/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Нужно найти в docx-файле определенный фрагмент и оставить к нему комментарий? bayoo-docx (форк python-docx) умеет это! В конце в виде бонуса расскажу, как определить номер страницы. 😊
Долгое время в библиотеке python-docx отсутствовала возможность добавления комментариев к word-файлам «из коробки». Созданное еще в 2014 году обсуждение в репозитории python-docx о том, как добавлять комментарии, было довольно активным, но не было найдено решений без прямого вмешательства в xml-разметку. Однако в 2020 году появился форк от python-docx – bayoo-docx, позволяющий добавлять комментарии быстро и легко.
Начнем с установки bayoo-docx:
!pip install bayoo-docxДля сравнения строк будет использоваться thefuzz, о нем можно почитать здесь. Если кратко, то он осуществляет сравнение двух строк и возвращает процент похожести, используя расстояние Левенштейна. Устанавливается следующей командой:
!pip install thefuzz[speedup]Импортируем необходимые модули:
from docx import Document
from thefuzz import fuzz
import ctypes
ctypes используем для определения текущего полного имени пользователя, что необходимо для более наглядного вида комментария.
Желательно, чтобы был пример, с которым можно поиграться (по себе знаю, как тяжело бывает разобраться без реальных примеров).
Давайте создадим такой документ для теста:
# создание пустого документа
doc = Document()
Объект Document представляет собой весь документ – его структура:
- Список объектов paragraph – абзацы документа
- Список объектов run – фрагменты текста с различными стилями форматирования (курсив, цвет шрифта и т.п.)
- Список объектов table – таблицы документа
- Список объектов row – строки таблицы
- Список объектов cell – ячейки в строке
- Список объектов cell.paragraphs содержит все абзацы в ячейке
- Список объектов column – столбцы таблицы
- Список объектов cell – ячейки в столбце
- Список объектов InlineShape – иллюстрации документа
# добавляем абзацы
doc.add_paragraph('Первый абзац, первая страница')
doc.add_paragraph('Второй абзац, первая страница')
doc.add_paragraph('Третий абзац, первая страница')
# добавляем разрыв страницы
doc.add_page_break()
# добавляем абзацы на второй странице
doc.add_paragraph('Первый абзац, вторая страница')
doc.add_paragraph('Второй абзац, вторая страница')
doc.add_paragraph('Третий абзац, вторая страница')
# данные таблицы без названий колонок
items = (
(1, 'первая строка', 'первая строка'),
(2, 'вторая строка', 'вторая строка'),
(3, 'третья строка', 'третья строка'),
)
# добавляем таблицу с одной строкой
# для заполнения названий колонок
table = doc.add_table(1, len(items[0]))
# определяем стиль таблицы
table.style = 'Light Shading Accent 1'
# Получаем строку с колонками из добавленной таблицы
head_cells = table.rows[0].cells
# добавляем названия колонок
for i, item in enumerate(['первая колонка', 'вторая колонка', 'третья колонка']):
