/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В современном мире, где объем информации растёт с каждым днём, важно уметь ее структурировать, разделять и анализировать внутри групп. Например, ежедневно пользователи социальных сетей получают 1 209 600 новых данных. Так, проблемой разбиения данных занимается классификация – она помогает сократить время на обработку данных и их группировку. Но вручную обрабатывать огромные объемы данных считается уже моветоном, ведь если правильно подать информацию компьютеру, он сможет сделать работу в несколько раз быстрее. В данной статье мы продемонстрируем одни из известных видов классификации текстов и покажем, насколько важен выбор алгоритма для получения определенных конечных результатов.
Данные
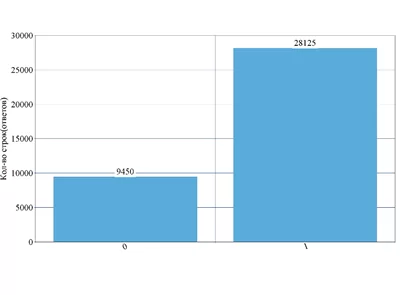
Для нашего исследования в качестве данных мы взяли тексты в файле Excel. Объем файла составлял около 36 тысяч строк. Среднее количество символов в каждой строке таблицы — это предложение, длиной 10-15 слов. Далее эти данные были вручную размечены экспертами на 2 группы, так получилась бинарная классификация (рисунок 1).
Подготовка данных
Важным шагом в анализе данных является предварительная обработка, которая помогает улучшить качество обучения модели. В этот этап входит исключение стоп-слов, приведение всех слов к их первозданному виду, например, глаголов – к начальной форме, а существительных к именительному падежу и единственному числу. А также исключение из текстов ненужных символов и цифр, если в задаче они не имеют смысла, а только нагружают объемом информацию. Мы рассмотрели две библиотеки для естественной обработки базовых задач: Natasha и NLTK, но т.к. первая изначально создана для русского языка – она лучше выявляла слова и работала с ними. Благодаря Natasha мы провели сегментацию на токены и предложения, лемматизацию, извлечение именованных сущностей, морфологический и синтактический анализ (таблица 1). Так, например, предложение «На улице 27 января была зимняя погода» превратилось в «Улица_январь_быть_зимний_погода». Может и звучит предложение для нас уже не так складно, но для векторизации оно идеальное.
| Оригинал слова в предложении | Natasha |
| «на клиентов» | «клиент» |
| «перевела» | «переводить» |
| «договора 1234» | «договор» |
Таблица 1 –Предобработка данных библиотекой Natasha
Сразу поясним, почему мы не убрали слова с ошибками или с английскими буквами – в нашем датасете, если они присутствуют, то скорее всего ответ ведет к 1.
Векторизация
Теперь перейдем к главной задаче нашего исследования. Машинное обучение с использованием естественного языка сталкивается с одним серьезным препятствием – его алгоритмы обычно работают с числами, а естественный язык – это, в общем, текст. Поэтому нам нужно преобразовать этот текст в числа, иначе известная задача как векторизация текста. Это фундаментальный шаг в процессе машинного обучения для анализа данных, и различные алгоритмы векторизации сильно повлияют на конечные результаты. Чтобы приобрести ценность словам для предложений и текста, нужно им придать вес, который и будет показывать силу влияния на ответ принадлежности к классу в нашей задаче.
Tf-idf
Одним из известных способов векторизации является TF-IDF – это показатель, который рассчитывает ценность слова для документа и текста в целом по встречаемости этого слова. Для нашего Excel-файла таким документом считается одна строка таблицы. Для нахождения этого показателя стоит умножить 2 величины, как можно догадаться это:
- TF – term frequency – частота слова в документе, т.е. количество встречаемости уникального слова в строке;
- И непосредственно, IDF – inverse term frequency – обратная частота слова в документе. Это величина измеряет сколько слово встречается во всех строках таблицы.
Теперь посмотрим, как можно построить TF-IDF с помощью кода, возьмем за Documents весь файл:
from gensim.models import TfidfVectorizer
for i in range(len(Documents)):
Documents[i] = re.sub(r"[\d+_]", "", Documents[i], flags=re.UNICODE)
vectorizer = TfidfVectorizer(lowercase = True)
matrix = vectorizer.fit_transform(Documents)
Positions = {}
j=0
for word in vectorizer.get_feature_names():
Positions[word] = j
j=j+1
amountWords = len(vectorizer.get_feature_names())
Tf_idf = pd.DataFrame(matrix.toarray(), columns = Positions.keys(), index = Sentences_by_tag.keys()).
Так, используя уникальные значения слов и их веса мы можем построить матрицу для наглядности работы алгоритма:

Word2vec
Еще один популярный способ векторизации word2vec – это группа связанных моделей, которые используются для создания так называемых встраиваний слов. Эти модели представляют собой неглубокие двухслойные нейронные сети, которые обучены восстанавливать лингвистические контексты слов. После обучения модели word2vec можно использовать для сопоставления каждого слова с вектором, обычно состоящим из нескольких сотен элементов, которые представляют отношение этого слова к другим словам, так и получается векторизация. Чтобы использовать этот метод, мы решили взять модель word2vec из библиотеки Gensim, и также векторизовали с помощью нее наши слова:
from gensim.models import Word2Vec
model = Word2Vec(Corpus_list,min_count=1,size = 100).
Затем мы решили также векторизовать предложения по их среднему значению вектора, взяв за wordsN корпус:
mean_v_list = []
for sent in wordsN:
mean_v = np.zeros(100)
count=0
for w in sent:
if w not in w2v:
count+=1
break
else:
mean_v = mean_v + model.wv.get_vector(w)
mean_v = mean_v / (len(sent)-count)
mean_v_list.append(mean_v)
Сравнение результатов
Теперь, когда у нас получилось несколько векторизованных текстов, давайте их сравним. Пока модели показывают примерно одинаковые результаты, и сложно оценить, как они поведут себя при машинном обучении на наших текстах. Так, давайте запустим их на модели, которая не придирчива к входным данным – градиентный бустинг XGBoost. На вход подадим соотношение 75/25 обучающей и тренировочной выборки. Тогда точность моделей будет следующей:
- Tf-idf – 91%;
- А вот при word2vec модель показывает результат в 100%, но это не потому что она идеально может предсказывать, где 0, а где 1. Здесь произошло переобучение.
Проблема переобучения заключается в дальнейшем предсказании ответов на новой выборке – она слишком хорошо работает на наших данных, но, когда мы ей подкинем новые – начнет ошибаться. Причины поведения модели word2vec могут заключаться в следующем:
- Совмещение word2vec и xgboost не подходит для наших данных. Т.к. процент единиц в целевой выборке составляет примерно 10%, то содержимое почти однородное для нашей машины, и ответы могли быть везде обобщены к нулю.
- Мы неправильно подобрали параметры.
- Выборка плохо перемешана – возможно все единицы попали в обучающую выборку и алгоритм натренировался хорошо предсказывать ноль.
После переобучения модели с word2vec мы откинули этот вариант векторизации для наших данных. И сделали следующие выводы.
Выбор алгоритма даже для векторизации слов и предложений очень важный этап. Нужно изначально посмотреть на данные, оценить их сложность, размерность и какую смысловую нагрузку они несут. Можно получить высокие результаты, переобучив модель или просто правильно выбрать методы. Даже самый простой и популярный алгоритм может показать результаты выше новых и сложных. Качественная подготовка данных – залог успеха в машинном обучении.