/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
Очень часто в задачах текст майнинга требуется реализовать вытаскивание имён, года рождения, паспортных данных и т.п. из объемного текста. Для получения ФИО из текста существует библиотека “Natasha”. Но, когда имена в тексте попадаются “нестандартные” и очень редкие, библиотека, к сожалению, пасует. Также сложности появляются, когда ФИО находится не в именительном падеже, и/или имя и отчество записаны инициалами, да ещё и с неправильными знаками препинания и отступами. Плюс ко всему, мало того что “Natasha” может неверно извлечь ФИО, так ещё его нужно привести к нормальной форме (именительный падеж). Для этого существуют некоторые библиотеки, но справляются они также не со всеми именами, да и если “Natasha” неверно извлекла имя, дальнейшая лемматизация ФИО не имеет значения.
Итак, попробуем сделать алгоритм, который с лучшей точностью решает задачу извлечения имени из текста конкретно под наши данные и нужды, затем сделаем небольшое сравнение с отработкой готовых библиотек. Конечно же, как базовый инструмент использовать будем регулярные выражения :).
Следует заметить, что все дальнейшие имена в примерах были случайным образом изменены в силу политики конфиденциальности, любое совпадение с реальными людьми — случайно.
Итак, имеется огромная таблица с интересующей нас колонкой, в которой данные имеют следующий вид:

Вот в таком разнородном стиле заполнено много сотен тысяч строк с уймой опечаток, ошибок, неточностей.
Ладно, вооружимся регулярными выражениями и попробуем решить задачу. Для начала напишем несколько функций.
def text_is_upper(text):
"""Функция определения написан текст заглавными буквами и строчными"""
text = re.sub('[^А-Яа-я]', '',text) # Убираем лишние символы
try:
# % загл. букв
percent_upper = sum(map(str.isupper, text)) / len(text)
if percent_upper > 0.8: # Загл. букв больше- строка капсовая
return True
else:
return False
except Exception as e:
return False
def find_name(text):
"""Функция поиска ФИО"""
text = str(text) # Для уверенности переводим в строку
text = text.replace('Ё','Е')
text = text.replace('ё','е')
# Удаляем двойные пробелы:
text = re.sub(r'\s+',' ', text)
# Ищем паттерн Урова Елена Михайловна / ГЛУХИХ АННА АЛЕКСЕЕВНА
# name = None # Инициализация переменной вытянутого имени
""" Паттерн:
Первое слово - Загл. буква, далее не пробел, не точка,
не запятая, далее могут идти строчные буквы
Второе слово - Заглавная буква + строчные
или одна заглавная как инициал
После - пробел или точка для отделения инициала
Третье слово - аналогично второму.
(Урова Елена Михайловна, ГЛУХИХ АННА АЛЕКСЕЕВНА, Заяц А.О) """
pattern = r'((\b[A-Я][^A-Я\s\.\,][a-я]*)(\s+)([A-Я][a-я]*)'+\
'(\.+\s*|\s+)([A-Я][a-я]*))'
# Если строка не написана капсом:
if not text_is_upper(text):
name = re.findall(pattern, text)
# Разбиваем ФИО на три строки Ф, И, О:
if name:
FIO = name[0][0].replace('.',' ')
FIO = re.sub(r'\s+',' ', FIO).split(' ')
if len(FIO) >= 3:
return FIO[0], FIO[1], FIO[2]
elif len(FIO) == 2:
return FIO[0], FIO[1], 'пусто'
elif len(FIO) == 1:
return FIO[0], 'пусто', 'пусто'
else:
return 'пусто','пусто','пусто'
# Если строка капсовая:
else:
# Определяем по слову перед ФИО :(
try: # Индекс, откуда начинается ФИО осужденного:
start_number_index = re.search(
r'(\bосужд\w{0,} )|(\bосужд\. )',
text, flags=re.I).end()
text_cut = text[start_number_index:]
FIO = text_cut.replace('.',' ')
FIO = re.sub(r'\s+',' ', FIO).split(' ')
if len(FIO) >= 3:
return FIO[0], FIO[1], FIO[2]
elif len(FIO) == 2:
return FIO[0], FIO[1], 'пусто'
elif len(FIO) == 1:
return FIO[0], 'пусто', 'пусто'
except Exception:
return 'пусто','пусто','пусто'
Ниже df[‘Purpose’] — колонка таблицы, где находится интересующий нас текст.
