/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
При первичном анализе больших процессов очень важно выделять проблемные участки. Акцентирование внимания на выбросы или ярко-выраженные отклонения позволяет сократить время на выявление источника проблемы в процессе. Как правило, анализ событий и последовательностей осуществляется в разрезе различных статистик. При этом эти статистики рассматриваются по отдельности, что усложняет понимание проблемы, либо выводится сразу несколько статистик на ребро, из-за чего граф становится еще менее читабельным. Таким образом, для улучшения понимания и легкости восприятия необходимо выделять или наоборот скрывать информацию.
Данные из примера, полный код, а также пример использования можно найти в git-репозитории. Данные представляют собой процесс возмещения затрат на командировки в университете, оригинальные данные можно найти по ссылке.
В первую очередь необходимо определиться, что для процесса является нормальным поведением, а что является отклонением. Для этого мы можем определить наиболее встречаемые последовательности событий и выбрать из них ту, которая отвечает требованиям идеального процесса.
import pandas as pd
import os
from func import *
import warnings
warnings.filterwarnings('ignore')
log = pd.read_csv('normal_log.csv', sep=';')
log["time"] = pd.to_datetime(log["time"], format="%Y-%m-%d %H:%M:%S")
id_col_name = "ids"
activity_col_name = "events"
time_col_name = "time"
%%time
top_121_sequences = get_top_chain_sequences(log, id_col_name, activity_col_name, time_col_name, seq_count_tresh = 121)
Импортируем необходимые библиотеки, загрузим данные и преобразуем столбец с датой и временем из строкового типа к datetime. Все используемые функции находятся в модуле func в репозитории.
Для примера выведем только 121 самых популярных последовательностей в процессе. Результатом работы функции «get_top_chain_sequences» будет эксель-файл следующего вида:
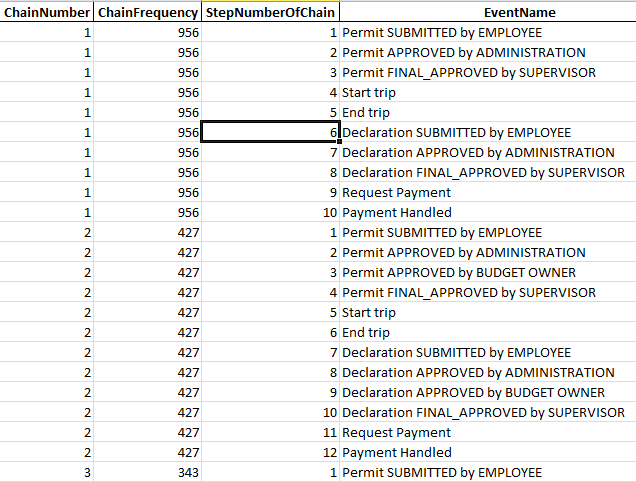
Первый столбец – идентификатор последовательности событий в процессе, второй – сколько раз данная последовательность встречается в логе, третий – порядковый номер события в последовательности, четвертый – имя события.
chain_number = 2
ideal_seq = ["start"]+list(top_121_sequences[top_121_sequences["ChainNumber"]\ ==chain_number]["EventName"].values)+["end"]
ideal_edges = [(str(ideal_seq[i]), str(ideal_seq[i+1])) for i in range(len(ideal_seq)-1)]
Для данного процесса наиболее подходящим является последовательность под номером 2. Добавим в последовательность события «start» и «end», чтобы лучше было видно отклонения на начальных и конечных этапах в логе, и выстроим последовательность в виде пар событий.
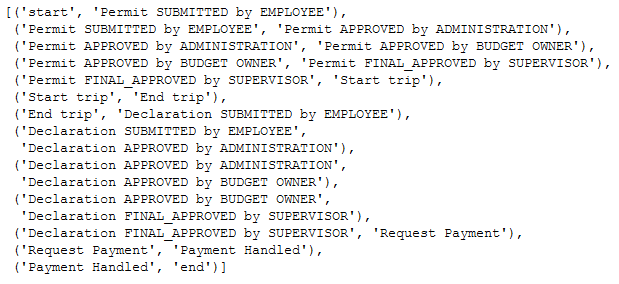
Для вывода статистик посчитаем медианное время и частоту повторений в логе для каждой пары событий.
median_d, counts_d = get_first_statistics(log, id_col_name, activity_col_name, time_col_name)На выходе функции «get_first_statistics» получим 2 словаря, которые содержат обобщенную статистику о каждой паре событий.
Далее создаем словарь, в котором формируем детальную информацию по каждому ребру для визуализации графа.
info_dict, colors_d, width_d = get_info_dict(ideal_seq, ideal_edges, median_d, counts_d)И, наконец, отрисовываем известные пары событий и статистики к ним с помощью инструмента визуализации Vis.js.
create_html(info_dict, colors_d, width_d, html_name="Example_graph")Результатом выполнения функции «create_html» является html файл, в виде интерактивного графа процесса.
