/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Рано или поздно место на диске склонно заканчиваться. Так однажды и произошло у меня дома: места на ноутбуке стало едва хватать для установления обновлений, а внешний диск на 1Тб заполнился на 95%. Стало очевидно — нужен новый внешний диск. Но сначала решил попробовать оптимизировать хранение файлов в текущих условиях. Бывает так, что делаешь резервную копию, а потом еще одну, но в другое время, и чтобы не рисковать потерей данных включаешь на всякий случай в список и папку, которую уже недавно копировал. Например, мой кот постоянно попадает в объектив, а потом я время от времени скидываю папку с фотографиями с телефона на жесткий диск. Таким образом появилась задача нахождения дубликатов файлов, и хорошо, что часть пространства на SSD моего ноутбука была занята не зря — пригодилась Anaconda, а для прототипа решения — стандартная Python-библиотека hashlib.
В процессе написания скрипта дополнительно возник вопрос, а какие еще (помимо хеша) атрибуты файла необходимо читать. Чтобы не усложнять и одновременно не удлинять продолжительность обработки, было решено брать только самое существенное: полное имя файла, название родительской папки, полный путь к файлу и его размер. Метод hashlib.algorithms_guaranteed возвращает список доступных алгоритмов хеширования. Среди них, в частности: ‘sha256’, ‘sha1’, ‘sha512’, ‘md5’, ‘shake_256’. В дальнейшем использовался ‘sha256’.
def calc_hash(file, block_size=2**18):
"""
Вычисление хэша для файла.
Размер блока для обработки задан параметром block_size.
Тип алгоритма хеширования (sha256) задан внутри.
"""
file_hash = hashlib.sha256()
with open(file, 'rb') as f:
fb = f.read(block_size)
while len(fb) > 0:
file_hash.update(fb)
fb = f.read(block_size)
return (file_hash.hexdigest())
Сведения об обработанных файлах записывались с помощью библиотеки logging в текстовый файл с разделителем точка с запятой.
def init_logging(log_name, filename, level):
"""
Создаем логгер для записи событий: обработки одного файла.
"""
logger = logging.getLogger(log_name)
logger.setLevel(level)
_log_format = f'%(asctime)s: [%(levelname)s]: %(message)s'
_date_format = '%Y-%m-%d %H:%M:%S'
file_handler = logging.FileHandler(filename, mode='w', encoding='utf8')
file_handler.setLevel(level)
file_handler.setFormatter(logging.Formatter(_log_format, _date_format))
logger.addHandler(file_handler)
return logger
В итоге, обработав все разделы всех имеющихся у меня встроенных и переносных накопителей и выделив расширение файла в отдельный столбец для анализа, я получил таблицу, содержащую сводную информацию о своих файлах. Ключ для определения уникальности файла было решено задавать по двум текстовым столбцам — Имя_файла + хеш_файла. Ура! Диски оказались очищены от дубликатов файлов. И фотографий котов, в частности 🙂
Но это — только начало истории. Спустя некоторое время на работе возникла задача преобразования в текст большой коллекции pdf-документов. И коллега заметил, что внутри иерархической структуры папок есть похожие вложенные папки и похожие документы. При этом, похожесть внешне есть, но нет никаких гарантий, что файлы полностью идентичные. А объемы документов немаленькие — общий размер папок измеряется гигабайтами. Т.е. возникла такая же задача поиска дубликатов в большом наборе файлов.
В этот момент вспомнилась моя домашняя наработка. После применения скрипта из Jupyter Notebook к нашей задаче общее количество документов сократилось в некоторых случаях в полтора-два раза, а для отдельных наборов данных количество файлов уменьшилось в 5-7 раз. После первых успехов в использовании в исходный скрипт были внесены доработки:
- для возможности обработки длинных имен файлов стали использоваться UNC-пути (Universal Naming Convention, универсальное соглашение об именовании). Использование префикса «\\?\» в начале полного пути к файлу позволило избежать ошибок при сочетании большой глубины вложенности папок вместе с длинными названиями файлов. Например, путь C:\Users\user-id начинает выглядеть как \\?\C:\Users\user-id и на его длину уже нет ограничения в 260 символов.
