/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Немного об организации. Прежде чем принять участие в основном туре хакатона, нужно было решить тестовое задание и пройти отбор. Далее на выбор предлагается 20+ задач, каждая из которых попадает в одну из трех оцениваемых номинаций: визуализация данных, аналитика данных, программное решение. Мы приняли решение написать инструмент мониторинга систематических проблем граждан при получении госуслуг.
Мониторинг удовлетворенности гражданами государственными услугами происходит посредством количественных оценок. Помимо возможности произвести данную оценку, граждане могут оставить свой отзыв об услуге, ведомстве или отдельном сотруднике в текстовом виде. Обезличенный датасет с информацией об оценках и комментариях был предоставлен организаторами.
Работа с датасетом была разделена на 2 части. Первая: анализ статистических данных, собранных на основе оценок клиентов, отображенных на сайте. Например, средние значения показателей по услугам или количество комментариев. Вторая: анализ текстов комментариев и выявление проблем. Для второй части были взяты комментарии, длина слов в которых превышает 4, а также у которых есть хоть по одному из аспектов негативная оценка (<=3).
Выявление проблем из комментариев осуществлялось методом выделения актуальных и популярных хештегов методами машинного обучения (с применением моделей кластеризации). Использовалась модель LDA.
В качестве метрик применялись C_V(Coherence, «Согласованность») и Perplexity («Перплексия»). Ниже представлен фрагмент кода, где осуществляется подсчет ключевых метрик качества обучаемой модели Python3:
def compute_both_values(dictionary, corpus, texts, limit, start=start, step=step):
perplexity_values = []
coherence_values = []
model_list2 = []
for num_topics in trange(start, limit, step):
model=LdaMulticore(corpus=corpus,id2word=dictionary, num_topics=num_topics, iterations=iterations, workers=8)
model_list2.append(model)
perplexity_values.append(model.log_perplexity(corpus))
coherencemodel1 = gensim.models.CoherenceModel(model=model, texts=texts,
dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel1.get_coherence())
return model_list2, perplexity_values, coherence_values
model_list2, perplexity_values, coherence_values = compute_both_values(dictionary=dictionary,
corpus=corpus, texts=bigram_text, #text_clean,
start=start, limit=limit, step=step)
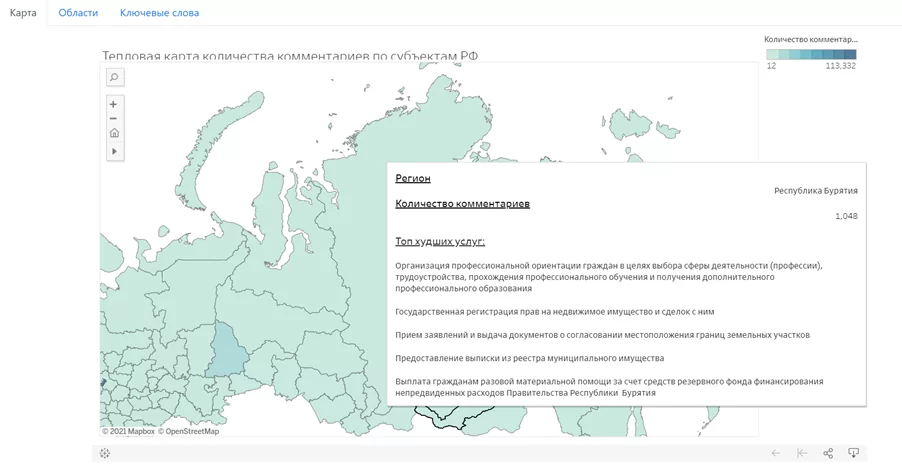
В результате работы модели были получен топ популярных хэштегов. Например, невозможно_дозвониться или длинный_очередь_стоять. Наш инструмент предоставляет возможность посмотреть статистику в разрезе областей и услуг. При нажатии на область отображается краткая статистика по этой области. Сейчас на карте отображаются 2 показателя:
- средний рейтинг удовлетворенности,
- число комментариев.
А также список услуг, которые можно получить в данной области (топ услуг с самым низким средним баллом).
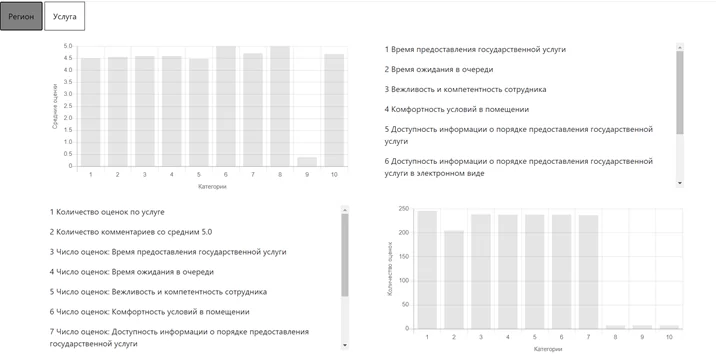
Можно кликнуть на услугу и получить информацию об этой услуге в выбранной области.
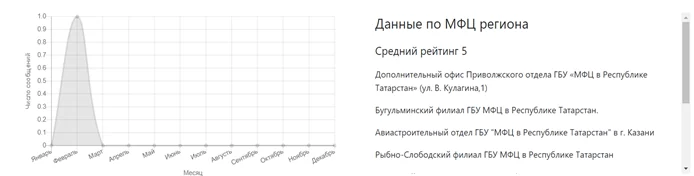
В качестве инструмента для визуализации использовался инструмент Tableau Public (предоставляется бесплатно), а также библиотеки D3.js, Chart.js. Пример графика на основе таблиц с Chart.js на JavaScript:
chart3 = new Chart(ctx3, {
type: 'line',
data: {
labels: ['Январь', 'Февраль', 'Март', 'Апрель', 'Май', 'Июнь', 'Июль', 'Август', 'Сентябрь', 'Октябрь', 'Ноябрь', 'Декабрь'],
datasets: [{
data: month_statistic
}]
},
options: {
legend: false,
scales: {
yAxes: [{
stacked: true,
scaleLabel: {
display: true,
labelString: 'Число сообщений'
}
}],
xAxes: [{
stacked: true,
position: 'bottom',
scaleLabel: {
display: true,
labelString: 'Месяц'
}
}]
}
}
})
Из минусов стоит отметить, что, так как рабочие книги Tableau сохраняются на публичном сервере tableau вместе со всей информацией и визуализациями, то никакой защиты нет (от слова «совсем»). Но в нашем случае это не было проблемой, так как данные, с которыми мы работали, были взяты с открытых источников.