/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Мы говорим Big Data, подразумеваем — Apache Spark. Сейчас это, пожалуй, самый мощный и модный фреймворк для распределённой обработки больших данных в задачах Data Science, поэтому для всех аналитиков как никогда важна задача изучения Spark и получения практических навыков работы с ним. Однако привычная среда обитания Spark — это, как правило, серверные кластеры промышленного масштаба под управлением Linux, что, несомненно, слегка усложняет работу с ним в уютных домашних условиях. Но нет ничего невозможного. В этой статье мы научимся ставить PySpark на локальную машину c ОС Windows и использовать его (на примере задачи векторизации и сравнения текстов алгоритмом Word2Vec, входящим в библиотеку mllib).
- Установка Spark на ОС Windows
Шаг 1. Установка Java JDK
Так как Spark в основе своей работает на Java-машине, то нужно иметь установленную в системе Java JDK. Для этого посмотрите в «Программах и компонентах», есть ли в списке установленных программ строка «Java(TM) SE Development Kit 8.x.x.», а на диске C папка «C:\Program Files\Java\jdk-8.x.x» (в обоих случаях версия должна быть 8 или больше). Если нет, переходите по адресу, нажимайте ссылку «JDK download». На странице скачивания загружайте исполняемый файл с описанием «Windows x64 Installer» и устанавливайте его.
Шаг 2. Установка Apache Spark
Для скачивания Spark перейдите по адресу:

По умолчанию в строке «1. Choose a Spark release» будет стоять последняя рабочая версия Spark (на сегодняшний день это 3.1.2, соответственно, дальше по тексту все названия папок и файлов будут с этим номером).
В строке «2. Choose a package type» выберите «Pre-built for Apache Hadoop 2.7». Затем в строке «3. Download Spark» щёлкните по ссылке «spark-3.1.2-bin-hadoop2.7.tgz» и скачайте файл с дистрибутивом Spark.
Внутри скачанного архива находится папка «spark-3.1.2-bin-hadoop2.7». Распакуйте её, например, WinRAR-ом (или любым другим архиватором, умеющим в zip). Создайте на диске C папку «С:\spark» и скопируйте в неё распакованную папку «spark-3.1.2-bin-hadoop2.7».
Шаг 3. Установка утилиты winutils.exe
Так как Spark разрабатывался для работы в среде Hadoop, то специально для Windows энтузиасты сделали его сборку, которая позволяет Spark-у работать на Windows-машине как на одиночном Hadoop-кластере. Для работы в среде Hadoop 2.7 скачайте файл «winutils.exe» по ссылке и положите его в папку «С:\spark\spark-3.1.2-bin-hadoop2.7\bin».
Шаг 4. Создание папки c:\tmp\hive
Создать папку «С:\tmp\hive» нужно для того, чтобы Spark не падал с ошибкой об отсутствии Hadoop Hive. То есть, у нас-то он отсутствует в любом случае, но ошибок об этом возникать не будет. Для корректной работы перейдите в папку «С:\spark\spark-3.1.2-bin-hadoop2.7\bin» и выполните в командной строке:
winutils.exe chmod -R 777 C:\tmp\hivewinutils.exe ls -F C:\tmp\hive
Шаг 5. Изменение переменных окружения
Далее нужно создать переменные окружения пользователя, необходимые для корректной работы Spark…
SPARK_HOME = C:\Spark\spark-3.1.2-bin-hadoop2.7
HADOOP_HOME = C:\Spark\spark-3.1.2-bin-hadoop2.7
JAVA_HOME = C:\Program files\Java\jdk-x.x.x
…и добавить в переменную PATH пути:
C:\Spark\spark-3.1.2-bin-hadoop2.7
C:\Program files\Java\jdk-x.x.x
Внимание! Имена путей нужно указывать точно такие же, как и у вас в системе!
После этого перезагрузите компьютер.
Шаг 6. Установка PySpark
Для работы со Spark в Python нужно установить PySpark:
pip install pyspark
Шаг 7. Устранение неочевидных подводных камней
Из линуксовой природы Python-а, Spark-а и PySpark-а вытекает одна особенность (которая, впрочем, может проявиться не у всех). При установке Python 3.x на Linux в системе создаётся так называемая «жёсткая ссылка» с именем «python3», указывающая на исполняемый модуль Python вне зависимости от того, куда он установлен. Таким образом, если выполнить в командной строке Linux команду «python3», то в любом случае запустится интерпретатор Python версии 3.xx.
