/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Можно ли защититься от парсинга. И зачем это нужно?
Много уже было сказано про парсинг сайтов, целью которого является сбор, обработка и анализ информации. Этот способ позволяет обработать большой массив информации при сравнительно небольших затратах.
Парсинг может применяться практически к любой информации, например, к данным текстовых ресурсов, мультимедийному контенту, данным объявлений, размещённых на специальных сайтах, различным социальным сетям (анализ отзывов и комментариев) и др.
Парсинг может быть использован злоумышленниками и направлен на поиск и сбор личных, в том числе конфиденциальных данных пользователей, его используют с целью кражи исходного HTML-кода страницы, а также для создания идентичных сайтов. Применение парсинга нередко приводит к сбоям и проблемам в работе интернет-ресурсов.
Понятным является желание владельца интернет-ресурса защитить информацию, размещенную на его сайте. Существуют различные способы борьбы с «недобросовестным» парсингом.
Представим несколько способов защиты от парсинга:
Капча (Captcha)
Капча – это компьютерный тест, используемый для того, чтобы определить, кем является пользователь системы: человеком или компьютером. В рамках данного теста предлагается такая задача, которая с легкостью решается человеком, но крайне сложна и трудоёмка для компьютера.
Данный способ представляет наличие лимита на частоту обращений к серверу и заданное число вхождений. Если слишком быстро и часто выполнять некоторые действия подряд, например, поставить 40 лайков или прокомментировать 30 фото, вам придется вводить капчу, тем самым подтвердив, что вы не запрограммированный робот или программа, которая делает определенные действия автоматически, а настоящий пользователь.
Как же реализовать капчу? Очень просто. Если бэкенд вашего сайта написан на Python, можно использовать сторонний модуль captcha:
Установка модуля:
pip install captchaОбращение к модулю создания капчи и дополнительным модулям:
from captcha.image import ImageCaptcha
import random
import stringСоздание «болванки» для будущей капчи:
image = ImageCaptcha(width = 280, height = 90)Генерация случайного текста длиной N символов:
N = 6 # number of symbols in captcha
captcha_text = ''.join(random.choices(string.ascii_uppercase + string.ascii_lowercase + string.digits, k=N))Сохранение картинки:
image.write(captcha_text, 'CAPTCHA.png')У нас получилось создать капчу с текстом: feZ4gH

Алгоритм проверки правильности введённого пользователем текста:
k = 3 # ограниченение количества попыток
k_attempts = 0 # счетчик попыток
while k_attempts < k:
inp = str(input("Введите текст с картинки: "))
if inp.lower() == captcha_text.lower():
print('OK')
break
else:
k_attempts += 1
print('Повторите ввод!')После такой автоматической проверки правильности ввода, можно разрешать пользователю дальнейшие действия.
Но у данного способа есть и свои минусы. Его применение не совсем удобно для самих пользователей, а также высок риск блокировки поискового или другого «хорошего» робота.
В последнее время с развитием автоматических нейронных сетей данный способ защиты утрачивает свою эффективность. Достаточно обучить нейронную сеть на нескольких сотнях примерах, чтобы программа смогла автоматически вводить подобные искаженные изображения, без вмешательства человека. Впрочем, занимаются этим далеко не все создатели парсеров.
Ловушка для роботов (honeypot)
Honeypot дословно переводится как «горшочек мёда». Суть представленного метода заключается в использовании ловушки для роботов. Целью создания подобной ловушки является сбор информации об используемых роботах и изучение стратегии злоумышленников. Данный метод определяет, какой перечень средств может использоваться для атаки на серверы сайта.
Например, ловушка может быть в виде ссылки на сайте, по которой не переходят пользователи, но перейдут роботы, так как эта ссылка является прозрачной и не видимой для человеческого глаза, а ее размер не превышает 1 на 1 пиксель. Робот при поиске необходимой информации будет сканировать сайт и обязательно найдет «невидимую» ссылку.
Если бэкенд вашего сайта написан на питоне, для создания такой ловушки не обязательно использовать сторонние модули. Вам понадобятся стандартные socket и datetime:
Импорт необходимых модулей:
import socket
from datetime import datetimeСоздание функции ловушки:
def honey_pot():
print(f"""{socket.gethostbyname(hostname)};{datetime.now()}\n""")Далее необходимо создать невидимую кнопку и привязать вызов данной функции к этой кнопке. Для иллюстрации я сделал так:

При нажатии на Run Interact, выводится ip – адрес пользователя:

