/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 16 мин.
Данный пост хочется начать почти дословной цитатой Рауля Дюка из произведения Хантера Томпсона «Страх и ненависть в Лас‑Вегасе»: «У нас было 2 репозитория с реализацией DiT моделей, 1359 изображений дронов, 3 разных GPU, 4 размерности архитектуры на выбор, целое множество либ всех сортов и расцветок, а также веса для XL версии, попытка прунинга, бесполезная квантизация, оригинальная статья с arxivа и дедлайны. Не то что бы это был необходимый запас для генерации синтетических данных. Но если начал пробовать новую модель, становится трудно остановиться. Единственное что вызывало у меня опасение — это факт комбинации и без того тяжелых архитектур, диффузии и трансформера. Нет ничего более беспомощного, безответственного и испорченного, чем процесс обучения трансформера с нуля на одной видеокарте. Я знал, что рано или поздно мы перейдем и на эту дрянь».
Введение
Нередко на практике, когда работаешь с алгоритмами машинного обучения, а в особенности с нейронными сетями, сталкиваешься с проблемой нехватки данных для нормального обучения модели или хотя бы получения более‑менее стабильного результата. Вот и мы оказались в подобной ситуации, решая задачу компьютерного зрения, связанную с анализом наличия нарушений в помещениях закрытого типа: нужных изображений оказалось недостаточно для качественной модели, аугментация нам не сильно помогла, а спарсить изображения из Интернета оказалось невозможно из‑за специфики данных. Таким образом, перед нами возникла задача генерации синтетического датасета, состоящего из изображений, похожих на те, что имеются в распоряжении. Следует сразу уточнить, что в данном материале, в качестве аналога, будет взят для генерации открытый датасет, что концептуально не меняет предмета обсуждения.
Задумка состояла в следующем: найти готовую модель для image2image генерации, обучить ее на наших данных, а затем нагенерировать нужное количество изображений для дальнейшего использования.
Проведя обзор последних нововведений в задаче генерации изображений, мы остановили свой выбор на модели DiT (Diffusion Transformer), разработанной группой исследователей из Facebook (запрещенная на территории Российской Федерации организация) Research. DiT обучалась на ImageNet и отличается хорошей масштабируемостью: есть 4 модели разных размеров.
Таблица размерностей DiT моделей
| Размер | Количество параметров |
| S | 32 млн |
| B | 130 млн |
| L | 458 млн |
| XL | 675 млн |
Выбор пал именно на нее в силу нескольких причин:
1. Результаты обучения. На момент выпуска статьи Scalable Diffusion Models with Transformer (конец декабря 2022), модель DiT показала SOTA (State‑of‑the‑art) результат.
2. Открытый репозиторий с исходным кодом и комментариями разработчиков.
3. Генерация картинок без всевозможных фильтров. Очень часто генеративные модели, например, Stable Diffusion, создают эффекты свойственные иллюстрациям, нам хотелось этого избежать.
4. У нас все же стоит задача image2image генерации, а не столь популярной text2image или image+text2image.
5. DiT представляет собой новый класс диффузионных моделей, в котором стандартный U‑Net заменили трансформером. Подход на данный момент новый и только начинает получать широкое распространение, поэтому нам было интересно поработать с ним на практике.
Системные требования для работы с тех. стеком
Как и в случае с любой большой нейронной сетью для обучения‑дообучения понадобится не самая маленькая видеокарта. Для версий размером S и B достаточно примерно 4–8 Гб видеопамяти, в нашем случае были в распоряжении rtx3070ti на личном ПК и tesla t4 из среды разработки google colab. При работе с XL моделью уже необходимо примерно 24 Гб видеопамяти для чего подошла tesla A100, о деталях чуть позже.
Если описывать то, чем пользовались авторы данного подхода, то на датасете ImageNet модель DiT‑XL/2 обучалась на 8x GPU A100 со скоростью 0.044 шага/сек (шаги — training steps — это количество обновлений градиента) для нормального результата требуется примерно 400 тысяч тренировочных шагов, что ~80 тыс. эпох, ~9,5 дней. Для сравнения процесс полного обучения модели DiT‑S/2 занял примерно 4 дня (количество дней взято из статьи Masked Diffusion Transformer is a Strong Image Synthesizer).
