/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
GPT-3 — нейронная сеть, наделавшая шума в 2020 году, как самая сложная, объёмная и многообещающая модель по работе с текстовыми данными. Создана организацией OpenAI в нескольких вариациях, от 125 миллионов до 175 миллиардов признаков. Хотя в названии организации и есть слово “Open”, по факту модель GPT-3 является проектом проприетарного типа, то есть, с закрытым программным кодом, доступ к которому выдаётся за деньги.
В октябре этого же года команды из SberDevices на основе статьи от OpenAI и кода модели GPT2 смогли разработать русскоязычный аналог под название ruGPT-3 в 5 вариациях от 125 млн. до 13 млрд. признаков, используя мощности суперкомпьютера «Кристофари», а самое главное, что в данном случае код действительно открытый, за исключением модели на 13 млрд.
За счет универсальности и гибкости модели ее можно использовать не только для создания текста, но и в десятках других сложных сценариев, например:
- анализ настроений текста, их классификация на положительные и отрицательные;
- из пункта 1. следует возможность использования для алгоритмов детоксификации, то есть, автоматического редактирования отрицательных текстов в положительные;
- ранжирование картинок и подписей к ним – своеобразное computer vision решение, которое относит подпись к нужному изображению;
- симплификация / суммаризация / резюмирование текстов, то есть, создание краткого пересказа, поданного на вход текста с сохранением смысла;
- сервисы по генерации текста – Копирайтинг – Рерайтинг электронных писем, рекламных объявлений и прочего на заданную тему;
- рекомендательные системы – анализ ранних запросов пользователей, список составленных предпочтений и предложение релевантного контента;
- перевод текстов на различные языки;
- чат боты для поддержания как неформальной беседы, так и в качестве составной части виртуального ассистента;
- генерация программного кода по запросу пользователя
При использовании данной нейросети в качестве инструмента необязательно знать структуру кода или хитросплетения слоёв нейронов, но нужно понимать некоторые гиперпараметры, необходимые для настройки, так как они будут сильно влиять на результат. Проще всего отметить несколько универсальных стилей работы с данной моделью на примере задачи генерации текста.
Стиль 1. Строгий машинный подход к написанию текста
Настройка специальных гиперпараметров для данного случая не требуется. Отбор слов происходит по принципу наибольшей вероятности.
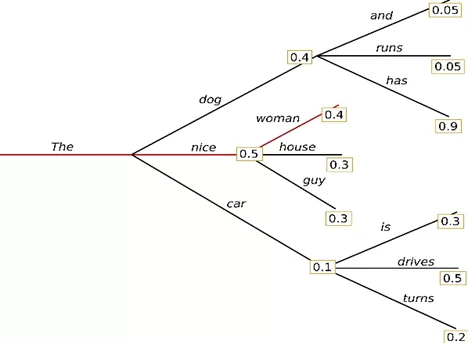
Стиль 2. Менее строгий подход к написанию текста
num_beams = n – кол-во путей с наибольшими неочевидными итоговыми вероятностными сочетаниями. Изначальный выбор путей происходит из топа величин вероятностей по первым нодам. На рисунке 2 — это случай выбора фразы «The dog has» при n=2, P = 0,36. Без данного параметра будет происходить «жадная» генерация текста, то есть, модель будет выбирать следующее слово, у которого вероятность появления после предыдущего максимальная «The nice woman», общая P = 0,2 — меньше чем при поиске пути
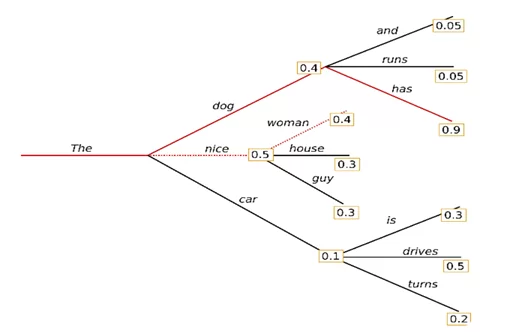
early_stopping=True — генерация подсчёта вероятностей завершается, когда достигнут конец предложения.
no_repeat_ngram_size = n – штраф за повторы в сочетаниях слов. Убирает повторы длиной в n слов, например, если текст про «Российскую Империю», то словосочетание «Российская Империя» при параметре n=2, не будет повторяться.
num_return_sequences = n – кол-во лучших вариантов генерации на вывод. Очень полезный параметр позволяет выбрать лучший вариант генерации, который более всех остальных отвечает целям оператора, но необходимо следить чтобы данный параметр был <= num_beams.