Неожиданно выяснилось, что при работе в Windows PySpark пытается внутри себя запустить интерпретатор Python как раз по имени «python3», что вызывает ошибку выполнения скрипта, т.к. данный исполняемый модуль не может быть найден в системе. Для устранения этой проблемы необходимо скопировать исполняемый модуль python.exe, установленный в системе, в ту же самую папку установки, но только с именем python3.exe.
В случае, если вы работаете с Jupyter Notebook (или с другим инструментом) , запускаемым из пакета Anaconda нужно скопировать файл С:\ProgramData\Anaconda3\python.exe. Если вы работаете в PyCharm или другом отдельно стоящем инструменте, то скопируйте python.exe файл (или делайте это в той папке, куда была выполнена локальная установка Python)
Шаг 8. Запуск Spark в коде Python
Запустим Jupyter Notebook, создадим новый ноутбук и выполним следующий код:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
conf = SparkConf()
conf.setMaster("local").setAppName('My app')
sc = SparkContext.getOrCreate(conf=conf)
spark = SparkSession(sc)
print('Запущен Spark версии', spark.version)
Если всё было выполнено правильно, то создастся Spark-сессия и появится сообщение:
Запущен Spark версии 3.1.2
Также по адресу запустится web-сервер с панелью управления нашим свежеиспечённым Saprk-кластером, состоящим из одной ноды:
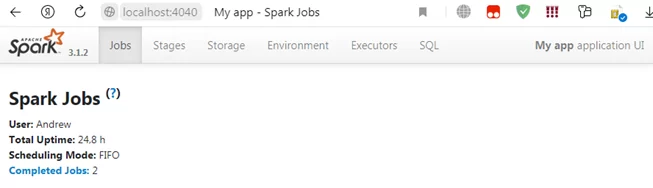
Поздравляю, у вас всё получилось, вы великолепны. А теперь попробуем на практическом примере обработать с помощью Spark данные, хранящиеся на диске Windows-машины.
- Работа с Word2Vec из пакета MlLib PySpark
Для примера возьмём случай из жизни.
В ходе проверки для установления того факта, что разные документы могут принадлежать одному клиенту, понадобилось сравнить адреса, указанные в этих документах. Разумеется, адреса могли быть записаны в произвольной форме, с ошибками, мусорными и незначащими словами и символами, и т.д., и т.п.
Например, если в разных документах указаны адреса «Город Подольск Московской области» и «Москва обл. г\подолск» — то, скорее всего, это один и тот же адрес, а если «Город Подольск Московской области» и «Город Пинск Брестской области» — то это явно разные адреса, несмотря на одинаковую форму записи. Кроме того, если адрес совпадал по нескольким компонентам (например, область и район, или город и улица), но не совпадал по другим компонентам, то это также было признаком того, что, возможно, это один и тот же адрес, просто некорректно указанный.
Для сравнения таких адресов было решено использовать очистку строк от мусора и незначащих фрагментов, токенизацию (разбиение на отдельные значащие компоненты, в нашем случае – на одиночные слова) и, самое главное — представление токенизированных строк в виде числовых векторов с последующим сравнением косинусного расстояния между ними.
Векторизацию строк выполняли старым добрым методом Word2Vec. Реализация этого метода, как и многих других, встроена в PySpark в библиотеку mllib, и, так же, как и у многих других, не представляет никаких трудностей для практического использования в коде Python.
Итак, just do it.
Сначала положим в рабочий каталог csv-файл, содержащий набор строк с адресами, подлежащими сравнению (для служебных целей добавим столбец, содержащий единицы).
Файл «spark_test_data.csv»:
a;id
1;пос. Пригородный обл.Воронежская калачеевский, р-н
1;респ. Мордовия, Саранская обл ленинскиЙ р, с.петровка
1;калач п.пригородный
1;Мордовия, р/н.Саранский пос. Рабочий
Далее напишем следующий код в Jupyter Notebook (в дополнение к коду инициализации spark-сессии, который был приведён выше).
from pyspark.sql.functions import udf
from pyspark.sql.types import ArrayType, StringType
from pyspark.ml.feature import Word2Vec
from scipy.spatial.distance import cosine
import pyspark.sql.functions as F
Загрузим данные, создадим датафрейм, покажем его состав и структуру.
