/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
В выгрузке больших данных, расположенных внутри таблиц Hive, Data-инженерам помогает фреймворк Spark. Но все ли так просто? Транзакционные таблицы или базы данных клиентов зачастую имеют колоссальный объем, на обработку которого целиком может не хватать мощностей кластера. В данном посте я поделюсь своим опытом работы с большими таблицами в условиях ограниченных вычислительных ресурсов.
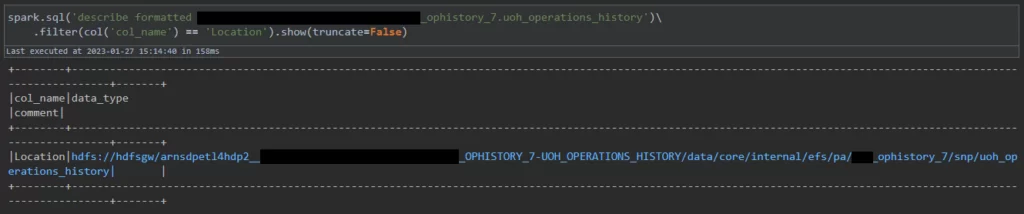
Стандартный метод для обращения к таблице Hive в PySpark – spark.table(tableName). Это не единственный способ получить данные из таблицы, так как её файлы расположены на HDFS, куда Spark тоже умеет заглядывать. Чтобы узнать адрес таблицы в HDFS, нужно написать и запустить запрос describe formatted <имя таблицы>. После выполнения запроса адрес будет расположен напротив поля Location:
Чтобы увидеть содержимое директории таблицы, я пишу в терминале или в ячейке ноутбука Python команду hdfs dfs -ls <путь к таблице>:

В основном огромные таблицы поделены на партиции или, проще говоря, на части. Зачастую партиционирование позволяет обрабатывать данные в Spark быстрее за счёт того, что можно значительно уменьшить количество считываемых данных. Внутри директории таблицы партиции являются дочерними директориями.
Сложность дальнейшей обработки зависит от поля (или полей), по которому ведётся партиционирование. Если инженер таблицы задал в качестве поля партиционирования дату операции, то задача по выгрузке сильно упрощается. Увы, такое встречается не всегда, и партициям просто даются целочисленные идентификаторы.
Сложности могут появиться, если данные в таблице не датируются или распределяются по партициям при их добавлении в таблицу (что крайне маловероятно, но возможно). При таком раскладе мне придётся обрабатывать всю таблицу. Тем не менее, я все еще могу прочитать всю таблицу по частям, просто немного другим способом.
В директориях партиций разложены файлы типа parquet, в которых и находятся все данные таблицы. PySpark умеет считывать файлы parquet пачками – в метод spark.read.parquet() можно передавать по несколько путей к файлам Parquet и/или шаблонов путей, например, так:
parquet_paths = [ # Массив путей к parquet
'hdfs://path/to/table/part=001/002.parquet',
'hdfs://path/to/table/part=001/003.parquet',
]
df = spark.read.parquet(
'hdfs://path/to/table/part=001/001.parquet', # Путь к конкретному parquet
'hdfs://path/to/table/part=01*/*.parquet', # Шаблон пути
*parquet_paths # Распакованный массив строк
)
Отмечу, что символ звёздочки в шаблоне пути заменяет собой произвольную последовательность символов любой длины.
В конфигурацию Spark можно внести параметр spark.sql.parquet.mergeSchema, равный true – это позволит устроить слияние структуры файлов parquet, если они различаются. Есть и другой вариант: я могу передать параметр mergeSchema=True в метод spark.read.parquet(); в таком случае значение в методе имеет приоритет над значением в конфигурации (которое по умолчанию равняется False).
В своем коде, помимо PySpark, я использовал три сторонние библиотеки Python: Pandas, sh и tqdm. Pandas мне понадобится для отсеивания партиций. С помощью sh я смогу не только исполнять консольные команды, но и намного проще получать вывод консоли по сравнению со стандартной библиотекой subprocess. А tqdm предоставляет возможность добавить полоску прогресса для цикла for. Её использовать необязательно, но понимать скорость работы программы желание есть.