Стиль 3. Сэмплинг – более творческий подход к генерации, включающий в себя элемент случайностей
do_sample=True – случайный выбор следующего слова в соответствии с его условным распределением вероятностей, используя только данный параметр, сильно увеличивается вероятность получения логического бреда
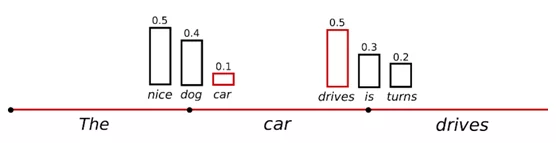
temperature = n – используя данный коэффициент происходит увеличение вероятности использования слов с высокими значениями вероятности и уменьшение вероятности использования слов с низкой вероятностью в распределении. Также, чем ближе к нулю значение, тем больше генерация будет похожа на жадный подбор слов
top_k = n – определяется n кол-во слов, которые обладают наибольшей вероятностью из условного распределения вероятностей всех слов, что сужает выбор для модели и отбрасывает максимально неподходящие слова сразу
top_p = n – определяется n слов, чья вероятностная масса вместе равна n%, то есть ограничения сэмлирования происходят динамически, исходя из начального набора, можно комбинировать с top_k
Промежуточный вывод:
Стиль 1 используется, если нужно получить точное определение, точный перевод, когда не нужно видеть других вариантов генерации. Стиль 1 следует правилу определения следующих слов, ориентируясь только на высокую вероятность их появления.
Стиль 2 лучше всего подходит, если известна заранее длина текста для генерации, и где творчество и непредсказуемость являются нежелательной чертой, но необходима гибкость в выражениях сохраняя общий формализм, то есть в случаях, например, деловой переписки или генерации чего-то одной природы, например, списков имён, цифр.
Стиль 3 следует использовать для генерации более непринуждённых бесед, рассказов, сочинений.
Посмотрим на модели поближе. Проведем эксперимент, дообучим 2 вида сети ruGPT-3 small (125 млн. признаков) и large (760 млн. признаков) на статьях с сайта NTA, используя мощности платформы Ml_Space от площадки SberCloud. Из спарсенных и размеченных 1117 статьях для обучения выберем одну, что снискала популярность на всем известном портале ‘Хабр’, и имеет более 2-х тысяч просмотров. Эта статья: «Поиск нарушений на видео при помощи компьютерного зрения».
Ссылки:
- https://newtechaudit.ru/poisk-narushenij-na-video-s-pomoshhyu-kompyuternogo-zreniya/
- https://habr.com/ru/post/545678/
Далее уберем эту статью из обучающей выборки и сгенерируем при помощи дообученных нейронных моделей отрывки текста, которые могли бы принадлежать к началу данной статьи. В качестве затравки будут подаваться на вход названия статей.
Отрывок кода, для процесса дообучения small и large версий модели:
#Установка необходимых библиотек:
!pip install torch==1.4.0
!pip3 install transformers==3.5.0
#Скачивание репозитория Сбера, который содержит нужные модели и скрипт токенизации входных данных
!git clone https://github.com/sberbank-ai/ru-gpts
# создание папки для модели, куда будут сохраняться веса модели
!mkdir models/
# Дообучение модели. Текстовые документы находятся в раннее созданных спарсенных данных в файлах train.txt и test.txt. Здесь можно выбирать название модели, которую нужно дообучить, размер блока в который будет упакован датасет после токенизации, кол-во эпох в обучении. В результате модель дообучится и рассчитает метрику удивления модели – перплексию, где чем значение меньше, тем лучше, здесь оно находилось в диапазоне от 11 до 17.
!export PYTHONPATH=${PYTHONPATH}:/ru-gpts/
!CUDA_VISIBLE_DEVICES=0 python ru-gpts/pretrain_transformers.py \
--output_dir=models/weights \
--model_type=gpt2 \
--model_name_or_path=sberbank-ai/rugpt3large_based_on_gpt2 \
--do_train \
--train_data_file=train.txt \
--do_eval \
--eval_data_file=valid.txt \
--per_gpu_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--num_train_epochs 5 \
--block_size 1024 \
--overwrite_output_dir
#Фиксирование рандома, чтобы результат был более менее воспроизводим
np.random.seed(42)
torch.manual_seed(42)
#Импорт модели и токенизатора из huggingface – библиотеки по работе с транформерными моделями
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tok = GPT2Tokenizer.from_pretrained("models/weights") #загрузка дообученного токенизатора
model = GPT2LMHeadModel.from_pretrained("models/essays") #загрузка дообученной модели
model.cuda() #перевод модели на GPU, можно обойтись и без этого, тогда генерация будет происходить медленнее
#предоставление затравки должно быть Явное, копируя вид размеченных данных:
text = "\n\n\n<s>Заголовок: Продвинутое использование библиотеки pytorch: от
подготовки данных до визуализации результата \n\nСтатья: "
inpt = tok.encode(text, return_tensors="pt")
#Настройка гиперпараметров, исходя из выбранного стиля генерации
num_return_sequences = 5
out = model.generate(inpt.cuda(),
num_return_sequences= num_return_sequences,
max_length=150,
repetition_penalty=2.0,
do_sample=True,
top_k=50, top_p=0.95,
temperature=0.7)
#Просмотр результатов для всех созданных вариантов
for i in range(num_return_sequences):
print(tok.decode(out[i]))
В качестве результата сравнения будет субъективное мнение автора о том, логично ли составлен кусок текста и лучше или хуже он чем тот, что есть сейчас в статьях.
