/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Про библиотекуPm4py, которая поддерживает современные алгоритмы бизнес-процессов в python, мы уже писали на страницах NewTechAudit.
В этой статье опишем еще один кейс, используя программный код.
Pm4py — это полностью открытая библиотека, предназначенная для использования как в научных, так и промышленных целях. Весь исходный код находится в репозитории github.
Плюсы библиотеки:
- Простота использования (для визуализации необходимо всего ~10 строк кода)
- Открытый исходный код
Минусы библиотеки:
- Отсутствие множества базовых функций необходимых для аудита процесса
- Ошибки в работе библиотеки
- Отсутствие примеров использования множества базовых функций в интернете
- Ограниченный функционал
- Сложность визуальной оценки (монохромность графа)
Для примера работы библиотеки были сформированы логи содержащие жизненный цикл сделок и написан код для визуализации процесса (Листинг 1).
data_dev = pd.read_excel('log.xlsx')
data_frame=pd.DataFrame()
data_frame['case:concept:name'] = data_dev['id']
data_frame['concept:name'] = data_dev['st']
data_frame['time:timestamp'] = data_dev['date']
data_frame.to_csv('data_frame.csv')
event_stream = factory.import_event_stream(os.path.join('data_frame.csv'))
event_log=conversion_factory.apply(event_stream)
heu_net = heuristics_miner.apply_heu(event_log, parameters = {"dependency_thresh" : 0, "and_measure_thresh":0, "dfg_pre_cleaning_noise_thresh":0 })os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
gviz=hn_vis_factory.apply(heu_net)
hn_vis_factory.view(gviz)В результате работы данного кода было получено изображение, представленное на рисунке 1.
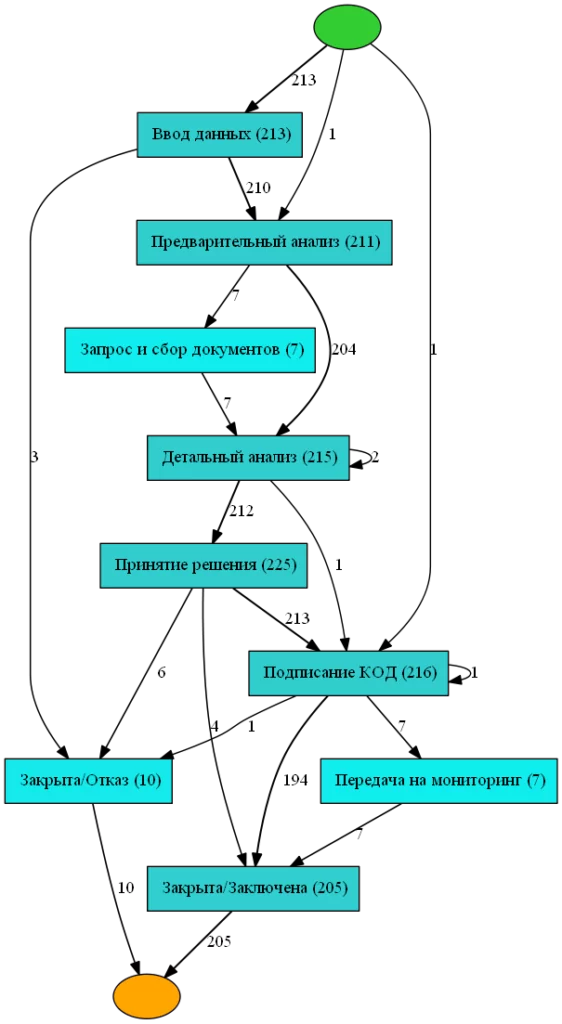
Представим, что у нас был бы не простой процесс, а очень запутанный (нечитабльный), как на рисунке 2.

Теперь видно, что есть несколько проблем:
А) Определение отклонений
Б) Нет среднего времени между двумя стадиями
В) Невозможно идентифицировать объекты между стадиями
Для решения этих проблем можно воспользоваться некоторыми функциями из других библиотек (graphviz, datetime, dateutil).