Существует также репозиторий за авторством интерна MIT с реализацией ускоренных подходов по обучению и сэмплированию этих же самых моделей при помощи amp (automated mixed precision) и предварительно выделенных фичей из датасета при помощи VAE (Variational auto encoder). Так ускоренная версия DiT (fast‑DiT), которой мы и пользовались (к слову, авторы оригинального DiT тоже рекомендуют пользоваться именно fast‑DiT), позволяет обучить модель DiT‑XL/2 на одном A100 со скоростью 0.84 шага/сек, что на 95% быстрее оригинальной модели DiT.
Архитектура модели
Несколько слов про архитектуру.
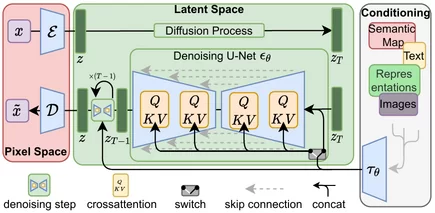
Рис. 1: Архитектура латентной диффузии у Stable Diffusion
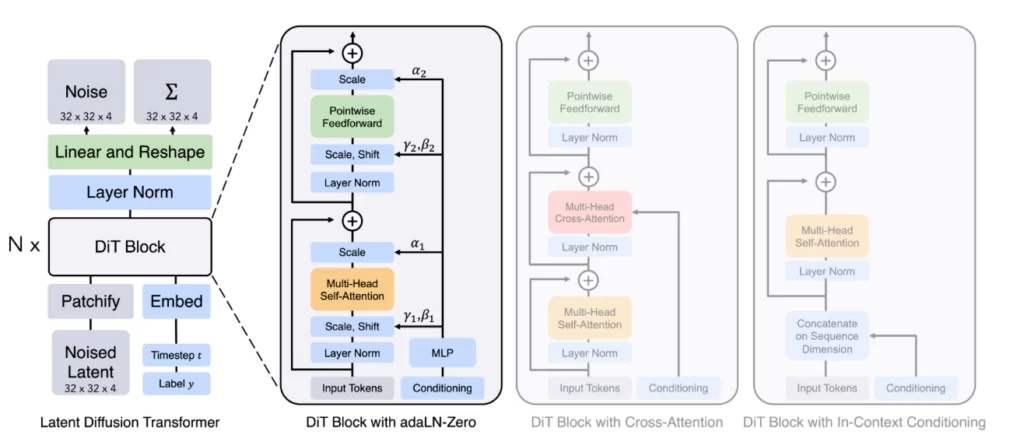
Рис. 2: Архитектура Diffusion Transformer
Как говорилось ранее, DiT во многом схож со Stable Diffusion (рис 1.), однако U‑Net backbone в DiT заменен трансформером. Процесс генерации изображений в случае диффузии состоит из двух этапов: зашумления и шумоподавления. Поскольку основной и самой сложной частью было обучение шумоподавляющей диффузионной составляющей вероятностной модели, за основу DiT был взят Vision Transformer (ViT), он хорошо зарекомендовал себя в задачах, связанных с CV, особенно в задачах классификации изображений. ViT работает с последовательностью патчей — областей заданного размера, на которые разбивается исходное изображение. Размер патча задается входным гиперпараметром p, который влияет на сложность модели (p задается при выборе модели, например, DiT‑S/2, где p=2).
Входные зашумленные изображения разбиваются на патчи размером p x p, а затем преобразуются в токены, это происходит в блоке Patchify. Процесс преобразования выглядит следующим образом, согласно схеме на рис. 3:
1. На вход подается зашумленные изображения размером I x I x C.
2. Зашумленные изображения разбивается на патчи (квадратики) размером p x p.
3. Патчи последовательно конкатенируются в последовательность из T токенов, T=(I/p)^2.
Получившиеся токены идут на вход блокам преобразования.