Затравка: «Заголовок: Поиск нарушений на видео при помощи компьютерного зрения»
Оригинал: «В нашем распоряжении имеются записи с камер наблюдения рабочего места сотрудника и журнал проведения операций. Будем искать все моменты на записи, где отсутствовал клиент. В этом нам поможет нейронная сеть MobileNet и CSRT Tracker из библиотеки opencv. А для удобства еще и Tesseract-OCR.»
Результат (Small): «Содержание: Как правило, в аудиторских расследованиях выявляются ошибки и несоответствия. При этом зачастую не удается найти причины нарушения или выявить отклонения от норм законодательства РФ – например нарушение сроков получения лицензии (внутренний аудит). Поэтому одним из решений для предотвращения подобных проблем является применение алгоритмов компьютерной визуализации с использованием компьютерных технологий. По мнению автора статьи Дэвида Мюррея Аудитора Веб-сайта MITSHOP, алгоритм распознавания лиц по изображению лица может помочь сократить количество ошибок оператора видеопотока данных во время передачи кадров о событии.»
Результат (Large): «Содержание: В работе аудитора часто встречаются случаи, когда в процессе проведения проверки выявляются нарушения законодательства РФ или иных нормативных правовых актов. Нередки ситуации выявления фиктивных трудовых отношений между сотрудниками и работодателями либо предоставления заведомо ложных сведений о состоянии здоровья сотрудника по результатам медицинских осмотров (обследований). В подобных случаях мы сталкиваемся с проблемой поиска нарушителей уже после совершения противоправной деятельности – например через анализ видеоматериалов видеонаблюдения за процессом исполнения служебных обязанностей сотрудников подразделения внутреннего аудита банка.»
По итогу, первый вариант генерации достаточно неплох, но под конец выдаёт бред про автора статьи, и демонстрирует потерю логической связи, второй вариант выглядит достаточно хорошо в качестве введения, не теряет логическую нить и более развёрнуто описывает проблему. Главное отличие оригинала от сгенерированных, это краткость изложения и погружения в инструменты работы сходу.
Продемонстрируем еще один пример использования данной сети и создадим рекомендательную систему по кинематографическим предпочтениям. Для примера будет взят пользователь из сайта Кинопоиск и сгенерированы фильмы, которые он смотрел на основе 2-х любых просмотренных из его истории, дальше проведено банальное сравнение, есть ли эти фильмы у него также в истории. То есть, модель не будет дообучаться, а будет строить продолжение из того, что уже знает.
Для данного случая воспользуемся вариантом ruGPT-3xl на 1,3 млрд признаков. В качестве стиля для генерации не подойдёт использование сэмплинга, ибо нужен более строгий подбор именно фильмов, в противном случае, алгоритм будет уводить в рассуждения о жизни и другие подобные темы.
Чтобы работать с данным xl вариантом необходимо сначала установить расширения для оптимизации смешанного и распределенного обучения в Pytorch – Apex, плюс язык для работы с ядрами – Triton и библиотеку для расширенного использования языковых моделей Deepspeed.
Фрагмент кода для настройки:
#Настройка параметров для стиля с Beamsearch
filter_resuls(gpt.generate(
text="Артём, 25 лет. Он смотрел фильмы: 'Унесённые призраками','Твоё имя', ",
max_length=120,
num_beams=3,
no_repeat_ngram_size=3,
repetition_penalty=2.))

Сравнив данный результат с историей пользователя сервиса узнаём, что покрытие составляет 100%, это разумеется и потому что, алгоритм предлагает также и крайне популярные фильмы, но результат всё равно достаточно неплохой с учётом, что модель никак не дообучалась.
В качестве заключения приведу фразу, которую сгенерировала модель ruGPT-3 13B на 13 млрд. признаков, которую можно запустить только по API на площадке SberCloud, с затравкой содержащей начало вывода: «В качестве вывода можно сказать, что нейронная сеть GPT-3 => из эксперимента в эксперимент позволяет решать весьма интересные задачи. В дальнейшем на основе этой сети планируется создать интеллектуальные системы дистанционного управления движением ракет с применением технологии ГЛОНАСС или Galileo (если их реализация состоится). А также система мониторинга параметров ядерных установок ВВЭР и ЯБП может быть использована для поиска повреждений отдельных реакторов АЭС России», грандиозные планы, конечно.
Модели, рассмотренные в данной статье достаточно малы, в то время как уже сейчас существует модель на 1,6 трлн признаков от Google, что только говорит о начале использования данного инструмента, и перспективности задействования его, если не как основного, то дополнительного во многих сервисах, что существуют на сегодняшний день и еще только будут созданы.