/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Представляю вашему внимаю обзор на соревнование Global Wheat Challenge 2021, а также делюсь своим опытом участия в нем.
О соревновании.
Данное соревнование проводилось на площадке aicrowd.com, аналоге kaggle, и организатором был университет Саска́чеван. Денежные призы присуждались за первые три места: 1) 2000$; 2) 1000$; 3) 1000$.
Перед участниками стояла задача детектирования колосьев пшеницы на изображениях. Лучшая модель должна заместить ручной труд в задачах ученых-селекционеров и фермеров. На основе выхода работы нейронной сети ученым и фермерам будет легче посчитать их метрику качества плодородности пшеницы и выбрать наилучшую культуру для того или иного региона мира. В конечном итоге это должно повысить урожайность.
Стоит сказать, что это не первое соревнование, организованное этим университетом в рамках данной задачи. Так, например, в прошлом году он так же проводил соревнование на площадке kaggle.
Датасет
Набор данных состоит из более чем 6000 изображений с разрешением 1024х1024 пикселей, содержащих свыше 300 тыс. уникальных колосьев пшеницы. Изображения получены из 11 стран и охватывают 44 уникальных сеанса измерений. Сеанс измерения — это набор изображений, полученных в одном и том же месте в течение нескольких часов. По сравнению с конкурсом 2020 года на Kaggle, он представляет 4 новые страны, 22 новых сеанса измерений, 1200 новых изображений и 120 тыс. новых голов пшеницы. Стоит отметить, что распределение между test и train было не стратифицировано относительно сеансов измерений, то есть в test попали изображения из стран и временных периодов, не встречающихся в train. Так организаторы пытались подтолкнуть участников создавать робастный метод детекции.
Критерии оценки
Метрикой качества в данном соревновании выступала средняя точность по сеансам измерений. Для каждой картинки высчитывалась средняя точность:
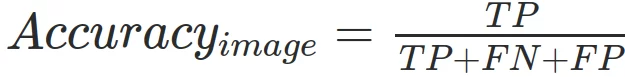
Рамка считалась истинно найденной если Intersection over Union (IoU) > 0.5. Далее точность усреднялась по всем картинкам выбранного домена и далее по всем доменам. Более подробно можно почитать на сайте соревнования.
Опыт участия
Первым делом были проанализированы лучшие решения прошлых соревнований. Было принято решение отталкиваться от реализации EfficientDet, и в частности от реализации Alex`я Shonenkov`а(отдельное огромное спасибо ему!). Первые результаты тестов представлены в таблице, результаты приводятся на основе кросс-валидации (k=5):
| train_loss | valid_loss | Publick liderboard (mean) | |
| effdet5_512 | 0.365 | 0.353 | 0.681 |
| effdet6_768 | 0.358 | 0.371 | 0.742 |
| effdet7_768 | 0.344 | 0.381 | 0.720 |
| effdet6 896* | — | — | 0.754 |
| effdet6 1024* | — | — | 0.739 |
*- провести валидацию на всех 5 фолдах не удалось ввиду затратности по времени обучения каждого фолда.
Вычислительные мощности использовались Google Colaboratory Pro. Тренировали нейронные сети со смешанной точностью с батчем 2 для экономии видеопамяти и ускорения вычислений. Однако, даже так не удалось обучить все 5 фолдов из-за нехватки времени.
Стоит сказать, что к середине соревнования я нашел единомышленника, который так же участвовал в данном мероприятии и мы сформировали команду. Так я узнал, что yolov4 (scaled yolov4) незначительно уступает efficientDet`у. В итоге мы решили отказаться от YOLO и сфокусироваться на efficientDet, возможно это наша главная ошибка, но обо все по порядку.
Одним из основных факторов к победе был правильный подбор параметров к Non Max Suppression (или Weighted-Boxes-Fusion). Хочу отдельно поблагодарить ZFTurbo за реализацию его библиотеки. Достаточно быстро мы убедились, что WBF дает лучший результат даже на единственной модели.
Одно из главных препятствий с которыми мы столкнулись – было то, что автоматический подбор параметров (мы использовали байесовский подбор параметров) для WBF не дает результата, корреляции между Public Leaderboard (PLB) и нашей валидационной выборкой не было. Это связали с тем, что test сильно отличался от train, в test не встречались сеансы измерений из train. Так как тест был весьма велик и на PLB использовалось 50% теста мы решили доверять PLB. Согласен, не лучший подход, но мы так и не придумали как сделать грамотную валидацию. В итоге подбирали параметры мы эмпирически, основываясь на просмотре изображений вручную и PLB.
Далее мы взялись за ансамбли. Мы перепробовали множество вариантов ассемблирования, скажу кратко результат: в ансамбль вошли 1 лучший фолд effdet6 с разрешением 768 и 2 фолда effdet6_896 с весами 1 для разрешения 768, и 2 для 896. Ансамбль даль прирост точности на PLB с 0.763 до 0.776.
results = []
results_conf = []
for preds in all_predictions_reshaped:
boxes = []
scores = []
labels = []
for one_model_pred in preds:
boxes.append(np.array(one_model_pred['boxes'])/1023)
scores.append(one_model_pred['scores'])
labels.append(np.ones(one_model_pred['scores'].shape[0]))
image_name = one_model_pred['image_name']
# print(boxes)
boxes_wbf, scores_wbf, labels_wbf = run_wbf(boxes, scores, labels,weights=[1, 2, 2])
boxes_wbf = boxes_wbf.astype(np.int32)
result = {
'image_name': image_name,
'PredString': format_prediction_string_with_final_thres(boxes_wbf, scores_wbf)
}
result_conf = {
'image_name': image_name,
'PredString': format_prediction_string_with_conf(boxes_wbf, scores_wbf)
}
results.append(result)
results_conf.append(result_conf)
На основе выхода данного ансамбля мы решили делать псевдолейблинг, думая, что нейронные сети начнут лучше определять колосья на незнакомых сеансах измерений. Мы зафайнтюнили лучшую нашу модель, а также обучили еще одну модель с нуля. Эти 2 модели так же вошли в ансамбль и дали прирост точности до 0.783 на PLB, что и оказалось нашим конечным решением.
boxes_wbf, scores_wbf, labels_wbf = run_wbf(boxes, scores, labels, weights=[1, 1, 2, 2, 3])Где-то на этапе ассемблирования мы поняли, что нужна постобработка результатов и начали удалять колосья пшеницы, в которых ансамбль был не уверен после WBF, считаю это так же одним из ключевых моментов в нашем решении.
def format_prediction_string_with_final_thres(boxes, scores, final_thres=0.3):
pred_strings = []
for j in zip(scores, boxes):
if j[0] > final_thres:
pred_strings.append("{0} {1} {2} {3};".format(j[1][0],
j[1][1], j[1][2], j[1][3]))
return "".join(pred_strings)
Уже после соревнования мы расспросили других участников и оказалось, что единственная моделька yolov4 с весьма интересными параметрами давала почти такой же результат на PLB! Правда уже после открытия Private Leaderboard результат этого участника несколько ухудшился. Однако, считаю это нашим упущением, что мы довольно быстро отказались от YOLO.
В итоге к окончанию соревнования мы занимали 11 место на PLB с точностью 0.783 и оказались в ТОП10 после открытия Private Leaderboard c точностью 0.666. Стоит сказать, что лидерборд встряхнуло, но незначительно.
Исходный код предоставляю по ссылке. Спасибо за внимание!