Первую часть кода оставляем с незначительными изменениями (приведение к формату даты, сортировка данных).
data_dev = pd.read_excel('log.xlsx')
data_frame=pd.DataFrame()
data_frame['case:concept:name'] = data_dev['id']
data_frame['concept:name'] = data_dev['st']
data_frame['time:timestamp'] = data_dev['date']
data_frame['id'] = data_frame['case:concept:name']
data_frame.drop(data_frame.columns.difference(['case:concept:name','concept:name','time:timestamp','id']),1, inplace=True)
data_frame["time:timestamp"]=pd.to_datetime(data_frame["time:timestamp"],format='%d.%m.%y %H:%M:%S')
data_frame=data_frame.sort_values(['case:concept:name','time:timestamp'])
#data_frame=data_frame.drop_duplicates()
data_frame=data_frame.reset_index(drop=True)
data_frame.to_csv('data_frame.csv')
event_stream = factory.import_event_stream(os.path.join('data_frame.csv'))
event_log=conversion_factory.apply(event_stream)
heu_net = heuristics_miner.apply_heu(event_log, parameters = {"dependency_thresh" : 0, "and_measure_thresh":0, "dfg_pre_cleaning_noise_thresh":0 })Далее необходимо будет создать в качестве подсказки список стадий и дополнить матрицу содержащую все стадии и количество объектов, матрицей объектов, которые библиотека решила исключить, по непонятным причинам.
ki=heu_net.freq_triples_matrix
ki2=heu_net.performance_matrix
ki3=heu_net.start_activities
ki4=heu_net.end_activities
for keys in ki.keys():
if keys in ki2.keys():
for keyst in ki.get(keys):
if keyst not in ki2.get(keys):
ki2.get(keys)[keyst]=ki.get(keys).get(keyst)
else:
for keyst in ki.get(keys):
ki2.get(keys)[keyst]=ki.get(keys).get(keyst)
podskazka=''
e=[]
e+=heu_net.performance_matrix.fromkeys(heu_net.nodes)
for i in range(0,len(e)):
podskazka+=str(i)+' - '+e[i]+'\n' Следующим шагом необходимо написать процедуру для визуализации процесса в виде графа, на котором можно будет указать процент от общего числа объектов, для того чтобы считать их отклонением от нормы, а также добавить время на граф и функцию для конвертирования времени в привычный формат.
def graph():
global ki2,ki3,ki4
f=Digraph('t', format='png')
for keys in ki2.keys():
for keyst in ki2.get(keys):
k1=0
k2=0
k3=0
k=True
for i in range (0,len(data_frame)-1):
c=0
c3=0
if data_frame['concept:name'][i].find(str(keys))>=0:
try:
c=parser.parse(data_frame['time:timestamp'][i])
except:
c=data_frame['time:timestamp'][i]
if data_frame['concept:name'][i+1].find(str(keyst))>=0 and c!=0 and data_frame['case:concept:name'][i]==data_frame['case:concept:name'][i+1]:
try:
c3=parser.parse(data_frame['time:timestamp'][i+1])-c
except:
c3=data_frame['time:timestamp'][i+1]-c
k1+=c3.total_seconds()
k2+=1
if k2==0:
k2=1
if ki2.get(keys).get(keyst)<=round(len(event_log)*0.02):# процент от общего числа case id, для выделения красным
clr='red'
#clr='black'
else:
clr='black'
f.edge(str(keys), str(keyst),str(ki2.get(keys).get(keyst))+' ('+str(convert(k1/k2))+')', color=clr)
for keys in ki3:
for key in keys:
if keys.get(key)<=round(len(event_log)*0.02):
clr='red'
#clr='#8fbc8f'
else:
clr='#8fbc8f'
f.edge('start', str(key),str(keys.get(key)), color=clr)
for keys in ki4:
for key in keys:
if keys.get(key)<=round(len(event_log)*0.02):
#clr='red'
clr='blue'
else:
clr='blue'
f.edge(str(key),'end',str(keys.get(key)), color=clr)
f.node('start',shape='diamond',color='#8fbc8f') #style='filled'
f.node('end',shape='square',color='blue')
f.save()
render('dot','png','t.gv')
def convert(sec):
st5=""
td=timedelta(seconds=sec, microseconds=sec-int(sec))
st1=int(td.days)
st2=int(td.seconds/3600)
st3=int((td.seconds/60)%60)
st4=int(td.seconds%60)
if st1>0:
st5+=str(st1)+'d '
if st2>0:
st5+=str(st2)+'h '
if st3>0:
st5+=str(st3)+'m '
if st4>0:
if st3>0:
st5+=str(st4)+'s'
else:
st5+='0m '+str(st4)+'s'
else:
if st1==0 and st2==0 and st3==0:
st5+='0s'
return st5В первой процедуре graph() происходит обход всех стадий и подсчёт общего времени в секундах между стадиями и количества объектов, также установлен порог в 0.02 от общего числа объектов для выделения стрелки красным цветом. После всех подсчетов происходит рисование картинки с помощью библиотеки graphviz. Вторая функция convert() получает секунды и конвертирует в удобный для чтения формат. Пример работы представлен на рисунке 3.