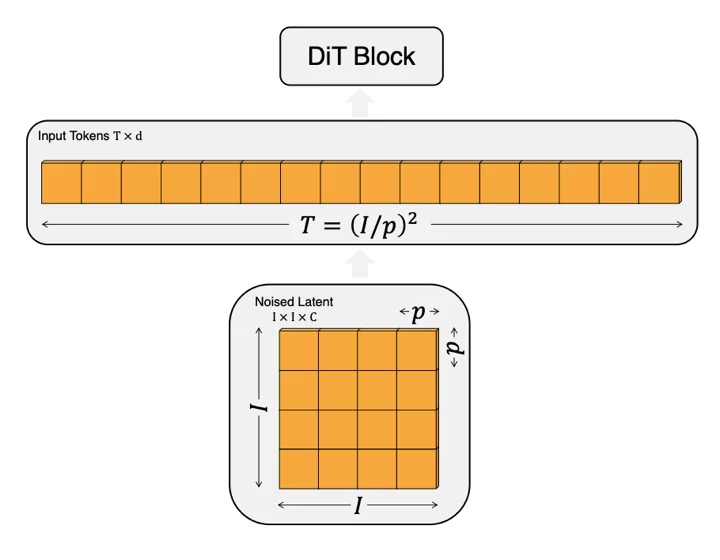
Рис. 3: Схема преобразования зашумлённого изображения в последовательность токенов
Немного подробнее остановимся на блоках преобразования, т.к. авторы уделяют им особое внимание (на рис. 2 в блоке DiT первые слои — это слои преобразования). Помимо токенов зашумленного изображения на вход преобразовательным блокам могут ещё подаваться дополнительные данные — шаги зашумления, класс изображения и естественный язык (описание изображения при наличии). В зависимости от входных данных авторы реализовали различные блоки преобразования, всего их 4 (In‑context conditioning, Cross‑attention block, Аdaptive layer norm, adaLN, adaLN‑Zero Block — с каждым более подробно можно ознакомиться в статье), главным образом они различаются в способе представления дополнительных данных в токенах. В дефолтной версии модели (DiT и, соответственно, fast‑DiT) на Гитхабе блок преобразования — adaLN‑Zero.
После блока трансформера необходимо преобразовать последовательность токенов изображения в выходной шум. За это отвечает стандартный линейный декодер VAE (декодер взят готовый из Латентной диффузионной модели (LDM «f8»), для удобства можно выбрать какую из вариаций этого декодера использовать VAE ft‑EMA или VAE ft‑MSE). После него, наконец, мы переставляем декодированные токены в их исходное пространственное расположение, чтобы получить предсказанный шум.
Обучение (дообучение) на практике для кастомного датасета
Как выше упоминалось мы использовали в качестве базы репозиторий с реализованными ускоренными версиями алгоритмов обучения, но т.к. он содержал в себе также ненужные папки и лишние строки кода, плюс необходима была небольшая модификация файла train.py под возможность дообучения, то было принято решения сделать свой репозиторий, который можно найти по этой ссылке. В качестве примера для демонстрации возможности генерации мы решили взять датасет Drone Dataset (UAV), в котором 1359 фото дронов.
В файле run_DiT.ipynb можно найти весь пайплайн, посмотрим здесь на ключевые моменты.
Для начала необходимо пройти в папку DiT и выполнить нужные импорты:
import DiT, os
os.chdir('DiT')
!pip install diffusers==0.19.1
!pip install timm --upgrade
# DiT imports:
import torch
from torchvision.utils import save_image
from diffusion import create_diffusion
from diffusers.models import AutoencoderKL
from download import find_model
from models import DiT_XL_
from PIL import Image
from IPython.display import display
torch.set_grad_enabled(False)
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cpu":
print("GPU not found. Using CPU instead.") Затем приступаем к обработке исходного датасета, он должен иметь следующий вид:
|-dataset
| |-class_1
| | | -img1.png
| | | -img2.png
| |-class_2
| | | -img1.png
| | | -img2.pngФайл extract_features.py нужен для того, чтобы предварительно извлечь фичи из датасета заранее при помощи VAE, а не во время непосредственной тренировки. Проще всего этот файл запустить либо из терминала, либо из ячейки jupyter ноутбука:
!torchrun \
--nnodes=1 \
--nproc_per_node=1 extract_features.py \
--data-path /content/DataSet \ # путь до датасета
--image-size 256 \ # размер изначального изображения, для расчёта размера латентного пространства фичей
--features-path /content/dit_features_test \ # путь сохранения фичей
--num-workers=2 \ # кол-во потоков, для винды лучше ставить 0
--vae ema # от выбранной функции потерь зависит загружаемая версия VAEВ итоге создаются две папки по указанному пути, и если прочитать содержимое любого файла, то можно увидеть сжатые тензоры для каждого изображения. На рис.4 приведен пример размерности такого тензора и содержимое лейбла.