Приступаю к написанию кода ноутбука Python. Первым делом мне нужно прописать импорт библиотек и конфигурацию PySpark:
import pandas as pd
from pyspark.sql import DataFrame, SparkSession
from pyspark import SparkConf
from pyspark.sql.functions import col
import sh
from tqdm import tqdm
conf = SparkConf().setAppName('spark_app')
conf.setAll([
('spark.sql.parquet.mergeSchema', 'true'),
<прочие параметры>
])Далее я запускаю PySpark:
spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()В отдельные переменные я выношу имя таблицы и её путь на HDFS:
table_name = 'big_heavy_cumbersome_table'
hdfs_table_path = spark.sql(f'describe formatted {table_name}')\
.filter(col('col_name') == 'Location').toPandas()\
.loc[0, 'data_type']Так как я собираюсь обрабатывать таблицу по частям, то мне надо сохранять результаты по мере процесса. Для этого я создаю временную директорию с помощью команды hdfs dfs -mkdir. При указании параметра -p все родительские директории для конечного пути будут созданы автоматически. Отмечу, что параметры команд нужно передавать в sh в виде отдельных строк.
temp_hdfs_storage = 'hdfs://path/to/my/temp/dir/'
sh.hdfs('dfs', '-mkdir', '-p', temp_hdfs_storage)Плюсом я подготовил небольшую функцию, которая считывает массив данных. На вход подаются путь к таблице на HDFS и список значений полей партиционирования или паркетов. При передаче списка паркетов я буду сообщать функции об этом с помощью флажка. На выходе функция будет выдавать датафрейм Spark.
def read_table_by_parts(hdfs_path: str, parts: list, is_parquets: bool):
if is_parquets:
return spark.read.parquet(*parts)
paths = []
for part in parts:
paths.append(f'{hdfs_path}/{part}/*.parquet')
return spark.read.parquet(*paths)Теперь нужно узнать, есть ли партиции у таблицы или нет. Чтобы проверить их наличие, я использую запрос show partitions <имя таблицы>. Для дальнейшего использования списка партиций я преобразую его из датафрейма Spark в массив.
part_list = spark.sql(f'show partitions {table_name}').toPandas()\
.loc[:, 'partition'].tolist()
# Помечаю, что буду передавать в read_table_by_parts() партиции, а не паркеты
is_parquets = FalseПри наличии партиций я получаю множество всех существующих комбинаций значений полей партиционирования, которые на деле являются частью пути к файлам таблицы. При необходимости я могу дополнительно их отсеять с помощью следующего кода:
partition_cols = [col.split('=')[0] for col in part_list [0].split('/')]
# Разбиваю список партиций на отдельные колонки
partition_values = [[val.split('=')[1] for val in part.split('/')]\
for part in part_list]
partition_df = pd.DataFrame(partition_values, columns=partition_cols)
# Фильтрую партиции по значениям полей
partition_df = partition_df.loc[<фильтры>]
# Возвращаю исходный вид
for col in partition_df.columns:
partition_df[col] = [f'{col}={val}' for val in partition_df[col]]
# Соединяю значения воедино для получения списка партиций
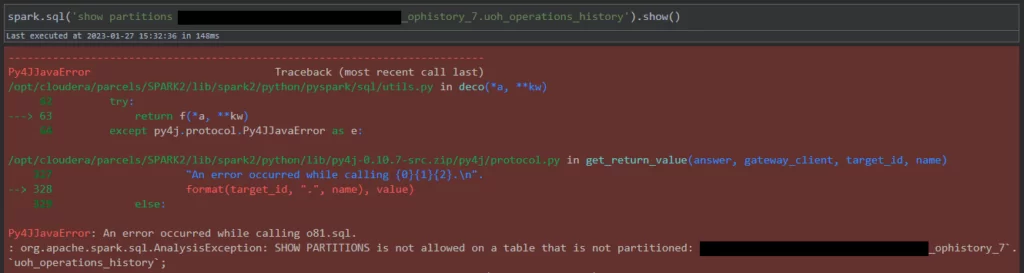
part_list = ['/'.join(row) for _, row in partition_df.iterrows()]Если таблица не партиционирована, то при запросе show partitions выдается исключение. В этом случае нужно понять, как хранятся данные внутри её директории HDFS.
