/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
Код программ отличается от естественного языка из-за его формализма и строгости, однако ничто не мешает воспринимать его как последовательность токенов и работать с ним, как с обычным языком. Существуют исследования, которые показали, что модель BERT, обученная на большом наборе данных, неплохо справляется с некоторыми задачами, связанными с обработкой программного кода. В этом посте я буду решать задачу автогенерации комментариев к нему. Вы узнаете, как подготовить данные для обучения, настроить нейросеть и получить результат.
Данные
Данные представлены в виде набора пар [функция — комментарий] для различных языков программирования (awesome Code Search Net Challenge dataset). Кстати говоря, этот набор изначально был создан не для этой задачи, однако его можно легко перепрофилировать под свои нужды.
| Данные | Цель |
| public string getlhsbindingtype(final string var) { if (this.lhs == null) { return null; } for (int i = 0; i < this.lhs.length; i++) { string type = getlhsbindingtype(this.lhs[i], var); if (type != null) { return type; } } return null; } | get the data-type associated with the binding |
Мы не будем очищать данные, это описано здесь. Мы же буду использовать уже предварительно обработанные данные в объеме 1 % от общего количества образцов в наборе, так как обучение модели занимает довольно много времени. Но, как можно будет убедиться в будущем, генерация комментариев даже на 1 % данных выглядит неплохо. Если у вас есть время и ресурсы, можете обучить модель на всём наборе и получить результаты получше.
CodeBERT
Предварительно обученная модель, которую мы будем использовать, взята из статьи исследовательского подразделения Microsoft. В этой модели также использовался набор данных CodeSearchNet, но вместо генерирования комментариев он использовался для обучения модели на основе RoBERTa удобному для восприятия представлению кода и естественного языка. Использование больших языковых моделей для представления текста удобным способом в настоящее время является обычной практикой, поскольку они показали свою эффективность для решения других задач.
А вот и код
Загрузка, установка и импортирование библиотек
!pip install transformers
!git clone -q https://github.com/microsoft/CodeXGLUE.git
import json
from dataclasses import dataclass
import numpy as np
import pandas as pd
from transformers import AutoTokenizerЗдесь прописываем пути до файлов с данными и оборачиваю их в структуру для более удобного дальнейшего использования:
PATH_TO_TRAIN_DATA = '/content/train.csv'
PATH_TO_TEST_DATA = '/content/test.csv'
PATH_TO_VALIDATION_DATA = '/content/validation.csv'
#validation, test and train
data_struct = {
'train' : pd.read_csv(PATH_TO_TRAIN_DATA),
'test' : pd.read_csv(PATH_TO_TEST_DATA),
'valid' : pd.read_csv(PATH_TO_VALIDATION_DATA)
}Инициализируем две вспомогательные функции: токенизации текста и записи DataFrame в JSON-файл, так как именно в таком формате требуется подавать данные для модели.
}
def write_into_json_file(json_file_name: str, data: pd.DataFrame):
'''
json_file_name - name output json file
data - pandas data frame
write your pandas data to json file
'''
with open(json_file_name, 'w') as current_file:
for index, current_row in data.iterrows():
current_file.write(json.dumps(current_row.to_dict()) + '\n')
def split_data(split_column: str, new_column: str, data: pd.DataFrame)-> pd.DataFrame:
'''
split items in column
data - your pandas data frame
split_column - column in your pd.df
'''
data[new_column] = data[split_column].apply(lambda current_item: current_item.split())
return dataРеализуем небольшую предобработку данных с помощью функций, описанных выше:
#preproc data
for type_data, value in data_struct.items():
#split target colums
code_tokens_step = split_data('code', 'code_tokens', value)
docs_tokens_step = split_data('comment', 'docstring_tokens', code_tokens_step)
data_struct[type_data] = docs_tokens_step
#create json file
write_into_json_file(f'/content/{type_data}.jsonl', data_struct[type_data])Создадим конфигурационный класс для модели и на его основе прописываю всю конфигурацию:
@dataclass
class ConfigurationModel:
learning_rate : float
batch_size : int
beam : int
test_file : str
source_size : int
target_size : int
path_to_data_directory : str
path_to_output_data_directory : str
train_file : str
dev_file : str
count_epochs : int
pretrained_model : str
configuration_codetext_model = ConfigurationModel(
learning_rate = 5e-5,
batch_size = 8,
beam = 10,
source_size = 256,
target_size = 512,
path_to_data_directory = '.',
path_to_output_data_directory = 'model_for_java',
train_file = '/content/train.jsonl',
dev_file = '/content/valid.jsonl',
test_file = '/content/test.jsonl',
count_epochs = 10,
pretrained_model = 'microsoft/codebert-base',
)
configuration_codetext_modelРезультат:

Обучение
Теперь, когда данные обработаны и представлены в удобном формате, можно приступать к обучению. Обучим модель на обучающей выборке. В качестве метрики использую BLEU-4 (четвёрка означает, что количество словесных n-gram = 4), которая распределена от 0 до 1, но в нашем примере будет использоваться BLEU-4 * 100%. Эта метрика используется в задачах машинного перевода, но и для генерации текста она также хорошо подходит. Если брать задачи машинного перевода, то даже для человека bleu = [0.6:0.7] — отличный результат, потому что каждый человек может перевести текст по-разному. Точности в единицу достигнуть почти невозможно.