p = head_cells[i].paragraphs[0]
# название колонки
p.add_run(item).bold = True
# выравниваем посередине
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
# добавляем данные к существующей таблице
for row in items:
# добавляем строку с ячейками к объекту таблицы
cells = table.add_row().cells
for i, item in enumerate(row):
# вставляем данные в ячейки
cells[i].text = str(item)
# сохраняем тестовый файл с которым будем работать
doc.save('test.docx')
Вид созданного документа:
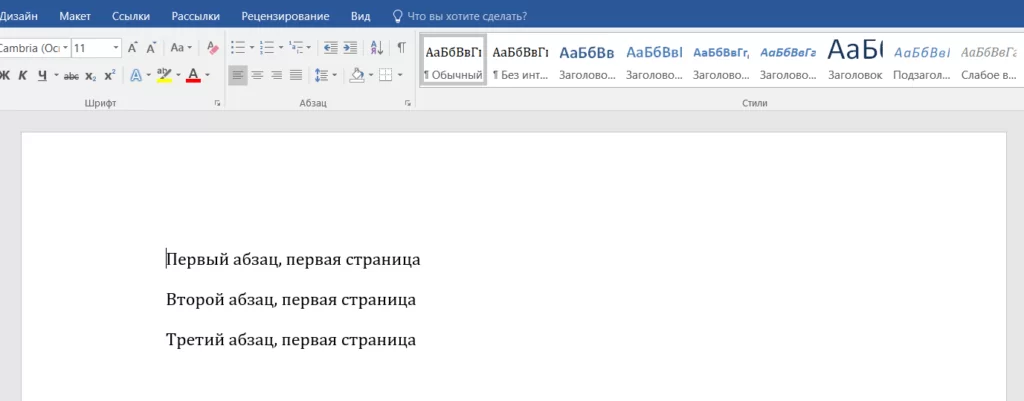
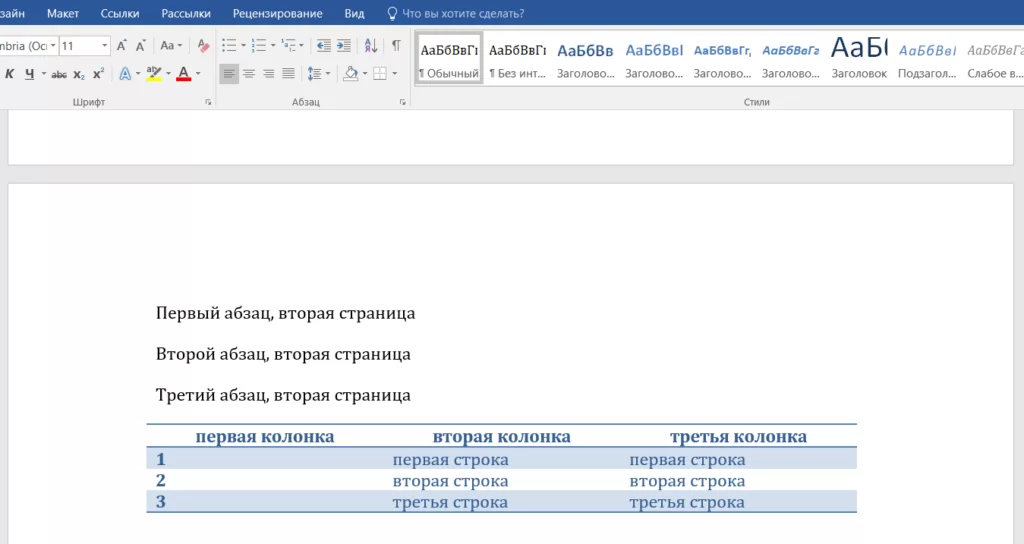
Вторая страница
Напишем функцию, которая будет проходить по списку document.elements (содержит список всех объектов документа) и добавлять в него все объекты paragraph (абзацы), а из таблиц извлекать все объекты paragraph, которые лежат в ячейках.
Объекты тестового файла:
# содержание списка elements
for element in doc.elements:
print(element)
<docx.text.paragraph.Paragraph object at 0x0000026F87D13580>
<docx.text.paragraph.Paragraph object at 0x0000026F87D13550>
<docx.text.paragraph.Paragraph object at 0x0000026F87D13BB0>
<docx.text.paragraph.Paragraph object at 0x0000026F87D13790>
<docx.text.paragraph.Paragraph object at 0x0000026F87D138B0>
<docx.text.paragraph.Paragraph object at 0x0000026F87D13400>
<docx.text.paragraph.Paragraph object at 0x0000026F87D13AF0>
<docx.table.Table object at 0x0000026F87D13B50>
<docx.section.Section object at 0x0000026F87D13D30>
Список списков с абзацами нужен из-за того, что добавление комментариев к абзацу в тексте и в таблице осуществляется с небольшими различиями и, конечно, чтобы сэкономить строчки кода. Ячейки в таблице устроены таким образом, что могут содержать короткую строку, но из нескольких абзацев, и в каждом абзаце содержатся прогоны (runs), которые нужно склеить и получить полный текст ячейки для осуществления поиска.
Функция сбора абзацев из файла:
def filter_element(document):
"""
This function take all paragraphs in file.
:param document: object of document
:return: list of paragraphs in file.docx - document
"""
res = []
for element in document.elements:
if 'paragraph' in str(element):
res.append(element)
elif 'table' in str(element):
for row in element.rows:
for cell in row.cells:
res.append(cell.paragraphs)
return res
Функция определения полного имени пользователя:
def get_display_name():
"""
This function return full name of user.
out:
string: full name of user
"""
get_user_name_ex = ctypes.windll.secur32.GetUserNameExW
name_display = 3
size = ctypes.pointer(ctypes.c_ulong(0))
get_user_name_ex(name_display, None, size)
name_buffer = ctypes.create_unicode_buffer(size.contents.value)
get_user_name_ex(name_display, name_buffer, size)
return name_buffer.value
И, наконец, основная функция поиска строки и добавления комментария:
def make_comment(text:str, paragraphs:list, user:str):
"""
This function adds comments in docx files.
