/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Любая крупная компания представляет собой множество обособленных или взаимосвязанных процессов, которые решают задачи различной направленности. Как правило, любой процесс является сложным механизмом взаимодействия людей, сервисов или других компаний, от которых зависит конечный результат исполняемого процесса. Перерывы в поставках ресурсов, изъяны в сервисах и алгоритмах, длительные исполнение простых операций или их повторное выполнение и многие другие факторы приводят к дополнительным экономическим издержкам и накоплению негативного клиентского опыта. Таким образом, анализ процессов и устранение недостатков в них — одна из важных составляющих для успешного ведения бизнеса.
Для выявления отклонений в процессе в первую очередь необходимо ответить на вопрос – какая последовательность событий (путь процесса) является оптимальной и приводит к положительному результату с минимальным негативным опытом? Четкое понимание того, что из себя представляет оптимальное исполнение процесса, позволяет строить гипотезы и находить точки для его оптимизации.
В данной статье рассмотрим простой и интуитивно понятный способ определения оптимального пути процесса. Для анализа данных будем использовать язык программирования Python. Если интересно, код и пример анализа к статье можно найти в git-репозитории. В качестве исходных данных будет использоваться процесс возмещения затрат на командировки, который выглядит следующим образом:
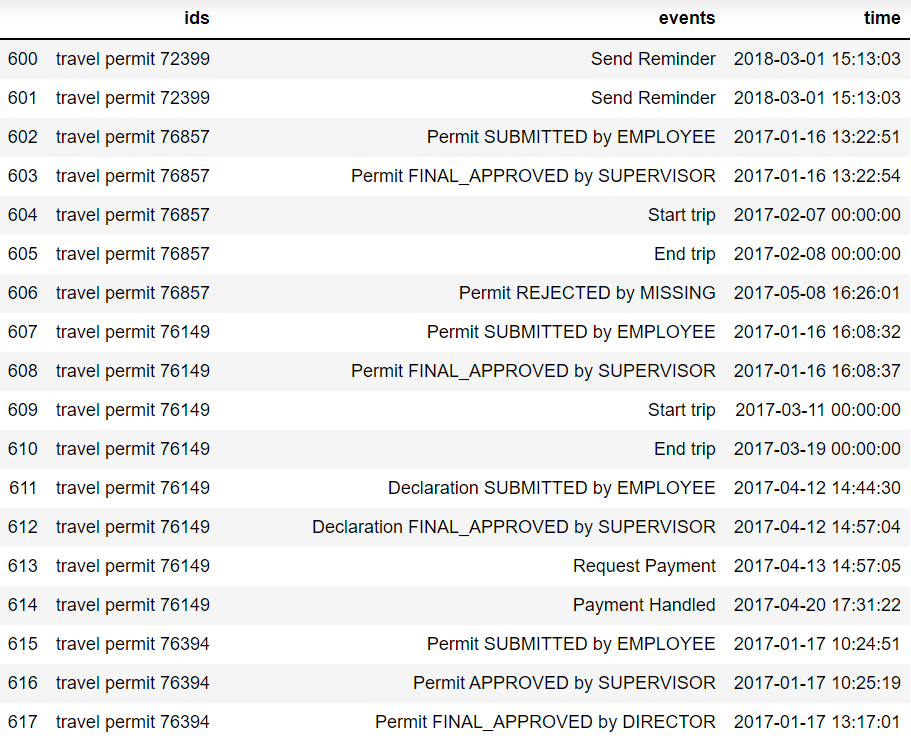