Если посмотреть на исходную задачу, то, во-первых, модель должна сгенерировать текст, а во-вторых, это не просто текст, а осмысленный комментарий к коду. Поэтому ожидать больших значений метрики bleu не стоит.
#run train model
!python /content/CodeXGLUE/Code-Text/code-to-text/code/run.py \
--do_train \
--do_eval \
--do_lower_case \
--model_type roberta \
--model_name_or_path {configuration_codetext_model.pretrained_model} \
--train_filename {configuration_codetext_model.train_file} \
--dev_filename {configuration_codetext_model.dev_file} \
--output_dir {configuration_codetext_model.path_to_output_data_directory} \
--max_source_length {configuration_codetext_model.source_size} \
--max_target_length {configuration_codetext_model.target_size} \
--beam_size {configuration_codetext_model.beam} \
--train_batch_size {configuration_codetext_model.batch_size} \
--eval_batch_size {configuration_codetext_model.batch_size} \
--learning_rate {configuration_codetext_model.learning_rate} \
--num_train_epochs {configuration_codetext_model.count_epochs}Результат:
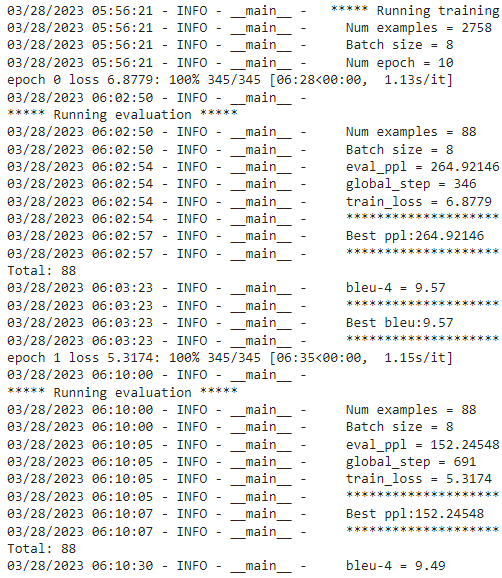
После обучения модели её можно проверить на валидационной выборке:
binary_model_file = '/content/model_for_java/checkpoint-best-bleu/pytorch_model.bin'
!python /content/CodeXGLUE/Code-Text/code-to-text/code/run.py \
--do_test \
--model_type roberta \
--model_name_or_path microsoft/codebert-base \
--load_model_path {binary_model_file} \
--dev_filename {configuration_codetext_model.dev_file} \
--test_filename {configuration_codetext_model.test_file} \
--output_dir {configuration_codetext_model.path_to_output_data_directory} \
--max_source_length {configuration_codetext_model.source_size} \
--max_target_length {configuration_codetext_model.target_size} \
--beam_size {configuration_codetext_model.beam} \
--eval_batch_size {configuration_codetext_model.batch_size}
Результат проверки модели на валидационной выборке:

Как можно увидеть, bleu-4 = 11, и это неплохо для такой задачи, даже с учётом того, что bleu в нашем случае распределена от 0 до 100.