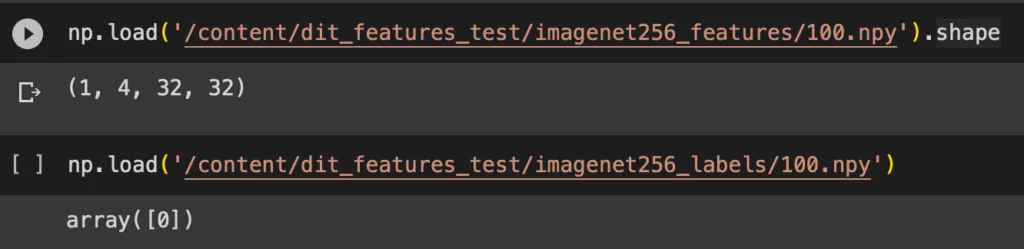
Рис. 4: Фичи после энкодера
Далее следует этап обучения. В качестве базовых моделей для экспериментов были выбраны модели S и XL размера. Так как предобученной модели на ImageNet размер S нет, то решили обучать модель с нуля.
За обучение отвечает файл train.py, который запускается аналогично с extract_feature.py. Данный вариант написания универсален для моделей любого размера.
!accelerate launch \
#запуск через данную библиотеку автоматически запускает метод mixed_precision, в формате fp16 (floating point), такой формат уменьшает затраченное кол-во бит для каждого числа в 2 раза с fp32
--mixed_precision fp16 train.py \
--model DiT-XL/2 \ # выбор архитектуры для загрузки из models.py
--num-classes 1 \ # влияет на загружаемую архитектуру
--feature-path /content/DiT/dit_features \ # путь к полученным раннее фичам
--num-workers=2 \
--results-dir /content/dit_train_result/ \ # путь где будут сохранены чекпоинты и log файл
--global-batch-size=1 \
--epochs=9 \ # число эпох для обучения
--log-every=4 \ # запись в log каждое n-е обновление градиентаРезультаты обучения можно увидеть в таблице. Как видно, обучение с нуля достаточно затратное по времени мероприятие для диффузионных моделей подобной ёмкости, что терминально влияет на возможность обучения подобных архитектур в средах выполнения с ограниченным временем использования. С другой стороны, если ограничения по времени нет, то процесс обучения, в принципе, возможен, но может занять больше недели на одной не топовой видекарте.
Результаты обучения DiT_S/2
| Модель | Среда выполнения | GPU / потребление видеопамяти от размера батча | Кол-во эпох | Loss | Время | Результат |
| DiT_S_2 | ПК | 3070ti / 128 – 4гб 256 – 8гб | 35000 | 0.025 | ~4 дня | Процесс обучения идет очень долго, получаются размытые изображения, нужно как минимум обучать 10 дней |
| Google colab | Tesla T4/ Аналогично | До 1500 | 0.152 | ~3 часа | Обучение завершается с достижением лимита длительности сессии collab. |
Ниже на рис. 5 представлены стадии эволюции генерации изображений в зависимости от количества эпох (после 2000 эпох мы перешли из google colab на ПК).

Рис. 5: Обучение DiT_S/2 с нуля
Как видно из картинки, обучение достаточно сильно улучшается на первых 15 000–20 000 эпохах, затем прогресс становится незначительным: большая часть картинок остается в виде размыленных абстракций, но стоит заметить, что график функции потерь (рис. 6) не выходит на плато и показывает нисходящий тренд (код для отрисовки функции потерь по лог файлу можно также найти в основной директории).
