/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Еще раз, «Что такое Process Mining?»
Традиционный подход к анализу бизнес-процессов состоит в интерпретации модели процессов со слов непосредственных участников этих бизнес-процессов и анализа множества бумажных документов и оперативных отчетов. Недостаток такого подхода в трудозатратах. Учитывая рост объема данных и скорость изменений в бизнесе, подобные методы уже не позволяют эффективно исследовать процессы. Кроме того, такой подход может дать ложные результаты из-за неполноты информации и субъективности участников процесса. Уровень автоматизации растет, поэтому совершенно логично рассматривать процессы на основании логов информационных систем (ИС). В этом и заключается хитрость инструментария Process Mining, который может на основании факта работы людей в той или иной ИС восстановить фактическую модель бизнес-процесса, что позволит увидеть, как же этот процесс выглядит в действительности. Иллюстрация приведенная ниже хорошо отражает основную задачу Process Mining – найти нестандартные пути или исключительные ситуации — «тропинки», которыми ходят сотрудники, и возможно ходят массово.
«С чего начать?»
Многие, отвечая на этот вопрос допускают ошибку. Ответ, казалось бы, очевидный – подготовка логов, но это не совсем так. Перед тем как приступить к подготовке данных лога ИС, необходимо понимать сам анализируемый процесс. Это не менее важный этап, т.к. без понимания и погружения в регламентируемый процесс не удастся корректно структурировать данные для создания таблицы и дать оценку реальному процессу. Итак, условно можно выделить несколько этапов в процессной аналитике:
- Понимание регламентируемого процесса
- Сбор и подготовка логов ИС
- Анализ процесса AS IS
- Поиск «узких мест» и отклонений от регламентируемого процесса
«Везде говорится о каких-то логах… Да что это вообще такое?» или «Какие они, исходные данные?»
Поиск, сбор логов ИС и подготовка исходных данных занимает более 50% от всего времени, затраченного на процессную аналитику, этот этап по праву можно назвать самым важным и ответственным. Давайте разберемся что такое лог ИС. Лог, он же журнал событий — это подробный протокол, содержащий системную информацию о действиях пользователей в хронологическом порядке. Лог содержит огромное множество записей, каждая строка которой — это одно взаимодействие с программой. Для использования инструментов Process Mining необходимо в логе ИС выделить следующие обязательные столбцы:
- Case id – идентификатор процесса
- Activity – событие, действие, статус процесса
- Timestamp – дата и время регистрации события
Настоятельно рекомендуется не ограничивать себя только минимальным набором колонок. Граф процесса можно будет успешно восстановить и по трем обязательным столбцам, но избавиться от ощущения, что чего-то не хватает, будет сложно. Дополнительные колонки – это любая интересная вам информация, которая изменяется с течением процесса или связана с конкретным событием. Например, имя сотрудника, который совершил событие, рабочая группа, текущий приоритет заявки.
Рассмотрим всем понятный процесс – процесс подбора персонала. Каждый, как минимум, один раз принимал в нем непосредственное участие. Представим, что по регламенту процесс (activity) выглядит так:
- Поиск резюме
- Согласование резюме
- Организация встречи с HR
- Собеседование с HR
- Организация встречи с руководителем
- Собеседование с функциональным руководителем
- Организация встречи с генеральным директором (ГД)
- Собеседование с ГД
- Уведомление о решении ГД
И имеет три варианта завершения:
- Передача документов на оформление
- Отказ кандидату
- Поступил отказ от кандидата
«Лог готов, что дальше?»
А дальше выбираем инструмент для визуализации нашего процесса. Среди наиболее популярных готовых инструментов можно выделить Fluxicon Disco, ProM и Celonis (обзор на данные инструменты в сообществе NTA можно посмотреть по ссылкам раз и два). И конечно же нельзя не упомянуть библиотеку с открытым исходным кодом PM4PY для Python, более подробно о которой уже рассказали здесь. Подход к выбору инструмента субъективен и остаётся за Вами. Для получения графа реального процесса подаём на вход инструменту лог файл и определяем сущности (case id, activity, timestamp).
Для построения графа нами использован популярный инструмент — онлайн-платформа Celonis и готовый лог в формате *.csv, содержащий ключевые сущности:
- case id – ID заявки подразделения на подбор специалиста;
- activity – этапы процесса подбора персонала;
- timestamp – информация о дате и времени проведения этапы процесса подбора персонала. В нашем примере взят следующий формат даты: dd.mm.yyyyHH:MM:SS.
«И что мне делать с этой лапшой?»
На выходе мы получили весьма сложный и запутанный граф.
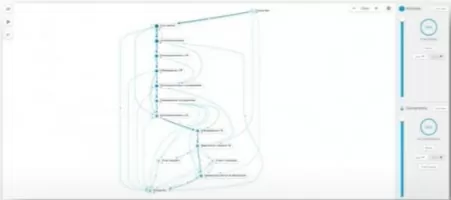
Используя стандартные возможности онлайн-платформы Celonis для начала отфильтруем незавершенные (не «зависшие», а именно незавершенные по времени) экземпляры в бизнес-процессе.