Перед началом анализа стоит убедиться, что данные включают в себя только журнал событий по обособленному процессу, на который не влияют сторонние факторы. Объясню, что имеется в виду на игрушечном примере. Процесс выдачи кредита – ипотечный, потребительский и другие, все типы относятся к одному процессу, но на условия оформления и одобрения для каждого из них влияют различные факторы, которые присущи только конкретному типу кредитования. И чтобы избежать мешанины и путаницы, такие данные необходимо анализировать отдельно, в разрезе отдельного типа. Самое простое, что мы можем сделать для нахождения оптимального пути – посчитать частоту для каждой уникальной последовательности и выбрать самую популярную:
ilog = Initial_Log(log, "ids", "events", "time", timeformat="%Y-%m-%d %H:%M:%S")
df_topchain = ilog.get_top_chain_sequences(10)
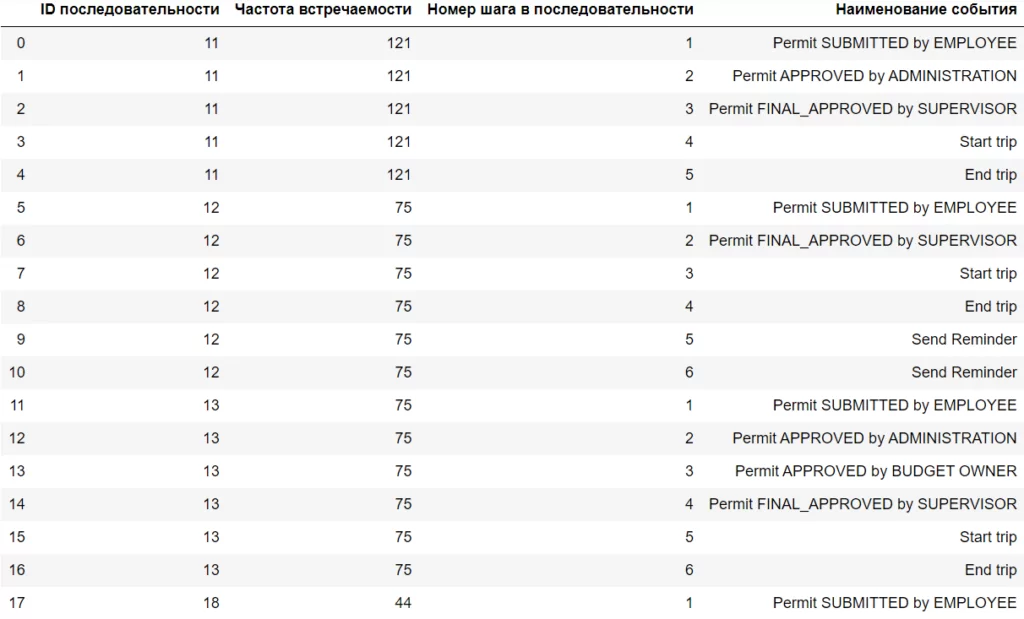
В данном примере для наглядности привёл срез коротких последовательностей, так последовательность под номером 11 содержит только 5 шагов и встречается в 121 случае. Для статистики, данный лог содержит 7065 уникальных сотрудников, которые прошли 1478 уникальных последовательностей событий.
Самая популярная последовательность встречается 956 раз:
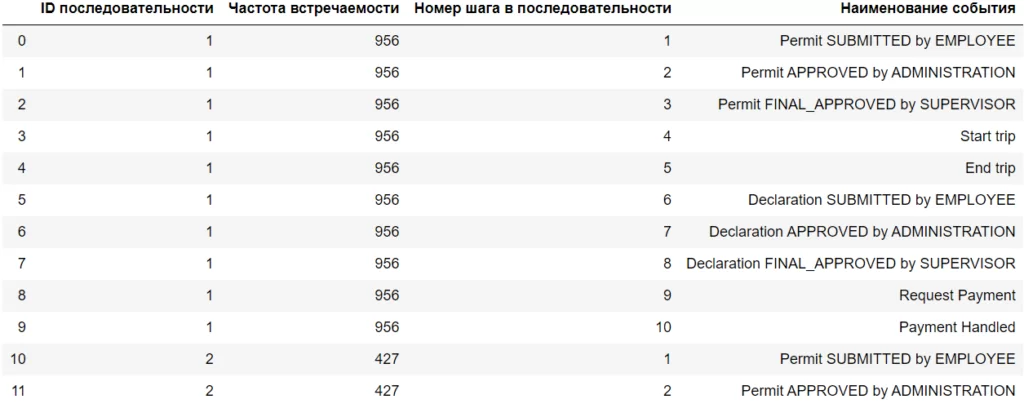
Можно сказать — вот он, идеальный путь, сотрудник направил запрос на командировку и в конце получил выплату с успешным одобрением на всех этапах. Однако такой результат не всегда будет верным. Срез данных, которые выбрали для анализа, может содержать в себе большинство последовательностей с негативным исходом.