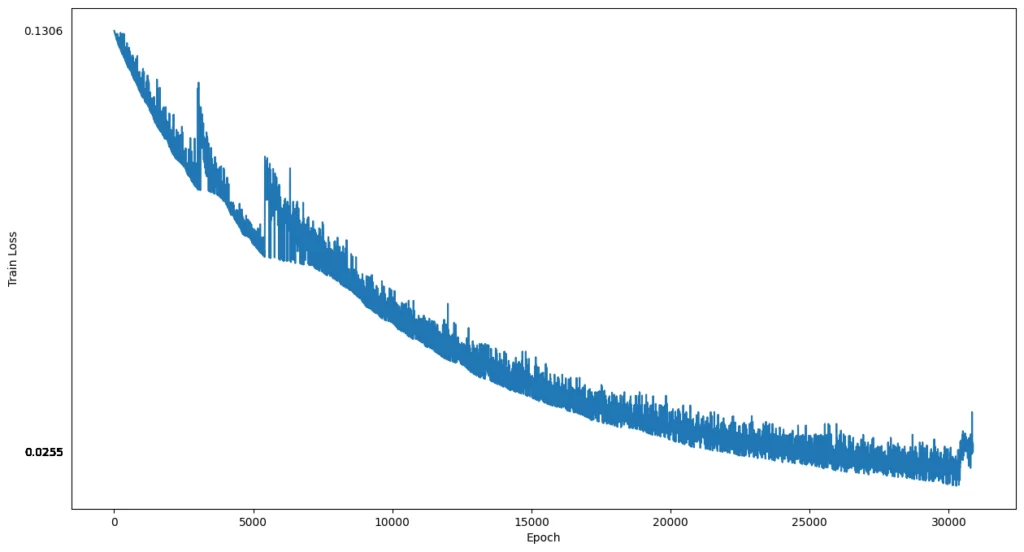
Рис. 6: График функции потерь при обучении DiT_S/2
Прежде чем переходить к описанию обучения самой большой модели возможно у читателя появился вопрос, а как, собственно, получили картинки из обученной модели выше? Для этого нам пригодится файл sample.py, в котором реализована возможность сэмплирования из обученной модели, декодирования при помощи декодерной части VAE, чей энкодер был использован нами ещё во время извлечения фич из изначального датасета, и сохранения получающихся изображений. Данный инструмент так же, как и другие удобно использовать через командную строку:
python sample.py \
--model DiT-S/2 \
--vae ema \ # отвечает
--image-size=256 \ # размер изначального изображений, для рассчета размера латентного пространства фичей
--num-classes=1 \ # влияет на загружаемую архитектуру
--cfg-scale 7 \ # влияет на генерацию, является дополнительным слагаемым в уравнении обновления градиента. На практике значения для этого параметра: 1<=cfg_scale<=20, - чем больше значение, тем сильнее будут отличаться сгенерированные изображения от исходных.
--num-sampling-steps=126 \ # количество итераций, которые выполняет модель, чтобы перейти от случайного шума к распознаваемому изображению, считается, что чем больше - тем более детальным получится генерируемое изображение.
--seed 3 \
--list-classes "0, 0, 0" \ # определяет кол-во, и классы сэмплированных изображений
--ckpt /content/trained_dit_weights.pt # путь к весамДанный алгоритм нужен для того, чтобы производить инференс для любой обученной модели. Мощностей google colab достаточно для получения картинок с самой большой версии модели. К сожалению, на CPU даже инференс представляет собой сложную задачу, т.к. требует много времени, и примерно 12 Гб оперативной памяти, так что в любом случае лучше работать с подобными архитектурами, имея GPU.
Практика с обучением с нуля, from scratch, даже малой модели доказала, что обучать самую большую модель стоило бы куда больших затрат по времени и железу, поэтому встал вопрос дообучения единственной представленной предобученной модели размером XL, которая видела данные из ImageNet.
Мы не оставляли надежду на возможность дообучить модель, используя всем известные квантизацию и/или прунинг. Квантизация — это процесс снижения точности чисел в весах моделей, путем представления чисел с меньшим количеством бит. Прунинг — это техника оптимизации ненужных параметров (нейронов, связей) из модели, которые не вносят значимого вклада в процесс обучения. Оба этих метода реализованы в библиотеке torch, но, как и ожидалось, подходят больше для инференса.