Далее считаем получившиеся результаты:
path_to_gold = '/content/model_for_java/test_1.gold'
path_to_output = '/content/model_for_java/test_1.output'
Инициализируем функцию считывания из txt-файла:
def read_result_txt_file(txt_file: str)-> list:
with open(txt_file) as file:
return [' '.join(line.rstrip().replace('\t', ' ').split(' ')[1:]) for line in file]
И для удобства считаем всё в DataFrame:
def read_result_txt_file(txt_file: str)-> list:
#true comments and predicted
true_sent = read_result_txt_file(path_to_gold)
pred_sent = read_result_txt_file(path_to_output)
result_data_frame = pd.DataFrame(
{
'code' : data_struct['test']['code'],
'true' : true_sent,
'pred' : pred_sent
}
)
result_data_frame.head(10)
Теперь попробую субъективно сравнить оригинальный комментарий со сгенерированным по шкале от 1 до 5. Code — исходный код, true — исходный комментарий, pred — сгенерированный.
Пример 1:
Code: public t includeas(final class template) { blacklist = false; string[] properties = getallbeanpropertynames(template, false); include(properties); return _this(); }
True: defines included property names as public properties of given template class. sets to black list mode.
Pred: create a new resource
Оценка: 1 – абсолютно не понятно о чем идет речь.
Пример 2:
Code: int setdirect(int v0, int v1, int v2, int v3, int v4) { return offset + v0*stride0 + v1*stride1 + v2*stride2 + v3*stride3 + v4*stride4; }
True: experimental : should be package private
Pred: sets the value for the specified point.
Оценка: 4 – исходный комментарий абсолютно никак не отражает функционал, в отличии от сгенерированного.
Пример 3:
Code: static private servicetype checkifdap4(string location) throws ioexception { // strip off any trailing dap4 prefix if (location.endswith(«.dap»)) location = location.substring(0, location.length() — «.dap».length()); else if (location.endswith(«.dmr»)) location = location.substring(0, location.length() — «.dmr».length()); else if (location.endswith(«.dmr.xml»)) location = location.substring(0, location.length() — «.dmr.xml».length()); else if (location.endswith(«.dsr»)) location = location.substring(0, location.length() — «.dsr».length()); try (httpmethod method = httpfactory.get(location + «.dmr.xml»)) { int status = method.execute(); if (status == 200) { header h = method.getresponseheader(«content-type»); if ((h != null) && (h.getvalue() != null)) { string v = h.getvalue(); if (v.startswith(«application/vnd.opendap.org»)) return servicetype.dap4; } } if (status == httpstatus.sc_unauthorized || status == httpstatus.sc_forbidden) throw new ioexception(«unauthorized to open dataset » + location); // not dods return null; } }
True: check for dmr
Pred: returns true if the given name is valid.
Оценка: 5 – попадание в точку.
Пример 4:
Code: public void setsize(dimension newsize) { if ( newsize != null ) { size.setsize( newsize ); firepropertychange( size_prop, null, size ); } }
True: set the size of this vertex. will not update the size if newsize is null.
Pred: sets the initializes the size of the shape.
Оценка: 3 – в целом комментарии схожи, но вместо vertex используется shape и в сгенерированном комментарии не отражено условие, которое прописано в оригинальном.
Пример 5:
Code: protected bufferedimage createbufferedimage(int w, int h, int imgtype) { bufferedimage bi = null; if (imgtype == 0) { bi = (bufferedimage) createimage(w, h); } else if ((imgtype > 0) && (imgtype < 14)) { bi = new bufferedimage(w, h, imgtype); } else if (imgtype == 14) { bi = createbinaryimage(w, h, 2); } else if (imgtype == 15) { bi = createbinaryimage(w, h, 4); } else if (imgtype == 16) { bi = createsgisurface(w, h, 32); } else if (imgtype == 17) { bi = createsgisurface(w, h, 16); } // store the buffered image size biw = w; bih = h; return bi; }
True: generates a fresh buffered image of the appropriate type.
Pred: creates a new image.
Оценка: 2 – в исходном комментарии сказано что генерируется новое буферное изображение определенного типа, в сгенерированном такие уточнения отсутствуют.
Пример 6:
Code: public orientgraph gettx() { final orientgraph g; if (pool == null) { g = (orientgraph) gettxgraphimplfactory().getgraph(getdatabase(), user, password, settings); } else { // use the pool g = (orientgraph) gettxgraphimplfactory().getgraph(pool, settings); } initgraph(g); return g; }
True: gets transactional graph with the database from pool if pool is configured. otherwise creates a graph with new db instance. the graph instance inherits the factory’s configuration.