# Получаем общую колонку ФИО соответсвует с 3мя ответами
df['ФИО'] = df['PURPOSE'].apply(lambda text: find_name(text))
# Распределяем на три столбца
df['Ф'] = df['ФИО'].apply(lambda x: x[0])
df['И'] = df['ФИО'].apply(lambda x: x[1])
df['О'] = df['ФИО'].apply(lambda x: x[2])
df = df.drop(['ФИО'], axis=1)
Вот так с помощью “регулярок”, мы предварительно вытащили ФИО из текста и разделили по разным столбцам. Поехали дальше… Теперь хотелось бы определить в каком падеже находится наше имя (соответственно фамилия и отчество тоже будут в этом падеже). Поступим так: для начала с какого-нибудь сайта сделаем выгрузку мужских и женских имён. Пример полученного файла с именами:
В коде ниже готовые тестовые файлы со списком имён называются “мужские имена.txt” и “женские_имена.txt”. Сформируем из текстовых данных списки и добавим в них некоторые редкие имена, отсутствующие в исходном файле, но присутствующие в наших данных (это делается путём прогонки алгоритма и сортировкой результатов по неотработанным именам).
male_names = open('мужские имена.txt', encoding = 'utf-8').read()[1:]
female_names = open('женские имена.txt', encoding = 'utf-8').read()[1:]
list_male_names = male_names.lower().split('\n\n')
list_female_names = female_names.lower().split('\n\n')
# Добавим редкие имена, которые встречаются в нашей таблице:
list_male_names.extend(['эдуард', 'айдар', 'алик', 'рустам',
'ильдар', 'азамат','равиль','альбек',
'магомед','яков','радион','вугар','дамир',
'марсель','радик','ильгиз', 'аким', 'ашот',
'наиль', 'рафаииль','эрик', 'ильсур',
'роберт','ленар','кайрат','арсен',
'гаврил','камиль','феликс'])
list_female_names.extend(['зинаида', 'марса','анжела', 'зуфара',
'лиана','камила','лиа','дария','даниэла',
'леся','роза','юлианна','дина'])
list_male_names = list(map(lambda x: x.replace('ё','е'),
list_male_names))
list_female_names = list(map(lambda x: x.replace('ё','е'),
list_female_names))
Список имён получили. Далее пробуем пройтись по полученному столбцу df[‘Имя’] и преобразовать имя в именительный падеж при необходимости. Вся логика основана на окончании слова, в коде ниже есть комментарии 🙂
def percent_similarity(comparing_name, list_of_names):
""" Функция сравнения имён """
if comparing_name.lower() in list_of_names:
# если извл.имя есть в списке имён - оно в им.п.:
return comparing_name
# ПавлЕ, ПавлУ, ПавлОМ... (одно из имен не подх.под алгор.):
if comparing_name.lower().startswith('павл'):
return 'павел'
# Если имени нет в списке имен в им.падеже, ищем в др. падеже:
for name_from_list in list_of_names:
# Если извлеченное имя длинее имени из списка имен:
if len(comparing_name) > len(name_from_list):
# Ищем имя из списка:
# Родительный падеж
if comparing_name[:-1] == name_from_list: # ТимурА>Тимур
return name_from_list # им. падеж возвращаем
break
# Творительный падеж
elif (comparing_name[:-2] == name_from_list[:-1] and \
comparing_name[-2:] == 'ем') or \
(comparing_name[:-2] == name_from_list and \
comparing_name[-2:] == 'ом'): # ВикторОМ, РоманОМ...
return name_from_list # АлексеЕМ, ВиталиЕМ...