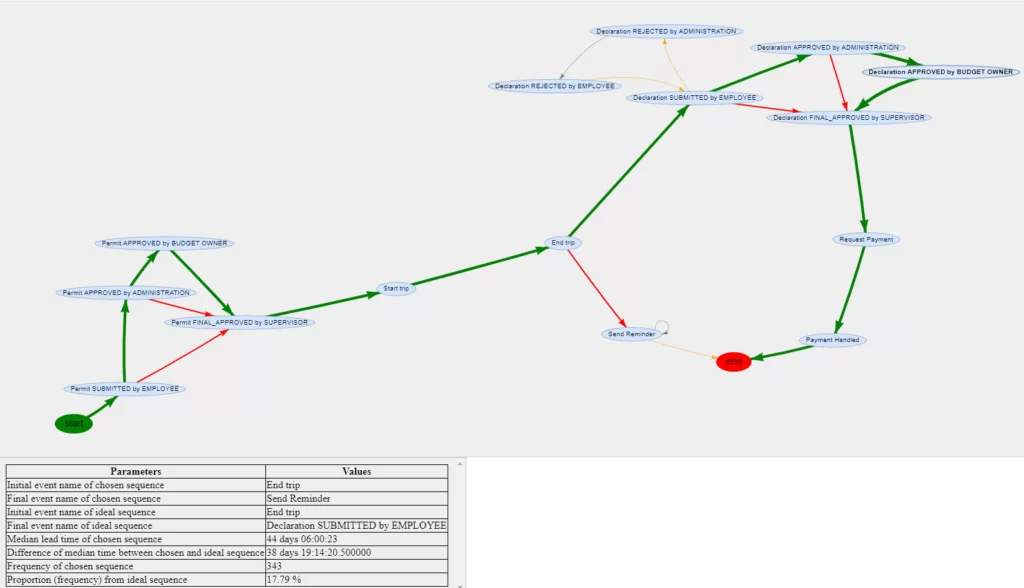
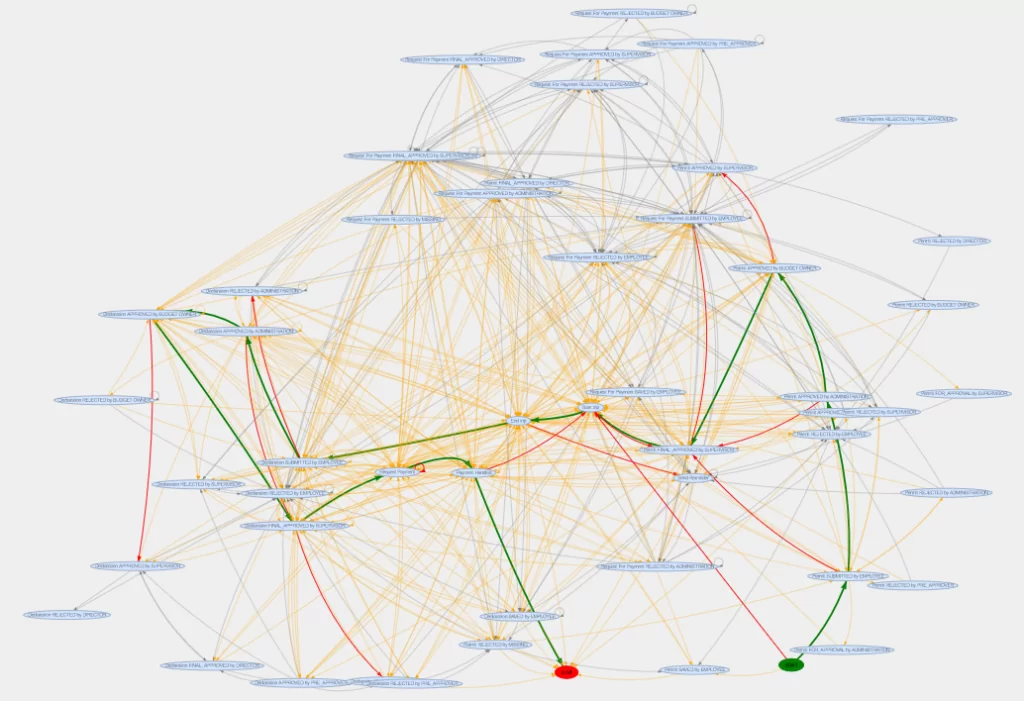
Таким образом, на графе зелеными цветом выделен путь идеального процесса, который мы определили в эксель файле. Желтым цветом выделены ребра, в которых хотя бы одно из событий относится к идеальному процессу. Серым цветом выделены ребра, в которых ни одно из событий не относится к идеальному процессу. Далее для каждого события из идеальной последовательности находим альтернативные пути с наибольшей частотой повторения, которые выделяем красным цветом. Такие альтернативные пути могут быть как единичным отклонением, так и событиями, которые меняют весь путь протекания процесса. Также при нажатии на ребро внизу появляется табличка, в которой указаны различные параметры для пары событий. В первую очередь можно понять, как выбранное ребро должно проходить на самом деле, если одно из событий не относится к идеальной последовательности. Далее указано медианное время исполнения для выбранной пары событий, разница медианного времени между идеальной парой событий и выбранной, частота повторения для выбранного ребра, и доля встречаемости выбранной пары событий от идеальной.
Для примера данные были отфильтрованы для топ 5 последовательностей, на самом деле картинка по всему логу процесса представлена ниже, где наглядно выделяются наиболее значимые события в процессе.