/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Каждый из нас когда-нибудь слышал эту знаменитую фразу ученого и политического деятеля Бенджамина Франклина — «Время-деньги».
Это статья как раз о том, как при наличии дополнительных вычислительных ресурсов, в несколько раз быстрее решить задачу по распознаванию именованных сущностей в текстовых данных, сэкономив драгоценное время.
Нашего заказчика интересовал вопрос соблюдения требований кибербезапосности на одной из части данных автоматизированной системы, с учетом существующих правил разграничения доступа. Основная задача состояла в поиске случаев неправомерного размещения персональных данных в тексте 240 тыс. обращений внутренних клиентов на получение различных услуг сервисных подразделений. С данной задачей мы справились в установленные сроки, но после ознакомления с отчетом о результатах работы, заказчик попросил провести в кратчайшие сроки аналогичную процедуру в отношении данных всей автоматизированной системы. В одночасье, объем нашей задачи вырос в 50 раз!
На обработку такого объема данных (12 миллионов текстовых обращений и 225 тысяч прикрепленных к ним документов) требовалось около 45 дней непрерывной работы одного стандартного персонального компьютера (AMD A10 PRO-7800B R7 – 4 ядра с частотой 3500 MHz, 8 ГБ ОЗУ). В нашем случае обработка данных производилась при помощи предобученной NER Natasha (для поиска: ФИО, даты рождения, адреса регистрации/проживания, суммы денег) и Regular Expression (для поиска: номера счета/карты, телефона, реквизитов паспорта, СНИЛС).
В настоящее время в сети Интернет имеется достаточное количество статей о преимуществах/недостатках NER Natasha в сравнении с другими инструментами распознавания именованных сущностей, мы же в своей статье делимся о инструменте, который позволяет распределить обработку большого массива данных и решить задачу в приемлемые сроки.
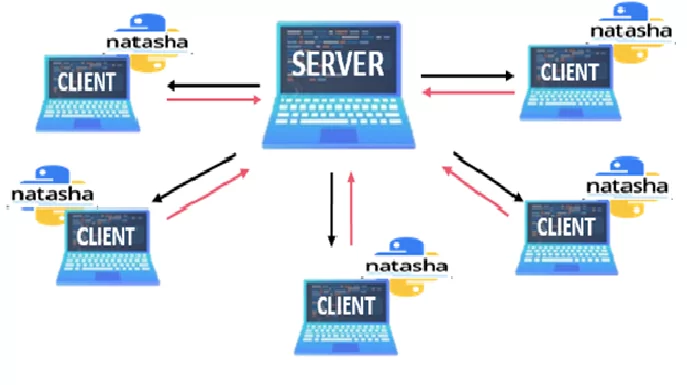
Для сокращения времени обработки текстовых данных до приемлемых 5 дней мы нашли достаточно простое, но эффективное решение — использовали сокеты для запуска одновременной обработки всего объема данных на 10 персональных компьютерах наших коллег. Сокеты обеспечили обмен данными между процессами по сети. С использованием встроенной в Python библиотеки socket, был создан потоковый тип сокета — установлено соединение на основе протокола TCP. Сокет работал по следующему принципу: открытие соединения — извлечение данных – закрытие соединения.
Далее по порядку все частности создания клиент-серверного приложения для запуска одновременной обработки NER Natasha.
Для создания клиент-серверного приложения необходимо создать сокет сервера и клиента.
Пример создания сервера.
1. Создаем сокет.
serv_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
2. Далее определяемся с хостом и портом для нашего сервера. Для доступности сервера для всех интерфейсов строку хоста необходимо оставить пустой. А порт возьмем любой от 0 до 65 535 (число портов ограничено с учетом 16-битной адресации).
serv_sock.bind((‘’,54000))
3. С помощью метода listen переводим сокет в режим «прослушки» — информирование о готовности принимать соединение.
serv_sock.listen(1)
4. С помощью метода accept принимаем соединение. Данный метод ожидает входящего соединения и возвращает связанный сокет и адрес подключившегося.
client_sock, client_addr = serv_sock.accept()
Пример создания клиента
1. Создаем сокет
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
2. Подключаемся к серверу
sock.connect(('localhost', 54000))
3. Делаем запрос на получение данных
sock.send('GET')
4. Считываем данные с сокета и закрываем соединение
data = sock.recv(1024)
sock.close()
5. Отправляем на обработку
NATASHA(data) #Вызов функции
Regularexpression(data) #Вызов функции
Вот так с помощью достаточно простого инструмента нам удалось распределить обработку данных между 10 ПК и сократить сроки выполнения задачи в 10 раз.