break
# Если длина имени одинаковая и отл. буква в конце слова
elif len(comparing_name) == len(name_from_list) and \
comparing_name[:-1] == name_from_list[:-1]: # ОльгЕ > ОльгА
return name_from_list
break
# Преобразуем мужское и женское имена в им.падеж
df['Имя_мужское_им.падеж'] = df['И'].apply(
lambda name: percent_similarity(name.lower(), list_male_names))
df['Имя_женское_им.падеж'] = df['И'].apply(
lambda name: percent_similarity(name.lower(), list_female_names))
df['Имя_мужское_им.падеж'] = df['Имя_мужское_им.падеж'].fillna('пусто')
df['Имя_женское_им.падеж'] = df['Имя_женское_им.падеж'].fillna('пусто')
Так, получили именительный падеж имён для мужских и женских имён. Но ведь у нас встречаются имена, которые применимы и к женщине, и к мужчине. Например, женское имя Александра может быть воспринято как мужское имя Александр в родительном падеже (У Александра есть яблоко).
Вот тут-то нам придёт на помощь отчество. Нехитрыми соображениями о том, как склоняется отчество в разных падежах, попробуем понять, о ком идёт речь в тексте: о мужчине или о женщине.
def choose_F_M_name(M_name, F_name, Patronymic):
"""Функция определения имя относится к мужчине
или женщине (напр. Александра - Александр, Евгения - Евгений)"""
# Если percent_similarity определила и женское, и мужское имя:
if M_name != 'пусто' and F_name != 'пусто':
# Как правило, предпоследняя буква отчества у женщин - "н".
# "ИгоревНе, НиколаевНа". Поэтому смотрим пред.букву
try:
if Patronymic[-2].lower() == 'н':
M_name = 'пусто' # если есть "н" - удаляем муж. имя
else:
F_name = 'пусто' # если нет "н" - удаляем жен. имя
except:
pass
return M_name, F_name
# Удаляем мужское/женское имя при дублировании
df['transit'] = df.apply(lambda x:choose_F_M_name(
x['Имя_мужское_им.падеж'],
x['Имя_женское_им.падеж'],
x['О']), axis = 1)
df['Имя_мужское_им.падеж'] = df['transit'].apply(lambda x: x[0])
df['Имя_женское_им.падеж'] = df['transit'].apply(lambda x: x[1])
df = df.drop(['transit'], axis = 1)
Получили имена в именительном падеже. Посмотрим, что у нас имеется:
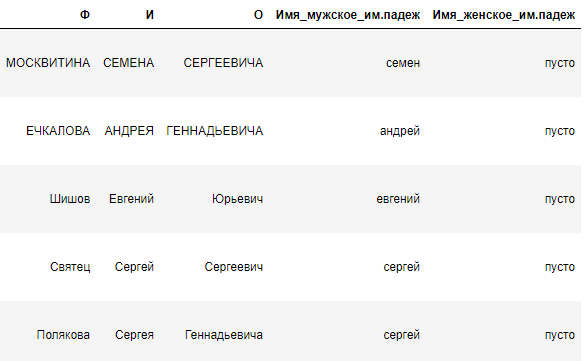
Теперь нужно что-то сделать с фамилией и отчеством. Будем проверять, если имя было преобразовано в именительный падеж (значения для каждого объекта в столбцах вытянутого имени и имени в именительном падеже разнятся), тогда пытаемся преобразовать отчество и фамилия. Опять же, всё делается из соображений по окончаниям слов в разных падежах.