Далее убираем вероятности самых сложных бизнес-процессов, т.е. самых длинных и маловероятностных экземпляров, для этого в большинстве готовых инструментов уже реализована возможность добавлять либо убирать связи-переходы между действиями (событиями), а также сами действия (события), что позволяет увидеть наиболее частотные действия и наиболее частотные переходы и управлять этой визуализацией. Таким образом добиваемся читабельности реального процесса.
Слева изображен регламентируемый процесс, справа – процесс на основании лога ИС.
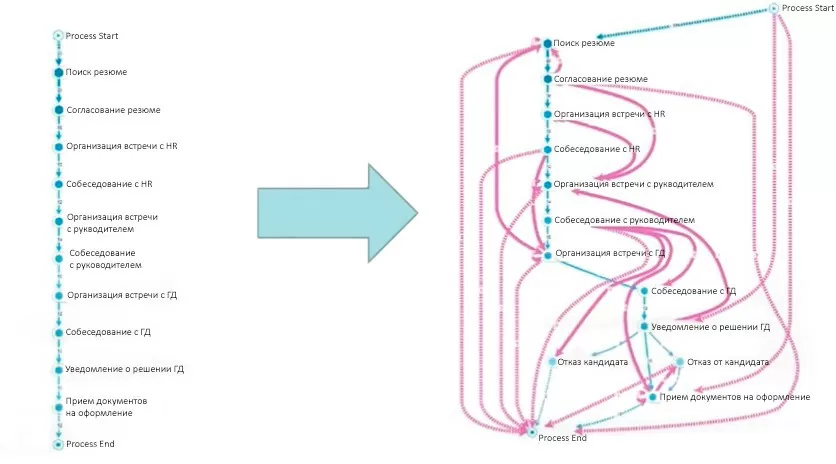
Фактически на данном этапе мы разобрались какие экземпляры у нас «нормальные», т.е. какой основной поток в рамках бизнес-процесса; разобрались почему возникли исключительные случаи и отклонения от основного потока. Здесь нам помогли встроенные инструменты фильтрации: временные фильтры, фильтры экземпляров процессов по производительности, фильтры неполных экземпляров процессов и фильтры событий по атрибутам.
Что искать?
Анализируем незаконченные экземпляры в процессе. Накладываем фильтр тех экземпляров бизнес-процесса, которые не завершились отказом кандидату, отказом от кандидата или передачей документов на оформление и получаем представление о том, как выглядят не дошедшие до конца или зацикленные экземпляры бизнес-процесса.
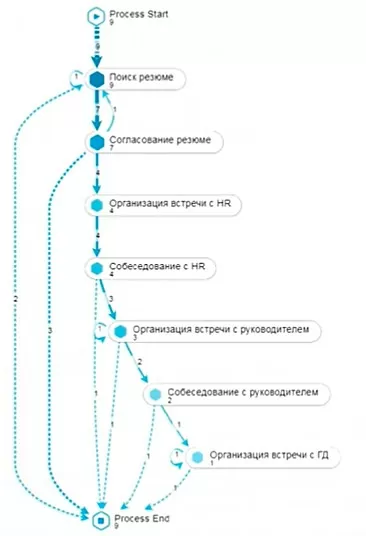
Здесь мы акцентировали свое внимание на следующих ситуациях:
— цикл на этапе поиска резюме – это значит, что операция поиска резюме была повторена несколько раз;
— цикл на этапе «Организация встречи с руководителем» – вполне возможно, что руководитель не назначает встречу, поэтому экземпляр процесса никак не может закончится;
— цикл на этапе «Организация встречи с ГД».
Еще одним вариантом анализа является поиск «петель согласования». Это те места, или элементы, в процессе, с которых поток работ часто возвращается обратно – на доработку, тем самым увеличивается общее время исполнения бизнес-процесса и возрастает его стоимость.
Мы выделили на общей модели возврат и обнаружили, что у нас есть некий цикл между этапами «Согласование резюме» и «Поиск резюме».
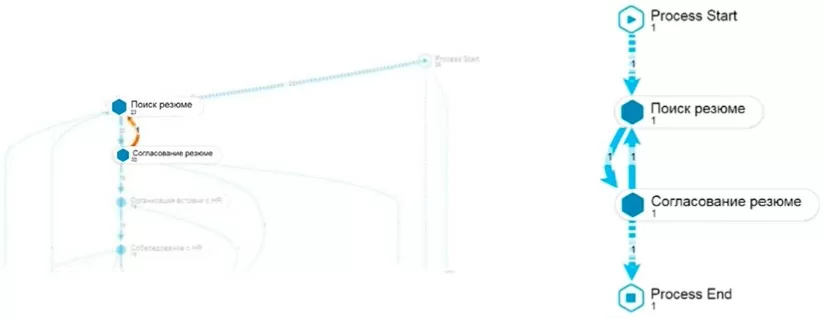
Таким образом мы видим зацикливание («пинг-понг») в процессе и выделяем те экземпляры, которые сопровождают данный «пинг-понг». Для более детального анализа мы «ныряем вниз» непосредственно к самим экземплярам процесса и видим какие именно это вакансии, кто исполнитель, когда это произошло и т.д.