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# здесь применяется метод динамической квантизации, при которой веса уже обученной модели переводятся в 8 битный размер.Всего одна строчка кода действительно дала эффект, размер уменьшилась в 3 раза, что можно наблюдать на рис. 7.
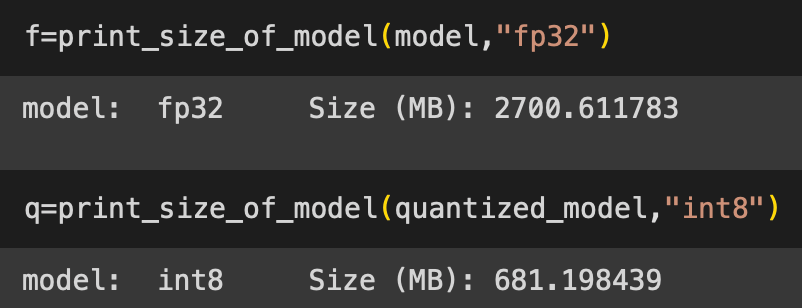
Рис. 7: Сравнение размера весов до и после квантизации
Но, к сожалению, квантизированную модель не получается использовать вместе с CUDA. При попытках дообучения возникает ошибка: «NotImplementedError: Could not run ‘quantized::linear_dynamic’ with arguments from the ‘CUDA’ backend», в поисках ответа становится ясно, что сама библиотека torch не поддерживает обучение на cuda после такого рода модификаций. Инференс возможен на CPU, но, как и было замечено выше, даже просто сэмплирование проходит в десятки раз быстрее на графическом процессоре.
Следующая идея – прунинг. Также можно реализовать с помощью torch за пару строк кода:
pruning_perc = 50
for module in model.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
prune.l1_unstructured(module, name="weight", amount=pruning_perc/100.0)
prune.remove(module, "weight") Этот код применяет L1-прунинг к каждому слою nn.Conv2d и nn.Linear в модели, сохраняя указанный процент ненулевых весов (в данном примере, 50% ненулевых весов).
Затем вызывается prune.remove, чтобы удалить нулевые веса и уменьшить размер модели. Но как итог, веса модели не уменьшились, и, по‑прежнему, для дообучения не помещаются в память Tesla T4. На этом попытки дообучить модель XL на «народных средствах» были брошены.
Рассуждая про дообучения мы так ни разу и не написали как его делать, на самом деле достаточно просто: код в ячейке используется тот же самый, что и для тренировки, но только с одним отличием, в запускаемом файле train.py необходимо раскоментить несколько строк, а именно:
# изменение весов в случае дообучения XL модели
t1 = torch.split(state_dict['y_embedder.embedding_table.weight'], 1)[895]
t2 = torch.split(state_dict['y_embedder.embedding_table.weight'], 1)[1000]
state_dict['y_embedder.embedding_table.weight'] = torch.cat((t1, t2), 0) Здесь в коде происходит изменение размерности эмбеддингов классов в загружаемых весах. Если у изначальной модели было 1001 класс, 1000 классов из imagenet + 1 класс заднего фона, то в данном случае нам для дообучения нужны эмбеддинги только одного класса. Самый простой способ выбрать какой класс для обучения подобрать, это выбрать похожие изображения, ориентируясь на документацию по ImageNet, тем самым можно не беспокоиться о разном распределении данных. Мы выбрали класс 895, который соответствует «warplane, military plane».
Ниже на рис. 8 представлены стадии эволюции генерации изображений в зависимости от количества эпох. Можно пронаблюдать забавные метаморфозы, происходящие с самолетами, на которых появляются новые отростки.

Рис. 8: Дообучение DiT_XL/2
В таблице показан наш скромный опыт попыток дообучить XL модель. Приличный результатов, как и ожидалось, можно достигнуть на картах с объемом GPU более 20 Гб. Как видно на рис. 8, loss функция также не достигает плато и сохраняет тренд на уменьшение, но продолжения не требовалось т.к. генерация на этом моменте достигает хорошего уровня качества.
