода программы можно ознакомиться в репозитории GitHub по ссылке.
Повторный анализ графа подтверждает устранение ошибки:
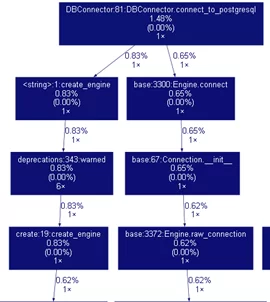
Теперь же нам удалось устранить проблему с подключением к базе данных, но какое влияние могло оказать лишнее подключение к базе?
Лишнее подключение к базе данных не мешает программе корректно выполнять свою основную задачу. Открытие нескольких соединений с одной и той же базой может влиять на производительность и создавать ненужную нагрузку на базу данных.
Кроме того, в реальности данная программа должна работать круглосуточно и непрерывно поддерживать связь с базой данных. В случае необходимости дать ей дополнительную задачу, например, сохранять историю открытия двери, таким образом, создание каждый раз отдельного подключения даст более существенную нагрузку.
Подводя итоги, хотим отметить, что нам удалось найти уязвимые места в своих программах и исправить их. В результате была проведена оптимизация программ, исправлены ошибки как в коде, так и в логике работы программ. Надеемся наш опыт будет полезен для вас.