def surname_patronymic_nominative(M_name,F_name,F,O,I):
"""Функция преобр. фамилии и отчества в им. падеж"""
"""Если имя уже было преобразовано в именительный"""
F_new, O_new = F,O # Инициализируем текущими значениями
F, O = F.lower(), O.lower()
# Мужчина Male:
if M_name != I.lower() and M_name != 'пусто':
if F[-1:] == 'а': # Род.падеж
F_new = F[:-1] # ЕвстифеевА > Евстифеев
elif F[-2:] == 'ым': # Твор.падеж
F_new = F[:-2] # ЕвстифеевЫМ > Евстифеев
elif F[-5:] == 'ского': # Твор.падеж
F_new = F[:-5] +'ский' # РяховСКОГО > РяховСКИЙ
elif F[-5:] == 'цкого': # Твор.падеж
F_new = F[:-5] +'цкий' # МудиЦКОГО > МудиЦКИЙ
else:
F_new = F # Соловых > Соловых
if O[-1:] == 'а': # ИгоревичА > Игоревич
O_new = O[:-1]
# Женщина Female:
elif F_name != I.lower() and F_name != 'пусто':
if F[-4:] == 'ской': # Род.падеж
F_new = F[:-4]+'ская' # СлабинСКОЙ > СлабинСКАЯ
elif F[-4:] == 'цкой': # Род.падеж
F_new = F[:-4]+'цкая' # ХмельниЦКОЙ > ХмельниЦКАЯ
elif F[-2:] == 'ой': # Род.падеж обычное окончание
F_new = F[:-2]+'a' # ХлебниковОЙ > ХлебниковА
else:
F_new = F # Кличко > Кличко
if O[-1:] == 'ы': # МихайловнЫ > МихайловнА
O_new = O[:-1]+'a'
if len(F_new) > 1 and len(O_new) > 1: # Возвращаем фам. и отч.
return F_new[0].upper()+F_new[1:], O_new[0].upper()+O_new[1:]
else:
return F_new, O_new # Возвращаем инициалы
# Формируем фамилию и отчество в именительном падеже,
# Если имя было трансформировано в именительный:
df['Фамилия_Отчество_именительное'] = df.apply(
lambda x: surname_patronymic_nominative(x['Имя_мужское_им.падеж'],
x['Имя_женское_им.падеж'],
x['Ф'],x['О'],x['И']), axis=1)
df['Фам_им'] = df['Фамилия_Отчество_именительное'].apply(lambda x: x[0])
df['Отч_им'] = df['Фамилия_Отчество_именительное'].apply(lambda x: x[1])
df = df.drop(['Фамилия_Отчество_именительное'], axis=1)
Посмотрим, что мы имеем теперь. ФИО есть в именительном падеже:
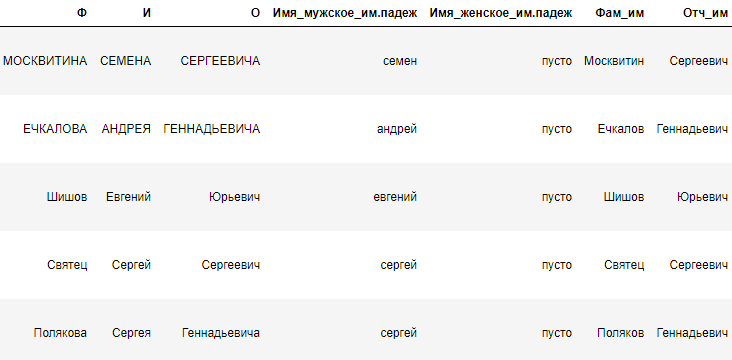
Далее почистим ненужные столбцы. И посмотрим, где имя и отчество записаны как инициалы.
def Finaly_name(M_name, F_name):
"""Получаем итоговое имя"""
if M_name != 'пусто':
return M_name[0].upper()+M_name[1:] # мужское имя в им.пад
elif M_name == 'пусто' and F_name != 'пусто':
return F_name[0].upper()+F_name[1:] # женское имя в им.пад
# Получаем одну колонку имени. Мужской и женский варианты del
df['Имя_им'] = df.apply(lambda x:
Finaly_name(x['Имя_мужское_им.падеж'],
x['Имя_женское_им.падеж']),axis=1)
df = df.drop(['Имя_мужское_им.падеж', 'Имя_женское_им.падеж'],axis=1)
cols = ['PURPOSE', 'Ф', 'И', 'О', 'Фам_им',
'Имя_им', 'Отч_им', 'CLIENTDATE']
df = df[cols] # Оставили нужные нам столбцы
# Заполним имя_им, где остались пропуски, значением вытянутого
df['Имя_им'] = df['Имя_им'].fillna(df['И'])
# Посмотрим, где инициалы в ИО
df[df['И'].apply(lambda x: len(x)==1)].head()
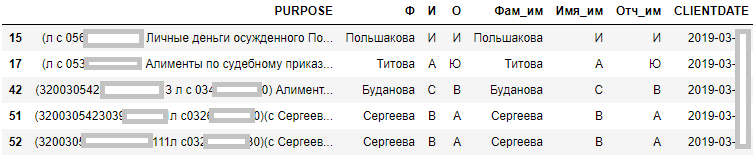
Так как фамилии с «а» в окончании могут принадлежать мужчине в родительном падеже и женщине в именительном, нужно понять, как будем это различать. Попробуем выяснить, сколько мужчин и сколько женщин получилось в нашей выборке.