data = spark.read.load('documents/spark_test_data.csv', format = 'csv', sep = ';', inferSchema = 'true', header = 'true')
data.show(truncate = False)
data.printSchema()

Далее объявим UDF-функцию токенизации строковых полей. Предварительно удаляем мусорные знаки препинания и сокращённые наименования типов населённых пунктов, разбиваем на слова по пробелам, оставляем элементы с длиной больше одного символа, на выходе получаем отсортированный по алфавиту список с элементами поля — отдельными словами.
def splitter(inStr):
if inStr is None:
inStr = 'пустой адрес'
splt = sorted(inStr.lower()\
.replace('гор.', ' ')\
.replace('край', ' ')\
.replace('края', ' ')\
.replace('кв.', ' ')\
.replace('"', ' ')\
.replace('\\', ' ')\
.replace('/', ' ')\
.replace('*', ' ')\
.replace('_', ' ')\
.replace('.', ' ')\
.replace(',', ' ')\
.replace('-', ' ')\
.replace('?', ' ')\
.replace('пос', ' ')\
.replace('пгт', ' ')\
.replace('аул', ' ')\
.replace('район', ' ')\
.replace('село', ' ')\
.replace('област', ' ')\
.replace('обл', ' ')\
.replace('республик', ' ')\
.replace('респ', ' ')\
.split(' '))
res = [x for x in splt if len(x) > 1]
if len(res) == 0:
return ['пустой адрес']
return res
tokenizer_udf = udf(lambda x: splitter(x), ArrayType(StringType()))
Объявим UDF-функцию вычисления косинусного расстояния между векторами в полях датафрейма:
cosine_udf = udf(lambda x, y: abs(float(1 - cosine(x, y))))Преобразуем исходный датафрейм: токенизируем поле с адресами и свяжем каждую запись с каждой, чтобы показать, как будет меняться сходство между разными адресами.
df = data
df = df.select('a', 'id', tokenizer_udf('id').alias('tok_id'))
df = df.join(df.select('a', F.col('tok_id').alias('tok_id2')), on = 'a', how = 'fullouter')
df.select('tok_id', 'tok_id2').show(truncate = False)

Как мы видим токенизатор очистил адреса от мусора и разбил на значащие элементы (названия элементов адреса – области, района, города и т.д.). Теперь векторизуем и сравним смежные поля с токенизированными адресами в преобразованном датафрейме и посмотрим, насколько Word2Vec справится с возложенной на него задачей.
Выполняем векторизацию, устанавливаем число размерностей в пространстве векторизации vectorSize = 100, минимальное число включений токена в словарь модели minCoiunt = 5:
word2Vec = Word2Vec(vectorSize = 100, minCount = 5, inputCol = 'tok_id', outputCol = 'vec_id')
model = word2Vec.fit(df)
df = model.transform(df)
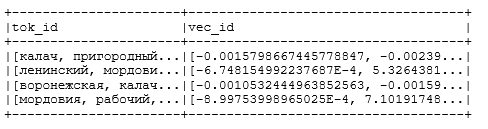
df.select('tok_id', 'vec_id').distinct().show()
word2Vec = Word2Vec(vectorSize = 100, minCount = 5, inputCol = 'tok_id2', outputCol = 'vec_id2')
model = word2Vec.fit(df)
df = model.transform(df)
Получаем на выходе следующую модель векторизации (вектора показаны не полностью, не все 100 элементов, т.к. тогда они бы просто не влезли в текст статьи):
Вычисляем косинусное расстояние между векторами и записываем результат сравнения в новый столбец:
df = df.withColumn('similarity', cosine_udf('vec_id', 'vec_id2'))
df.select('tok_id', 'tok_id2', 'similarity').orderBy(F.col('similarity').desc()).show(truncate = False)
Получаем на выходе следующий результат:

Как видим, модель прекрасно справилась со своей задачей — мало того, что сходство между одинаковыми адресами было рассчитано как 100% (что очевидно), но и адреса с элементами из одной области и района тоже были отнесены к весьма схожим. А вот сходство между адресами, которые вообще не содержат отдельных похожих элементов, упало ниже 13%.
В самом конце не забудем выключить нашу spark-сессию, чтобы освободить ресурсы кластера для других пользователей (на самом деле других пользователей на нашей машине, конечно же, нет, но правила хорошего тона диктуют выполнять данную процедуру каждый раз при завершении расчётов, что является весьма полезной привычкой при работе на кластерах общего пользования):
sc.stop()Итак, мы научились запускать Spark на Windows и использовать в практических целях модель Word2Vec, встроенную в Spark, что может весьма облегчить практику изучения этого инструмента и использования его для работы с текстами, содержащимися в хранилищах больших данных.