Таким образом, необходимо просмотреть топ последовательностей по убыванию, и выбрать ту, которая совпадает с корректным начальным и конечным событием. Встречается следующая проблема, таких последовательностей много, каждая из их содержит различное количество событий. А значит, и процесс осуществляется за различное время и задействует различные ресурсы.
Попробуем другой подход к поиску оптимальной последовательности. Для этого выберем последовательность из таблицы выше, которая, на наш взгляд является правильной. Далее будем осуществлять поиск последовательностей, исходя из трех факторов, которые можем рассчитать из имеющихся данных:
1. Общее время исполнения последовательности. Сортируем последовательности в логе в порядке возрастания общего времени исполнения. Недостатки данного фактора — существуют события, которые напрямую не зависят от самого процесса. Например, время, затраченное на командировку. Одному сотруднику нужно съездить на конференцию в соседнюю область, другому, провести исследования в Антарктике. Таким образом, такие события могут сильно искажать статистику последовательности.
2. Насколько последовательность похожа на ту, которую мы выбрали. Определяем значение сходства каждой последовательности в логе с выбранной и сортируем в порядке убывания схожести. Недостатки фактора – если имена событий будут представлены в виде индексов (event_1, event_2, event_22…), могут быть неточности с коэффициентами схожести, стоит уделить внимание к выбору алгоритма или переименованию событий. Для определения схожести строк в данном примере используется стандартная библиотека Python – difflib (метод SequenceMatcher). Но советую попробовать библиотеку thefuzz.
3. Насколько часто последовательность встречается в логе. Сортируем последовательности в порядке убывания частот.
Далее выберем из трех отсортированных списков индексы последовательностей и просуммируем их. Таким образом мы получим «вес последовательности», только выбираем с наименьшим весом.
Для примера, выберем для анализа следующую последовательность:
for_compare = ['Permit SUBMITTED by EMPLOYEE',
'Permit APPROVED by ADMINISTRATION',
'Start trip',
'End trip',
'Declaration SUBMITTED by EMPLOYEE',
'Declaration APPROVED by ADMINISTRATION',
'Request Payment',
'Payment Handled']
И рассчитаем лучшую последовательность, по отношению к выбранной:
op = Optimal_Process(ilog)
b, s = op.get_faster_similar_sequence(for_compare, best_seq_ind = 0)
В итоге получим следующую последовательность:
['Permit SUBMITTED by EMPLOYEE',
'Permit APPROVED by ADMINISTRATION',
'Start trip',
'End trip',
'Permit FINAL_APPROVED by SUPERVISOR',
'Declaration SUBMITTED by EMPLOYEE',
'Declaration APPROVED by ADMINISTRATION',
'Declaration FINAL_APPROVED by SUPERVISOR',
'Request Payment',
'Payment Handled']
Как видим, относительно выбранной последовательности у нас добавилось одобрение поездки «Permit FINAL_APPROVED by SUPERVISOR» и одобрение декларации на расходы «Declaration FINAL_APPROVED by SUPERVISOR» руководителем. Что очень похоже на самую популярную последовательность (таблица 3). Разница только в том, что одобрение поездки руководителем осуществляется уже после командировки.
Здесь сразу хочется вернуться к первому фактору, который описали выше. В данном случае время, затраченное на поездку, является случайным фактором, и для полученной последовательности медианное время исполнения события поездки оказалось меньше, чем для самой популярной, по этой причине вес последовательности может быть сильно завышен. Поэтому, если в анализируемом логе присутствуют подобные события, им стоит задавать константное значение, чтобы они не вносили хаос в общую статистику.
Исходя из результатов, можем убедиться, что самая популярная последовательность и есть оптимальный путь процесса. На основе этого можно продолжить дальнейший анализ, фильтровать цепочки событий, которые не входят в оптимальный процесс, и выявлять их причины.
Данная статья не является руководством по исследованию, а лишь одним из примеров, как можно подойти к анализу процесса без использования сложных инструментов. При этом мы попытались выделить основные проблемы, с которыми можем столкнуться при анализе процессов.