:param text: the line we are looking for
:param paragraphs: list of paragraphs to search for a string
:param user: full name of user
"""
for paragraph in paragraphs:
if type(paragraph) == list:
text_in_table = [p.text for p in paragraph]
text_in_table = ''.join(text_in_table)
if len(text_in_table) >= len(text)-5:
res = fuzz.partial_ratio(text.lower(), text_in_table.lower())
if res >= 97:
p = paragraph[-1]
run = p.add_run()
run.add_comment('Строчка которую искали', author=user)
else:
if len(paragraph.text) >= len(text):
res = fuzz.partial_ratio(text.lower(), paragraph.text.lower())
if res >= 97:
paragraph.add_comment('Строчка которую искали', author=user)
Загрузим объект тестового файла в переменную document:
document = Document('test.docx')Строка для поиска:
text = 'Первый абзац, первая страницы'Список абзацев для поиска:
paragraphs = filter_element(document)Сохраняем полное имя пользователя в переменную name_of_user:
name_of_user = get_display_name()Вызываем функцию и передаем аргументы (искомая строка, список абзацев, полное имя пользователя):
make_comment(text, paragraphs, name_of_user)Сохраняем изменения в новый файл:
document.save('test с комментарием.docx')Появилась копия файла с комментарием:
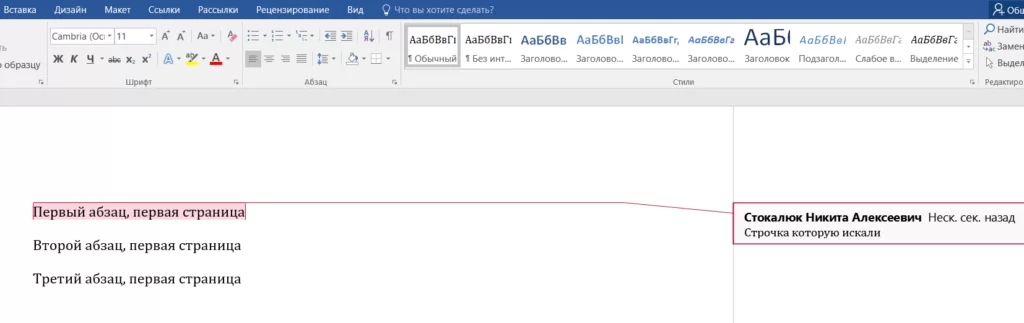
Давайте попробуем найти строчку в таблице:
# объект документа
document = Document('test.docx')
# строчка которую ищем
text = "Первая строка"
# список абзацев для поиска
paragraphs = filter_element(document)
# полное имя пользователя
name_of_user = get_display_name()
# вызываем функцию добавления комментарий
make_comment(text, paragraphs, name_of_user)
# сохраняем изменения в файл .docx
document.save('test с комментарием.docx')
Результат:

Комментарий будет сделан к каждому совпадению.
Обещанный бонус
Не все функции можно реализовать «из коробки», например, определить номер страницы строки, которую я нашёл, ☹ так легко не получится. В таких случаях на помощь приходят «костыли» 😉.

Разрывы страницы бывают двух видов:
- hard breaks – разрывы, вставленные с помощью Ctrl + Enter.
- soft breaks – разрывы, вставленные, когда автор печатал текст, и произошел автоматический переход на новую страницу.
Обнаружить эти два вида разрыва страницы можно в xml-разметке объектов run (run._element.xml), которые есть у каждого объекта paragraph.
Напишем функцию определения номера страницы для искомой строки:
def number_page(text:str, paragraphs:list):
"""
This funcion find number page.
:param text: string what we find
:param paragraphs: list of paragraphs
:return: pages
"""
pages = []
number_page = 1
for paragraph in paragraphs:
if type(paragraph) == list:
text_in_table = [p.text for p in paragraph]
text_in_table = ''.join(text_in_table)
for p in paragraph:
for run in p.runs:
if 'lastRenderedPageBreak' in run._element.xml:
number_page += 1
elif 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
number_page += 1
if len(text_in_table) >= len(text)-10:
res = fuzz.partial_ratio(text.lower(), text_in_table.lower())
if res >= 97:
pages.append(number_page)
else:
for run in paragraph.runs:
if 'lastRenderedPageBreak' in run._element.xml:
number_page += 1
elif 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
number_page += 1
if len(paragraph.text) >= len(text):
res = fuzz.partial_ratio(text.lower(), paragraph.text.lower())
if res >= 97:
pages.append(number_page)
return ', '.join(map(str, pages))
Вот здесь XML-разметка объекта run проверяется на наличие тегов, указывающих на наличие разрыва страницы:
if 'lastRenderedPageBreak' in run._element.xml:
number_page += 1
elif 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
number_page += 1
Как и в прошлый раз, подготавливаем данные для функции:
# создаем объект document
document = Document('test.docx')
# снова собираем в список абзацы документа
paragraphs = filter_element(document)
# строка номер которой хотим найти
text = "Первая строка"
Для нахождения номера страницы нужно передать в функцию number_page первым аргументом строку, которую искали, вторым – список paragraphs.
print(number_page(text, paragraphs))Результатом вывода будут номера страниц через запятую, на которых нашлась строка.
Jupyter notebook с подробными комментариями к коду доступен по ссылке.
Форк bayoo-docx расширяет возможности python-docx, позволяя вставлять комментарии без особых усилий. К сожалению, функция поиска номеров страниц пока отсутствует, т.к. разрывы страниц генерируются автоматически движком. Все же, немного покопавшись в самой структуре docx, можно реализовать дополнительный функционал вручную.