/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Основные причины их возникновения: copy-past фрагмента программы, частое использование сложного API, повторная реализация существующих функций, слабая выразительность используемого языка, недостаток прав для модификации исходного кода. Я сам часто использую свои же куски кода из прошлых программ в новых проектах, что повышает риск распространения ошибок.
Введение в проблему.
Клон (дубликат) – это фрагмент исходного кода, который идентичен или похож на иной фрагмент в другом источнике (рис.1). Как правило, клоны размножаются в нашей кодовой базе, хотим мы этого или нет.
Пример:

Рис 1. Дубликат в коде (оригинал слева)
В IT сообществе нет чёткой сформулированной классификации типов клонирования, но одной из самых конструктивных, на мой взгляд, является предложенная ниже структура:
Типы клонов:
- Identical
Простой copy-past. С точностью до пробелов, табуляции и комментариев. - Renamed
Тоже copy-past, но чуть сложнее: с точностью до литеров, переменных констант, классов, типов, оформления и комментариев. В основном это дубликаты, которые были перенесены с изменением: название функций, переменных и возможным форматированием. - Similar
В скопированный код внесены более серьезные модификации. Это могут быть дополнительные строки или небольшие изменения в уже имеющихся. В них меняется логика и уже внутри них возникают разрывы, среди которых нужно искать схожесть. - Semantic
Functional similarity, semantic similarity. Если два участка кода делают одно и тоже, то они функционально одинаковы. Хотя написаны могут быть очень по-разному и даже на разных языках.
Дубликаты могут быть как внутри, так и между проектами, что влечет за собой следующие негативные последствия:
Появление дубликатов внутри проекта:
- Создает необходимость в преобразовании кода. Из-за большого количества клонов разработчику достаточно сложно вносить изменения в код, так как многие дубликаты взаимосвязаны. Поэтому возникают ошибки при их модификации, вследствие чего разработчику необходимо делать рефакторинг.
- Снижает качество разработки.
- Увеличивает риск внесения новых ошибок.
Появление дубликатов между проектами
- Усложняется понимание исходного кода.
- Требует контроля процессов.
- Требует архитектурного контроля.
- Повышает риск лицензионных нарушений.
Изучая проблематику анализа исходного кода «Code Mining», я заметил, что большой процент современного кода состоит из клонов.
Годами разработчики использовали в своих проектах copy-past, а затем выкладывали в общий доступ, где цикл повторялся. Легко использовать готовый код, но как же сложно его изменять и дополнять, когда он весь состоит из дубликатов, скопированных у других разработчиков. Чтобы не попасть в такую ситуацию, рассмотрим методы борьбы с клонами.
Основные подходы:
- Text-based
Основывается на простейшем анализе текстов: последовательности строк. Определяет дубликаты Type I. Пример инструмента: DUP. - Token-based
Лексический подход: Алгоритмы, основанные на этом подходе, в первую очередь получают последовательность лексических единиц – токенов – путем разбора исходного кода, после чего происходит поиск совпадающих последовательностей токенов. Определяет дубликаты Type I & II. Пример инструмента: CCFinder. - Tree-based
Построение AST-деревьев (Abstract Syntax Tree) и их сравнение. Определяет дубликаты Type I & II. Пример инструмента: CloneDR. - PDG (program dependency graph)
Построение PDG и их сравнение. У таких алгоритмов большая производительность, но более низкая точность, чем у AST. Возможно определение дубликатов всех типов. Пример инструмента: PDG-DUP. - Metric-based
Расчет разных метрик и их сравнение, напрямую код не сравнивается. Возможно определение дубликатов всех типов, но с нестабильным качеством. Подобное исследование приведено в данной статье . - ML-based
Обучаются модели для отдельных типов клонов и технологий. Возможно определение дубликатов всех типов. Пример инструмента: CLONEGEN .
В открытом доступе есть немало статей на тему клонов, но, к сожалению, последняя актуальная статья про дубликаты опубликована на Хабре в 2015 году, когда еще не было создано большинство инструментов. Поэтому рассмотрю какие на данный момент существуют актуальные решения.
Открытые инструменты для поиска клонов Type I & II :
Все эти инструменты можно встраивать в continuous integration-delivery как открытые, так и вендорские решения, чтобы контролировать количество дубликатов в кодовой базе.
Рассмотрю один из инструментов, приведенных выше, который более чем актуален на данный момент.
Clone Digger
Clone Digger является одним из первых инструментов обнаружения клонов, ориентированным на Python.
Алгоритм (рис.2) работает на уровне абстрактных синтаксических деревьев, а именно считает, что две последовательности операторов образуют клон, если одна из них может быть получена из другой заменой некоторых поддеревьев. Это позволяет учесть всю информацию о синтаксической структуре программы. В настоящее время инструмент поддерживает языки Python и Java. Clone Digger бесплатен и предоставляется под лицензией General Public License. Ознакомится с инструментом можно здесь
Пример работы алгоритма:
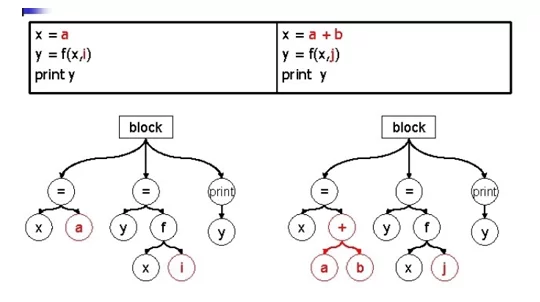
Рис 2. Оригинальный код слева, справа дубликат, ниже синтаксическое дерево
На данный момент разработчик не обновлял инструмент, поэтому нет поддержки Python 3, но есть рабочий форк на GitHub, скачать проект можно с репозитория по ссылке.
Clone Digger очень прост в использовании. Чтобы его запустить для поиска дубликатов, нужно:
- при запуске из редактора кода:
import clone_digger_py3
clone_digger_py3.main(path_to_file_or_folder) - если запускаем из терминала:
python clone_digger_py3/main.py path_to_file_or_folderДействия алгоритма можно регулировать в зависимости от поставленной задачи, благодаря настраиваемым параметрам. Основные из них приведены ниже:
- —-no-recursion не проходит направление рекурсивно.
- —distance-threshold максимальное количество различий между парой последовательностей в паре клонов (по умолчанию 5). Большее значение приводит к большему количеству ложных срабатываний.
- —hashing-depth глубина хеширования (по умолчанию 1). Вычисления можно ускорить, увеличив это значение (но некоторые клоны могут быть пропущены).
- —size-threshold минимальный размер клона. Размер клона в свою очередь равен количеству строк кода в его самом большом фрагменте.
- —fast найти только клоны, отличающиеся именами переменных и функций и константами.
- —ignore-dir не сканирует избранные директории.
В результате инструмент предоставляет отчет в виде файла html или XML (можно настроить с помощью параметра —output).
В качестве примера представлен отчет о коде, написанном на языке python несколькими разработчиками.
В отчете представлены:
- информация о количестве клонов и времени выполнения:

Рис 3. Входные заданные параметры и время поиска дубликатов
дубликаты с указанными путями к файлам с найденными клонами (отображаются визуально):

Рис 4. Клоны тип 1 в коде и путь к ним сверху
клоны type III&IV (отмечены красным цветом):
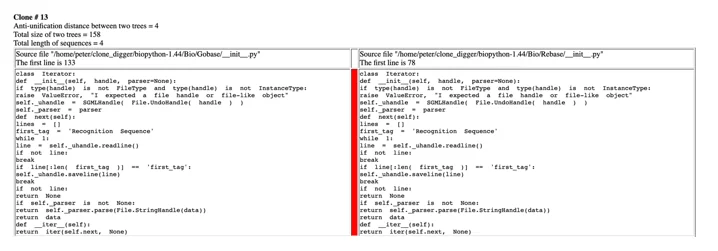
Рис 5. Клоны тип 3 в коде и путь к ним выше
Также следует обратить внимание на инструмент CloneDR, созданный с помощью инструмента DMS, который идентифицирует не только точные, но и почти неиспользуемые дубликаты в программных системах и может использоваться на самых разных языках. Он найдет клоны даже там, где используются другое форматирование, другие имена переменных и даже другие фрагменты кода. К сожалению, данный продукт распространяется только на коммерческой основе.
Возможности CloneDR:
- Исчерпывающее сравнение файлов во всех системах.
- Доступно для разных языков и диалектов.
- Параметризован для определения точного совпадения или близкого совпадения в указанном диапазоне различий.
- Клоны можно фильтровать по пороговому размеру.
- Определяет схемы параметризации для сопоставления потенциальных клонов.
- Использует технологию компиляции, а не сопоставление строк, поиск клонов независимо от измененных комментариев, пробелов, разрывов строк и изменений регистра.
- Обнаруживает клоны в процедурном коде и/или объявлениях данных.
- Поддерживает анализ тысяч файлов/миллионов строк кода, используя параллельные вычисления с несколькими процессорами.
- Работает под Windows на однопроцессорном компьютере, но широко использует возможности симметричного многопроцессорного режима (SMP).
- Интеграция Eclipse для языков IBM Enterprise.
В данном посте я рассмотрел проблему дублирования кода и методы борьбы с клонами. Тема не настолько однозначна, как может показаться на первый взгляд, необходимо понимать, что дублированный код ведет за собой массу последствий. Основная проблема, исходя из всего выше перечисленного, что код с большим количеством клонов затрудняет последующее использование и модификацию программ для разработчиков. Приведу пример из собственного опыта.
Был проанализирован репозиторий с кодом нескольких проектов более чем на 10 тысяч строк и 100 файлов. Выявлен достаточно большой процент (38%) дубликатов между проектами. Это связано с едиными подходами и стандартами к исполнению проектов. При более детальном рассмотрении, выяснилось, что первый и второй проект выполняла одна команда разработки, которая переносила лучшие практики из одного проекта в другой, вместо того, чтобы вынести свои решения в отдельные компоненты (функции, процедуры), которые могли бы использоваться всеми участниками разработки. В результате, из-за такого количества дубликатов, пострадали качество и поддерживаемость решений, также было усложнено сопровождение проектов.
Поэтому устранение дубликатов в коде, действительно важная задача для каждого разработчика, чтобы сделать код программы проще и понятнее.