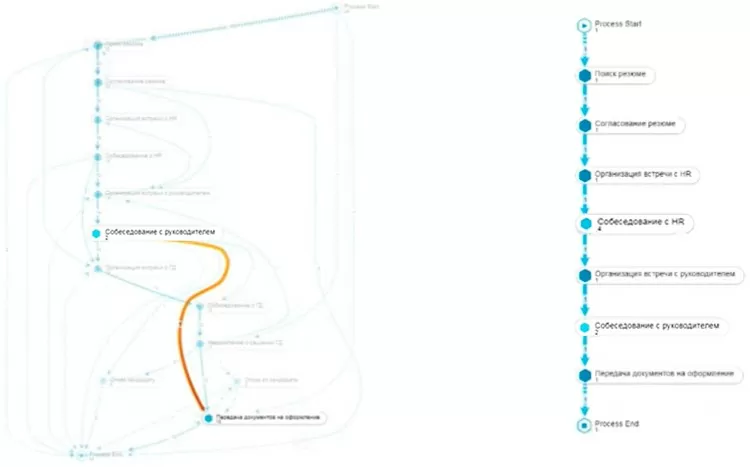
Следующий вариант – анализ завершенных процессов. Рассматриваем экземпляры, которые завершились успехом — накладываем фильтр на финальное действие «Передача документов на оформление». Ищем те случаи, когда финальный результат получен в нарушение регламента. Выделяем на общей схеме прыжок от этапа «Собеседование с руководителем» на финальный этап «Прием документов на оформление». Таким образом находим кандидатов, принятых минуя этап согласования с ГД.
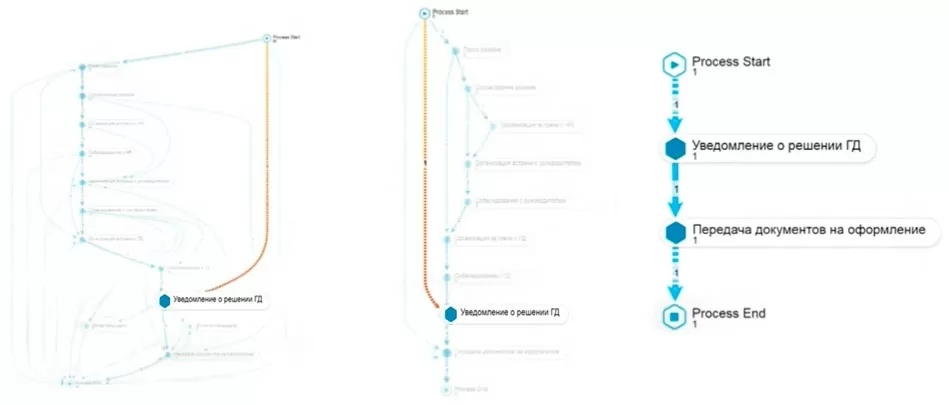
Еще пример, видим, что процесс начался с этапа «Уведомление о решении ГД», т.е. фактически кандидат принят в обход HR одним только решением ГД.
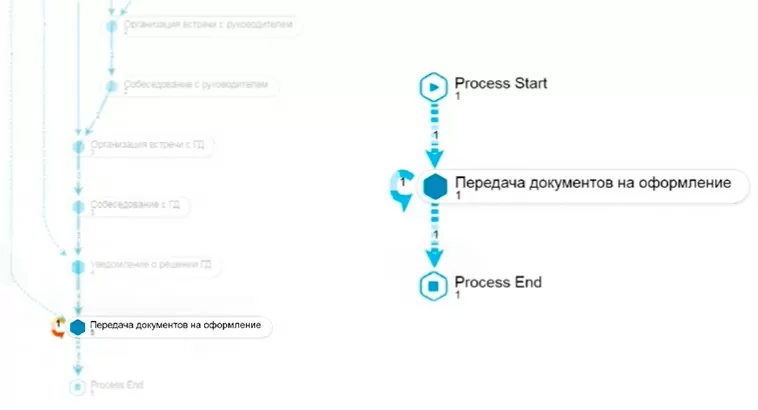
Еще одна попытка обойти процедуру – процесс начинается сразу с финального этапа «Прием документов на оформление».
Среди прочего, готовые инструменты с легкостью позволяют произвести оценку процесса с точки зрения производительности и временных затрат. Выделяем и анализируем те экземпляры процесса, выполнение которых длится намного дольше остальных, а также сверяем регламентные и фактические сроки исполнения процесса.
Итак, проанализировав модель восстановленного бизнес-процесса (ту самую «лапшу»), можно обнаружить: излишние циклы согласования, отмену ранее совершенных действий, «пинг-понг» исполнителей, задержки по времени выполнения функций, лишние действия в процессе, лишних или не эффективных исполнителей и главное исключительные ситуации в процессах, которые возникают из-за ошибок исполнителей и исправление которых требует серьезных ресурсов.