/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Предлагаем рассмотреть несколько алгоритмов поиска выбросов, проведём первичное сравнение на различных датасетах и определим несколько наиболее оптимальных из них.
Выбросы (или аномалии) в статистике — результаты измерения, выделяющиеся из общей выборки. Обнаружение выбросов важно во многих областях и процессах. В электронике поиск выбросов может помочь при обнаружении неисправных устройств. В банковских операциях поиск выбросов может помочь при обнаружении нетипичных для клиента операций. Давайте рассмотрим, как можно решить задачу поиска выбросов с помощью языка Python и библиотеки PyOD.
Библиотека PyOD включает в себя более 40 алгоритмов обнаружения выбросов, от классических LOF, PCA и kNN до новейших ROD, SUOD и ECOD.
Более подробно ознакомиться со всеми алгоритмами и наборами данных можно по ссылке https://github.com/newtechaudit/pyod.
Давайте сравним скорость и точность нескольких реализованных в этой библиотеке алгоритмов. Возьмём на тестирование 10 алгоритмов из различных категорий.
Для начала необходимо импортировать библиотеки:
import pyod
import scipy
Сравнение проведем на следующих наборах данных:
datasets = [
'cardio.mat',
'glass.mat',
'letter.mat',
'lympho.mat',
'pendigits.mat',
'pima.mat',
'vertebral.mat',
'vowels.mat',
]
Файлы .mat представляют собой сохраненную рабочую область MATLAB. Их можно открыть с помощью библиотеки scipy. Чтобы обойти все датасеты, определим цикл, в котором будем загружать каждый с помощью команды.
for dataset in datasets:
mat = loadmat(os.path.join('/data', dataset))
Далее для каждого набора данных разделим выборку на тренировочную и тестовую в отношении 70/30, а также проведём Z-нормализацию матрицы признаков.
X = mat['X']
y = mat['y'].ravel()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=random_state)
X_train_norm, X_test_norm = standardizer(X_train, X_test)
Для удобства определим словарь с алгоритмами, которые будем тестировать. Все алгоритмы, реализованные в библиотеке PyOD, можно разделить на несколько групп:
- вероятностные (в тестировании используем алгоритмы ABOD, SOS)
- линейные модели (PCA, OCSVM)
- основанные на близости (LOF, CBLOF, KNN, ROD)
- ансамбли (IForest, LODA)
- нейронные сети
У всех алгоритмов, реализованных в библиотеке PyOD, есть параметр contamination. Он задает процентное количество выбросов в датасете. В нашем тестировании не будем задавать этот параметр (по умолчанию contamination=0.1) и сравним все алгоритмы “из коробки”. Для алгоритма ROD установим параметр parallel_execution=True для выполнения вычислений параллельно.
algos ={
'Principal Component Analysis (PCA)': PCA(),
'One-Class Support Vector Machines (OCSVM)': OCSVM(),
'Local Outlier Factor (LOF)': LOF(),
'Clustering-Based Local Outlier Factor': CBLOF(),
'k Nearest Neighbors': KNN(),
'Rotation-based Outlier Detection': ROD(parallel_execution=True),
'Angle-Based Outlier Detection': ABOD(),
'Stochastic Outlier Selection': SOS(),
'Isolation Forest': IForest(),
'Lightweight On-line Detector of Anomalies': LODA(),
}
Проведем обучение и измерим время начала и окочания обучения каждого алгоритма. Также предскажем значения для тестовых нормализованных данных.
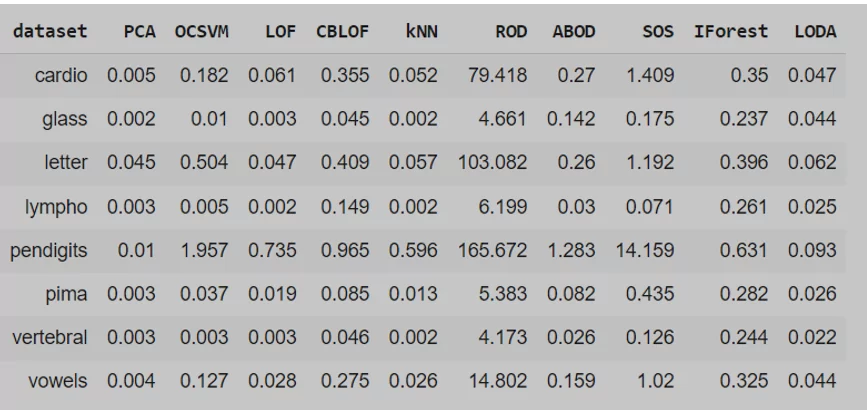
Мы видим, что все алгоритмы выполняются за почти одинаковое время, за исключением алгоритма ROD, время обучения которого даже при применении параллельных вычислений (по умолчанию 2 потока) составляет от 4 секунд до почти 3 минут.
Самым быстрым является алгоритм PCA, время обучения которого составляет от 0,002 до 0,01 секунд.
По результатам точности и использования roc_auc_score получаются следующие результаты:
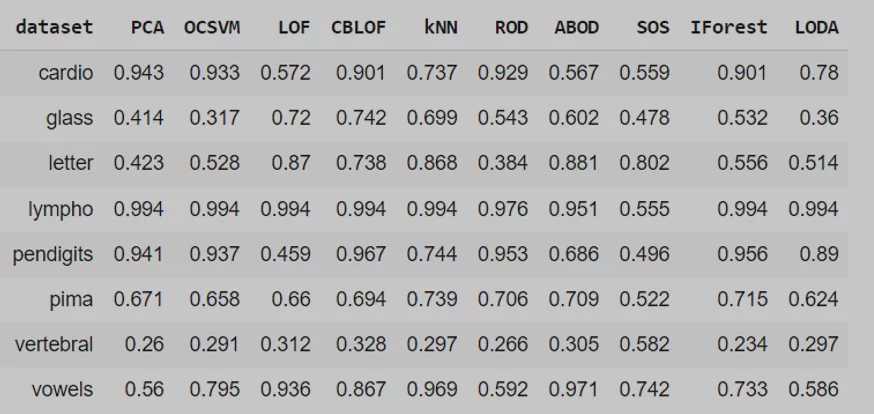
Все алгоритмы показывают примерно одинаковый уровень точности. SOS, который относится к вероятностным алгоритмам, в среднем показывает более низкий уровень точности, однако хорошо справляется с некоторыми наборами данных.
Оценка результатов.
Совокупно по точности и скорости выполнения можно выделить следующих лидеров среди алгоритмов из различных категорий: PCA (линейный), kNN (основанный на близости), IForest (ансамбль). С их применения можно начинать решать задачу поиска выбросов.