- расширен список рассматриваемых атрибутов файла: добавлены «Время создания», «Время изменения», «Время последнего доступа»,
file_ctime = localtime(os.path.getctime(full_path)) # created at
file_atime = localtime(os.path.getatime(full_path)) # accessed
file_mtime = localtime(os.path.getmtime(full_path)) # modified
а также «Расширение файла» и «Размер в Мб».
- добавлена функция копирования только уникальных экземпляров файлов в отдельную папку с сохранением иерархической структуры папок источника с помощью функционала библиотеки pathlib.
def get_dest_name(source_f, dest_f, full_filename):
"""
В папке source_f находится структура, которую нужно
сохранить при копировании в папку dest_f.
Работаем с полным путем к одному из файлов -- full_filename.
----------
Возвращаем новое полное имя в целевой папке с учетом вложенности
исходного пути.
Возвращаем None, если переданы несовпадающие логические пути источника
и находящегося в нем файла."""
try:
path_sf = PurePath(source_f)
path_file = PurePath(full_filename)
second_part = path_file.relative_to(path_sf)
except:
# Напр, если путь к файлу не дочерний по отношению к папке-источнику
return None
return PurePath(dest_f).joinpath(second_part)
Полученный текстовый файл с хешами и другой полезной информацией о файлах преобразуется с помощью библиотеки pandas в табличное представление:
def csv_to_datafr_proc(file_in):
"""
Читаем путь к csv, обрабатываем,
возвращаем обогащенный датафрейм.
"""
df = pd.read_csv(file_in,
sep=';',
encoding='utf8',
header=None,
names=['Folder', 'Full_path',
'Type', 'Size_bytes', 'Hash',
'ctime', 'atime', 'mtime'])
try:
# Приводим все расширения файлов к нижнему регистру
df.Type = df.Type.apply(lambda x: str(x).lower())
df['Drive'] = df.Folder.apply(lambda x: PurePath(str(x)).parts[3]
if len(PurePath(str(x)).parts)>3 else "-")
df['File'] = df.Full_path.apply(lambda x: os.path.basename(str(x)))
df['dir'] = df['Full_path'].apply(lambda x:
os.path.dirname(str(x)).split('/')[-1])
# Ключ из двух полей: имя файла_хеш
df['key_fn_hash'] = df['File'].astype('str') + '_' + df['Hash']
# Размер файла в Мб, округленный до десятых
df['MegaBytes'] = np.round(df['Size_bytes'] / 1048576, 1)
except:
print('error')
print('df.shape:', df.shape)
return df
Преобразование csv-лога в датафрейм для последующего сохранения в формате Excel.
А полученную таблицу можно сохранить в формате Excel для удобной работы в дальнейшем:
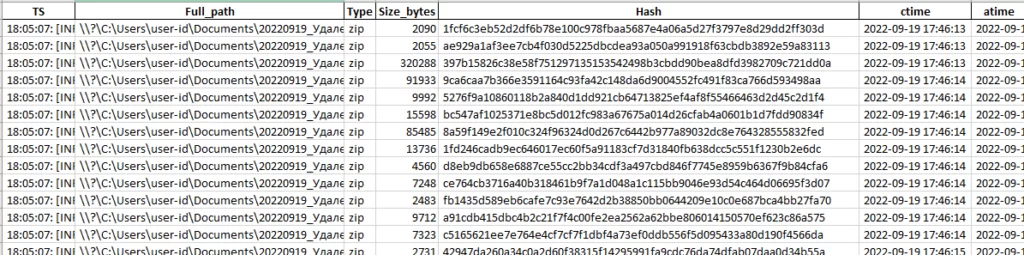
Первые несколько строк таблицы-результата, полученной в результате работы скрипта.
Теперь при необходимости удаления дубликатов файлов в нашем отделе есть простой в использовании инструмент, а процесс распознавания документов значительно ускорился.
А недавно этот же скрипт я использовал для того, чтобы понять, какие папки и файлы занимают ощутимую часть ограниченного на АРМ (и тем более ВАРМ) дискового пространства. Это позволило удалить старые ненужные объемные csv и убрать в архив пока еще нужные, но активно не используемые.
Ознакомиться с полной версией кода в формате Jupyter Notebook можно по ссылке.