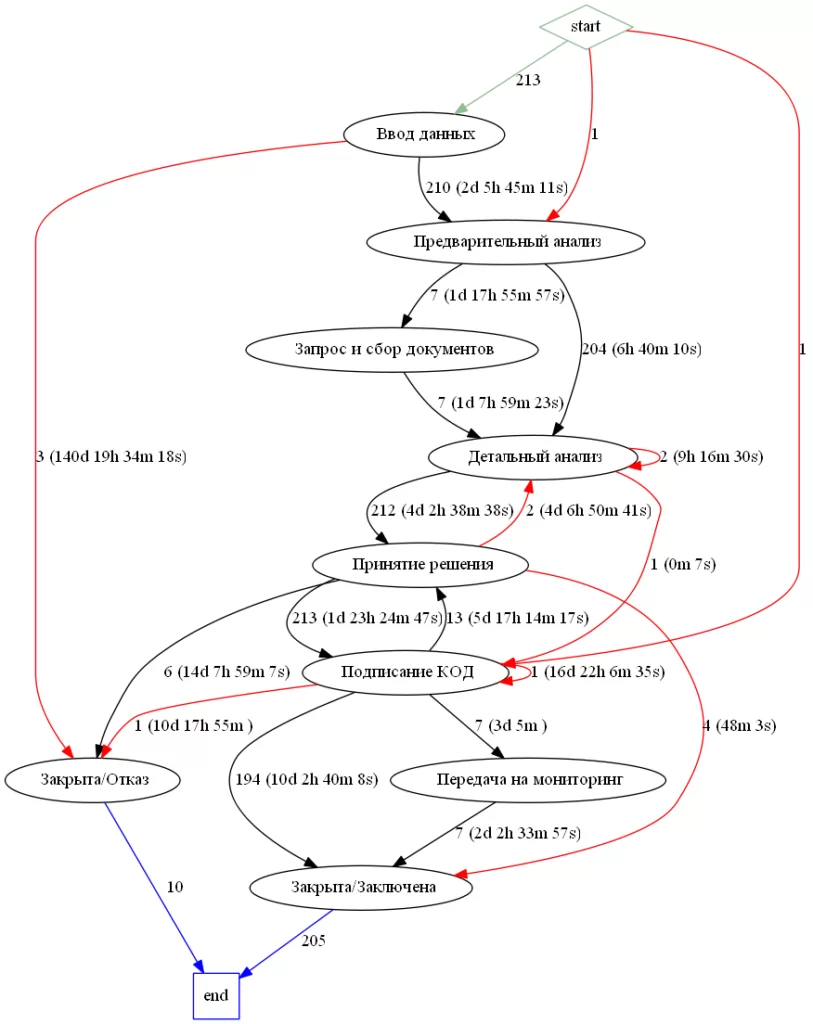
Как видно на рисунке, были добавлены новые стрелки, которых не было при визуализации стандартным методом, а также удалось добавить время на граф и подсветить пути где прошло минимальное количество объектов.
Следующим шагом необходимо реализовать функцию для идентификации объектов внутри каждого пути. Реализация данной функции заключалась в получении на вход двух стадий (номеров из подсказки), между которыми необходимо было идентифицировать объекты, и результатом её работы был файл, в котором были все объекты по данному пути процесса.
def exportres(o,p):
global event_log,heu_net,e
ti=[]
if o!='' and p!='':
a=e[int(o)]
b=e[int(p)]
for i in range(0,len(event_log)):
for j in range(0,len(event_log[i])-1):
if (event_log[i][j]['concept:name']==a) and (event_log[i][j+1]['concept:name']==b):
ti.append(event_log[i][j]['id'])
numpy.savetxt(a.replace('/', ' ')+' - '+b.replace('/', ' ')+'.txt',ti, fmt='%s')
else:
if o!='' and p=='':
a=e[int(o)]
for i in range(0,len(event_log)):
if (event_log[i][len(event_log[i])-1]['concept:name']==a):
ti.append(event_log[i][0]['id'])
numpy.savetxt(a.replace('/', ' ')+' - End.txt',ti, fmt='%s')
else:
if o=='' and p!='':
b=e[int(p)]
for i in range(0,len(event_log)):
if (event_log[i][0]['concept:name']==b):
ti.append(event_log[i][0]['id'])
numpy.savetxt('Start'+' - '+b.replace('/', ' ')+'.txt',ti, fmt='%s')