Pred: get the graph for the graph.
Оценка: 1 – очень краткое и в тоже время неверное описание.
Пример 7:
Code: public boundingbox getboundingbox(long geopackageid, string tablename) { boundingbox boundingbox = null; cursor result = db.rawquery(«select min(» + geometrymetadata.column_min_x + «), min(» + geometrymetadata.column_min_y + «), max(» + geometrymetadata.column_max_x + «), max(» + geometrymetadata.column_max_y + «) from » + geometrymetadata.table_name + » where » + geometrymetadata.column_geopackage_id + » = ? and » + geometrymetadata.column_table_name + » = ?», new string[]{string.valueof(geopackageid), tablename}); try { if (result.movetonext()) { boundingbox = new boundingbox(result.getdouble(0), result.getdouble(1), result.getdouble(2), result.getdouble(3)); } } finally { result.close(); } return boundingbox; }
True: query for the bounds of the feature table index
Pred: get the bounding box.
Оценка: 3 – в целом суть похожа.
Пример 8:
Code: public static list<element> getelements(stage stage, iterable<? extends module> modules) { recordingbinder binder = new recordingbinder(stage); for (module module : modules) { binder.install(module); } binder.scanforannotatedmethods(); for (recordingbinder child : binder.privatebinders) { child.scanforannotatedmethods(); } // free the memory consumed by the stack trace elements cache stacktraceelements.clearcache(); return collections.unmodifiablelist(binder.elements); }
True: records the elements executed by
Pred: returns the list of the given
Оценка: 3 – в целом суть похожа.
Пример 9:
Code: static proofnode<owlaxiom> canconvertstep(proofstep<owlaxiom> step) { if (step.getname() != elkclassinclusionexistentialcomposition.name) { return null; } list<? extends proofnode<owlaxiom>> premises = step.getpremises(); proofnode<owlaxiom> lastpremise = premises.get(premises.size() — 1); collection<? extends proofstep<owlaxiom>> lastpremisesteps = lastpremise .getinferences(); if (lastpremisesteps.size() != 1) { return null; } // else for (proofstep<owlaxiom> lastpremisestep : lastpremisesteps) { if (lastpremisestep .getname() == elkpropertyinclusionoftransitiveobjectproperty.name) { return lastpremisestep.getpremises().get(0); } } // else return null; }
True: checks if is derived by inference where the last premise is derived from
Pred: determine if the expression has been cleared.
Оценка: 2 – не очень похоже на правду, но сгенерированный комментарий вполне осмысленный.
Пример 10:
Code: public string asjsonstring(object o) { if ( getcoderspecific() instanceof jsonfactory == false ) { return «can be called on jsonconfiguration only»; } else { return new string(asbytearray(o), standardcharsets.utf_8); } }
True: utility/debug method. use «asbytearray» for programmatic use as the byte array will already by utf-8 and ready to be sent on network.
Pred: convert a json string to a json string.
========================================
Code: private void notifylisteners(string str) { writerlistener[] writerlisteners = null; synchronized (listeners) { writerlisteners = new writerlistener[listeners.size()]; listeners.toarray(writerlisteners); } for (int i = 0; i < writerlisteners.length; i++) { writerlisteners[i].write(str); } }
True: notify that a new string has been written.
Pred: notifies all listeners.
Оценка: 1 – модель не смогла уловить суть.
Средняя субъективная оценка:(1+4+5+3+2+1+3+3+2+1)/10 = 2.5 – вполне неплохой результат для модели, которая училась на 1% от общего объема тренировочных данных. В целом суть сгенерированных комментариев понятна, но если у вас есть ресурсы, чтобы обучить модель более чем на 1% данных, вы можете улучшить данный результат.
Заключение
Мы показали, что после обучения модели даже на 1 % данных она выполняет свою цель и может вполне адекватно генерировать комментарии к коду. Также продемонстрирована предварительная обработка текста для языка Java. Если модель будет использоваться в исследовании целой кодовой базы, то лучше её всё же обучить на всех данных.
Также следует сказать, что если обучить модель на большем объёме, то её можно встроить в IDE (VisualStudio, PyCharm и т.д.) Подробнее об этом можно посмотреть здесь.