Результаты дообучения DiT_XL/2
| Модель | Среда выполнения | GPU / потребление видеопамяти от размера батча | Кол-во эпох | Loss | Время | Результат |
| DiT_XL_2 | ПК | 3070ti | Процесс завершается с ошибкой, возвещающей о недостатке памяти на графическом ускорителе. | |||
| Google collab | Tesla T4 | |||||
| Datalab at work | Tesla A100 / 24-28 гб | 3278 | 0.015 | ~10 часов | Хороший результат. Качественная генерация. | |
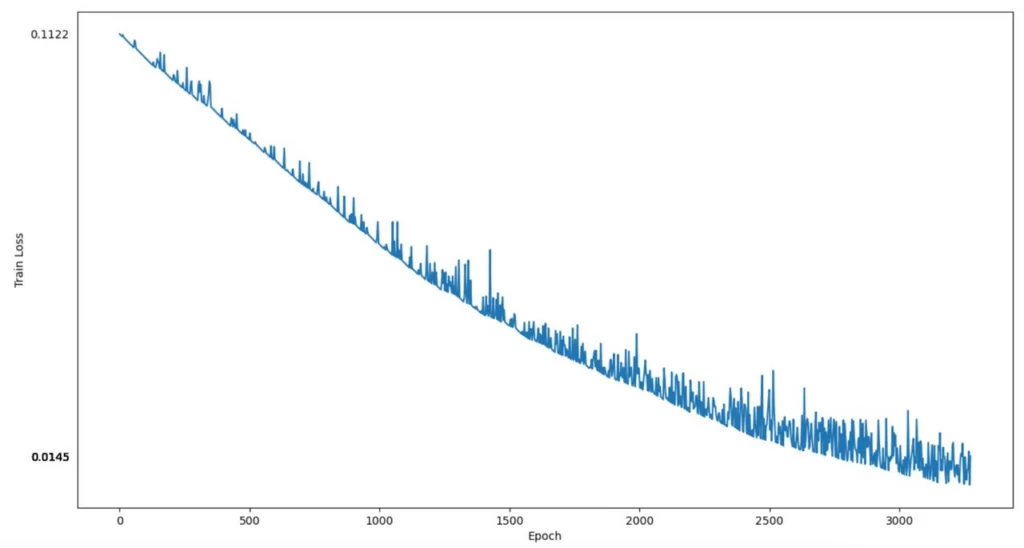
Рис. 9: График функции потерь при дообучении DiT_XL/2
Но что такое «хорошее качество» генеративного контента? Следует быстро обсудить данный вопрос, иначе разбор работы диффузионной модели будет не полным.
Метрики и оценка качества генеративной модели
Для оценки качества синтетических изображений, полученных при помощи генеративных моделей, чаще всего используются метрики FID (Frechet Inception Distance) и KID (Kernel Inception Distance).
Для DiT разработчики рассматривали 2 метрики: одна отвечает за сложность и производительность сети (GFlops), а другая за качество изображений (FID). В своей работе мы будем рассматривать только FID, так как нам важно оценить качество полученных изображений, а не сложность самой модели.
FID является стандартной метрикой для такой задачи в силу того, что она очень чувствительна к деталям изображений, и поэтому сравнение при помощи FID сгенерированных данных с реальными будет объективным. Также было интересно сравнить наши значения FID со значениями разработчиков, поэтому не стали брать KID.
Формула FID выглядит следующим образом:
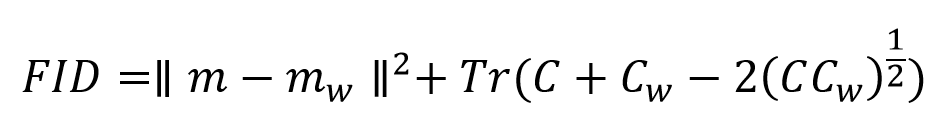
Первое слагаемое представляет собой квадрат нормы разницы между математическим ожиданием сгенерированного изображения (m) и математическим ожиданием реального изображения (mw), второе – след матрицы, состоящей из ковариационных матриц сгенерированного изображения (C), реального (Сw) и удвоенного корня их произведения.