Немногим ранее я упоминал, что sh может не только исполнять команды, но и возвращать вывод консоли. Я могу записать объект запущенной команды в переменную, а затем обратиться к нему как к строке и применить метод split(). Таким образом, я получаю содержимое директории таблицы. Стоит учесть, что первая строка с текстом «Found X items» тоже будет в выводе, и от нее надо будет избавиться.
hdfs_ls = sh.hdfs('dfs', '-ls', hdfs_table_path).split('\n')
part_list = [x.split('/')[-1] for x in hdfs_ls if hdfs_table_path in x]Нельзя сказать вслепую, лежат ли паркеты таблицы в самой директории таблицы или разложены по дочерним директориям. Для этого я снова могу использовать библиотеку sh. Я проверю первый объект в начале списка с помощью команды hdfs dfs -test -d, которая опеределяет, является ли объект файлом:
obj = contents[0]
try:
# Установка флажка на значение False, если объект - это директория
sh.hdfs('dfs', '-test', '-d', f'{hdfs_table_path}/{obj}')
is_parquet = False
except sh.ErrorReturnCode_1:
# Вызвать исключение, если файл не является паркетом
if not obj.endswith('.parquet'):
raise RuntimeError('Нужно проверить другой файл')
# Установка флажка на значение True, если объект - это parquet
is_parquets = TrueТаким способом в автоматическом режиме я могу определить структуру таблицы в HDFS.
Алгоритм обработки будет следующим: я буду собирать пачку партиций или паркетов, считывать их, фильтровать данные и сохранять результаты в мою временную директорию на HDFS в формате parquet. В итоге код выглядит следующим образом:
partition_pack = []
part_pack_size = 1000 # количество частей, считываемых за раз
try:
for i, part_id in tqdm(enumerate(part_list), total=len(partitions)):
# Набираю части таблицы в пачку
partition_pack.append(part_id)
# Считываю данные, если набралась пачка или цикл дошел до последней части
if len(partition_pack) == part_pack_size or i == len(part_list) - 1:
df = read_table_by_parts(hdfs_path, partition_pack, is_parquets)
df.filter(<условие>).write\
.parquet(f'{temp_hdfs_storage}/table_part_{i}.parquet',
mode='ignore')
# Очищаю пачку после сохранения паркета
partition_pack = []
except KeyboardInterrupt:
# При остановке пользователем нужно удалить незавершенный паркет
sh.hdfs('dfs', '-rm', f'{temp_hdfs_storage}/table_part_{i}.parquet')В процедуре сохранения обработанной части таблицы я указал параметр mode, равный «ignore». В этом режиме Spark не будет тратить время на перезапись паркета или выводить исключение, если паркет с таким же именем уже существует.
Объём пачки частей придется подбирать вручную под общий размер таблицы и средний объем партиций. На слишком большую порцию данных может не хватить ресурсов, а слишком маленькие будут читаться очень медленно.
По окончании выгрузки я могу наконец-то объединить все результаты и сохранить в таблицу:
result = spark.read.parquet(f'{temp_hdfs_storage}/*.parquet')
result.write.saveAsTable('result_table')В конце работы мне нужно «прибраться за собой» — а именно удалить временную директорию и закрыть сессию Spark:
sh.hdfs('dfs', '-rm', '-r', '-skipTrash', temp_hdfs_storage)
spark.stop()В итоге, выше написанный шаблон кода можно использовать для загрузки данных по партициям, будь то конкретные части огромной таблицы или вся таблица целиком. Стоит иметь в виду, что программа не является панацеей. Иногда все равно может найтись какая-либо таблица, которая потребует особого подхода. К тому же данные в таблицах не всегда будут храниться в паркетах. Увы, Spark умеет считывать пачкой только определенные форматы, поэтому с большинством иных типов файлов описанный способ выгрузки данных не сработает.
Данный способ загрузки помог мне в решении задачи по обработке большого массива данных в условиях ограниченных ресурсов кластера. Надеюсь, мой опыт поможет и вам. Я постарался подробно всё описать и максимально всё автоматизировать. Если возникнут вопросы, я готов ответить в комментариях.
Спасибо за прочтение.