Ловушка – это, конечно, не антивирус и не сетевой экран, она не помогает решать конкретные проблемы безопасности, но позволяет специалистам в области безопасности разрабатывать стратегии по снижению рисков при парсинге сайта или DDoS атаках. Ведь имея адрес клиента, можно много чего сделать, например добавить его в чёрный список.
Создание списков
Пользовательские запросы и обращения роботов можно сегментировать в зависимости от свойств IP-адреса пользователей, предварительно их проанализировав. В большинстве случаев роботы имеют значение hosting или business в свойстве «тип». В результате подобного разделения составляется список роботов для их дальнейшего обнаружения, при наличии фактов негативного воздействия на сайт и блокировке доступа.
Чтобы не заблокировать «хороших» роботов-поисковиков, создается белый список. В данный список включатся роботы, которые получают сведения о веб-страницах, для передачи их пользователям, без анализа собранных данных.
Роботы, поведение которых вызывает подозрение (парсинг сайта, увеличение нагрузки на сайт, которые приводят к проблемам с загрузкой сайта, DDoS атаки на сайт и др.) – вносятся в чёрный список.
Выявив робота с помощью «ловушки» или других методов, можно добавить его ip в черный список, используя следующую функцию:
def append_black_list(ip_addr):
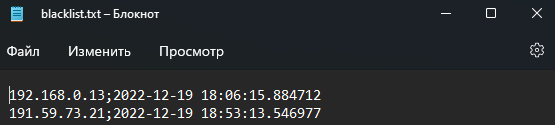
with open('blacklist.txt', 'a') as blacklist:
blacklist.write(f"""{ip_addr};{datetime.now()}\n""")
blacklist.close()
# вызов функции
append_black_list('191.59.73.21')В демонстрационном примере мы использовали простой текстовый файл для хранения списка. В файл сохраняется адрес и время занесения клиента в список:
«Блокнот» был использован только для примера. Если хотите интегрировать эту функцию в бэкенд своего сайта, лучше использовать любую удобную базу данных.
Также списки можно создать, предварительно проанализировав большие объемы данных о работах. Роботы, которые осуществляют парсинг сайтов, имеют определенные особенности или признаки.
Одним из таких признаков может являться, например, PTR запись – используется как инструмент для получения имени хоста (hostname) по IP-адресу. У «белых» роботов она есть, у «чёрных» практически не встречается.
Водяные знаки
Еще одним методом, которой можно использовать для защиты информации на сайте от копирования, является водяной знак.
Водяные знаки применяются для защиты авторских прав следующей цифровой информации: фото, видео, PDF файлы и др. Водяные знаки могут быть как невидимые (скрытые), так и видимые – представлять собой текст или логотип, который идентифицирует автора.
При помощи модуля OpenCV можно вставить водяной знак в любую картинку или видео. Предлагаем рассмотреть на примере:
Установка модуля:
pip install opencv-pythonЧтение оригинальной картинки и водяного знака
img = cv2.imread("sample_pic.jpg")
wm = cv2.imread("watermark.jpg")Получение параметров изображений, ширины и высоты:
h_wm, w_wm = wm.shape[:2]
h_img, w_img = img.shape[:2]Расположим вотермарку по центру. Для этого посчитаем координаты центра:
center_y = int(w_img/2)
center_x = int(h_img/2)Посчитаем координаты «начала» и «конца» водяной марки на изображении:
top_y = center_y - int(h_wm/2)
left_x = center_x - int(w_wm/2)
bottom_y = top_y + h_wm
right_x = left_x + w_wmДобавим водяной знак на картинку, прозрачность сделаем 50%:
transparency=0.5 #прозрачность
coords_wm = img[top_y:bottom_y, left_x:right_x]
result = cv2.addWeighted(coords_wm, 1, wm, transparency, 0)
img[top_y:bottom_y, left_x:right_x] = resultСохраним полученную картинку:
cv2.imwrite('watermarked.jpg', img)Вот, что получилось после применения этого алгоритма на двух картинках:



Конечно, такой метод не защитит от парсинга, но существенно осложнит использование полученных материалов в дальнейшем. Ведь восстановление исходников довольно долгое и трудозатратное занятие, которое охладит соблазн использования данной информации на чужих ресурсах.
JavaScript
Следующий метод, который может существенно затормозить робота и снизить риск парсинга, заключается в применении языка программирования JavaScript при создании фронтенда сайтов. Эффективность использования данного метода состоит в том, что при направлении запроса к серверу браузер отсылает специальные JS-коды, которые сформированы сложной логикой, написанной на JavaScript. При этом часто JS-код этой логики переведен в нечитаемый формат и размещён в одном или нескольких подгружаемых JavaScript-файлах.
Данный метод защиты информации успешно применяют зарубежные социальные сети. Обходится это посредством использования для парсинга реальных браузеров (например, с помощью библиотек Selenium, Mechanize или Chromium). И это даёт данному методу дополнительное преимущество: исполняя JavaScript робот будет проявлять себя в аналитике посещаемости сайта, что позволит довольно быстро распознать неладное.
Минусом данного метода является осложнение работы полезным роботам, а злоупотребление JavaScript на страницах сайта может привести к его просадке при поиске информации или невыполнению запроса.
Проанализировав несколько методов защиты информации от парсинга, хочется отметить, что в настоящее время не существует одного стопроцентно эффективного средства. Любая преграда, используемая для защиты информационного ресурса, может быть преодолима. При этом создать трудности для «недобросовестного» парсинга всё-таки можно. Эффективным способом защиты будет использование не одного метода, а комбинирование нескольких систем, что позволит снизить нагрузку на сайт и отбить большинство атак.
Какой из перечисленных способов защиты информации от парсинга на ваш взгляд самый действенный? Поделитесь своим мнением.