Если опустить математическую формализацию, то в задаче генерации изображений метрика FID основывается на сравнении распределений признаков реальных и сгенерированных изображений в пространстве признаков. Когда сгенерированные изображения содержат много шума или несоответствий с реальными данными, их распределение признаков будет отличаться от распределения признаков реальных изображений. Это может привести к более высокому значению FID.
Область значений метрики FID не имеет верхней границы, нижняя граница — ноль, тогда все изображения идентичны. Если смотреть динамику изменения значений в оригинальной статье, то там показатель в промежутке от 200 до 2.27. На практике достаточно хорошие изображения получаются при FID <= 100 для небольшого объема как обучающего датасета, так и новых данных (примерно 1000 картинок на обучение и 400 сгенерировано).
Для сэмплирования большого числа изображений применяется sample_ddp.py и реализованный в нем метод DistributedDataParallel (DDP), который организует параллелизм данных на уровне модулей и может эффективно распределённо выполнять процесс на нескольких GPU. Сэмплинг c DDP очевидно требует хотя бы наличия одной видеокарты, в то время как метод в файле sample.py может обходиться только CPU.
Следующий код активирует процесс сэмплинга большого количества изображений:
!torchrun sample_ddp.py \
--model DiT-XL/2 \
--vae ema \
--sample-dir /path/to/generated/data \
--per-proc-batch-size 32 \
--num-fid-sample 400 \ # приблизительное кол-во изображений которое хочется нагенерировать
--image-size 265 \
--num-classes 1 \
--cfg-scale 7 \
--num-sampling-steps 250 \
--global-seed 42 \
--ckpt /path/to/your/trained/models/weights Подсчет метрики FID на сгенерированных данных осуществляется достаточно просто так как метод полностью имплементирован в учебный репозиторий от OpenAI по диффузионным моделям. Код расчета может выглядеть следующим образом:
!git clone https://github.com/openai/guided-diffusion.git
!pip install TensorRT
!python /content/guided-diffusion/evaluations/evaluator.py \
--/content/drone_references_256x256.npz
--/content/DiT-XL-2.npz
Output:
…
100% 15/15 [00:12<00:00, 1.20it/s]
computing/reading reference batch statistics...
computing sample batch activations...
100% 1/1 [00:01<00:00, 1.65s/it]
computing/reading sample batch statistics...
Computing evaluations...
Inception Score: 3.2856605052948
FID: 95.36638240938257 Результат

Для сравнения сгенерированных изображений с исходными, надо создать сэмплы изображений дронов в формате npz: экспериментальным путем мы заметили, что для лучшего показателя FID необходимо, чтобы размеры сгенерированных и исходных изображений были одинаковыми, поэтому перед сэмплированием все изображения дронов мы привели к одному размеру (у нас это 256×256), а только затем перевели их в формат npz. Так же стоит учесть, что для достижения наименьшего FID количество изображений в обоих семплах должно быть одинаковым. Ноутбук с расчетом метрики и код того, как перевести нужный датасет в сжатый numpy формат npz, нужный для расчета FID присутствует в репозитории.
Результаты метрики FID равны 95, что является достаточно неплохим результатом для 480 сгенерированных картинок. Это означает, что новые данные похожи на реальные в пространстве признаков, а также что уровень зашумления в синтетическом датасете низок, что, разумеется, не может не радовать, ибо столько времени и сил потрачено на обучение/дообучение представленных моделей.

Рис. 10: Примеры сгенерированных изображений
Заключение
В качестве вывода хочется заметить, что работа с диффузионными моделями, трансформерами очень часто связана со сложностями временного и вычислительного характера, но от того менее интересной не становится. На сегодняшний день генеративные сети не столько проникают во все области жизни, сколько их пытаются везде использовать, что абсолютно нормально, учитывая какой наглядный и качественный материал они выдают. А учитывая, что синтетические данные часто улучшают другие алгоритмы (что кстати и произошло в итоге с нашей классификацией, если возвращаться к практическому кейсу), то подобные нейронные сети становятся полезными инструментами в руках тех, кто работает с данными и машинным обучением. В посте был представлен полный пайплайн от знакомства до практического применения относительно новой архитектуры Diffusion Transformer, надеемся, что наше погружение в тему диффузионных моделей в достаточной степени окажется полезным, и даже где‑то интересным.