df['Male_Name'] = df['Имя_им'].apply(lambda x: x.lower() in list_male_names)
df['Female_Name'] = df['Имя_им'].apply(lambda x: x.lower() in list_female_names)
print ('Соотношение мужских имён к женским:',
df['Male_Name'].value_counts()[1]/df['Female_Name'].value_counts()[1])
df = df.drop(['Male_Name', 'Female_Name'], axis=1)
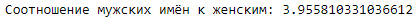
Мужских имён значительно больше в нашей таблице. Будем определять окончание «а» как родительный падеж мужского имени. Осталось отделить несклоняемые фамилии от склоняемых.
def surname_nominative(F):
"""Функция преобр.фамилии в им.падеж, где имя, отч.инициальные"""
try:
# Мужские фамилии:
if F[-1] == 'а' and F[-2] != 'х': # ПетруХа: ха.. не склоняем
return F[:-1] # Муж. фамилия в род.пад
elif F[-2:] == 'ым':
return F[:-4] # Муж. фамилия в твор.пад
elif F[-5:] == 'ского':
return F[:-5] + 'ский' # Муж. фамилия в твор.пад
elif F[-5:] == 'цкого':
return F[:-5] + 'цкий' # Муж. фамилия в твор.пад
# Женские фамилии:
elif F[-4:] == 'цкой':
return F[:-4] + 'цкая' # Жен. фамилия в твор.пад
elif F[-4:] == 'ской':
return F[:-4] + 'ская' # Жен. фамилия в твор.пад
elif F[-2:] == 'ой':
return F[:-2] + 'а' # Жен. фамилия в твор.пад
else:
return F # Без изменения
except Exception as e:
return F
# Преобр. фамилию у инициальных ИО в им.падеж
list_index = df[df['Имя_им'].apply(
lambda x: len(x)) == 1].index.tolist()
df['Фам_им'][list_index] = df['Фам_им'][list_index].apply(
lambda x: surname_nominative(x))
df[df['Имя_им'].apply(lambda x: len(x)) == 1].head(5)
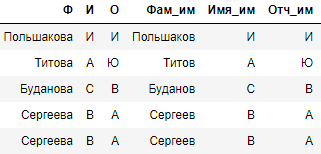
Готово. Теперь на некоторых более-менее ярких примерах сравним результаты отработки готовыми библиотеками и нашим алгоритмом.
Пример отработки готовыми библиотеками:

Колонки с индексом “_1” здесь несут ФИО, вытянутое “Наташей”, с индексом “_2” – финальное ФИО в именительном падеже лемматизированное какой-то библиотекой.
Нетрудно заметить, что результат очень “так-себе”.
Посмотрим, как справился с этими полями наш алгоритм:

Алгоритм отработал на данных примерах замечательно.
Так мы убедились, что под специфичные задачи иногда бывает выгодно (по соотношению трудозатраты/качество) сделать собственный алгоритм, нежели использовать какие-либо готовые решения. Конечно, текущий алгоритм не идеален, и его можно дорабатывать и дальше, но текущее качество отработки удовлетворяет требованиям, поэтому дальнейшие “допилы” нецелесообразны 😊.