/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 25 мин.
Как прочитать файл Excel, если он напоминает монстра Франкенштейна? Как склеить множество таких файлов в единый датасет и обработать их, не потеряв ни одной ячейки? Это и многое другое, включая подробности разработки нового инструмента — найдёте в посте.
Сегодня я расскажу о нестандартном способе считывания файлов Excel с помощью Python, причем буду читать и файлы XLSB, и файлы XLSX. В работе пригодятся такие библиотеки PyPi, как recordclass, numba, pyarrow, tqdm и Pandas или Polars. Я предпочитаю использовать Polars, так как возможностей у него не меньше, а скорость и строгий подход к данным у него лучше.
В чём проблема?
Проблема, с которой я столкнулся:
- Есть большой набор файлов Excel (с расширением.xlsx), которые нужно объединить в один датафрейм, чтобы сопоставить записи из множества отчетов и записи в базе данных.
- В начале каждого файла есть отступ в несколько строк. В некоторых файлах он отличается на одну‑две строки (вне зависимости от названия и содержимого файла).
- Заголовки на листах Excel оформлены в многострочном виде, содержат разное количество столбцов. Ячейки в заголовках на некоторых строках объединены. В некоторых файлах заголовки содержат дополнительную строку и/или измененные названия столбцов (вне зависимости от названия и содержимого файла).
- В конце каждого файла есть «подвальчик» на неопределенное количество строк и столбцов.
- Столбцы дат в некоторых случаях состоят из ячеек разного типа — стиль «Текст» смешивается со стилем «Дата». Также и столбцы чисел имеют текстовые ячейки.
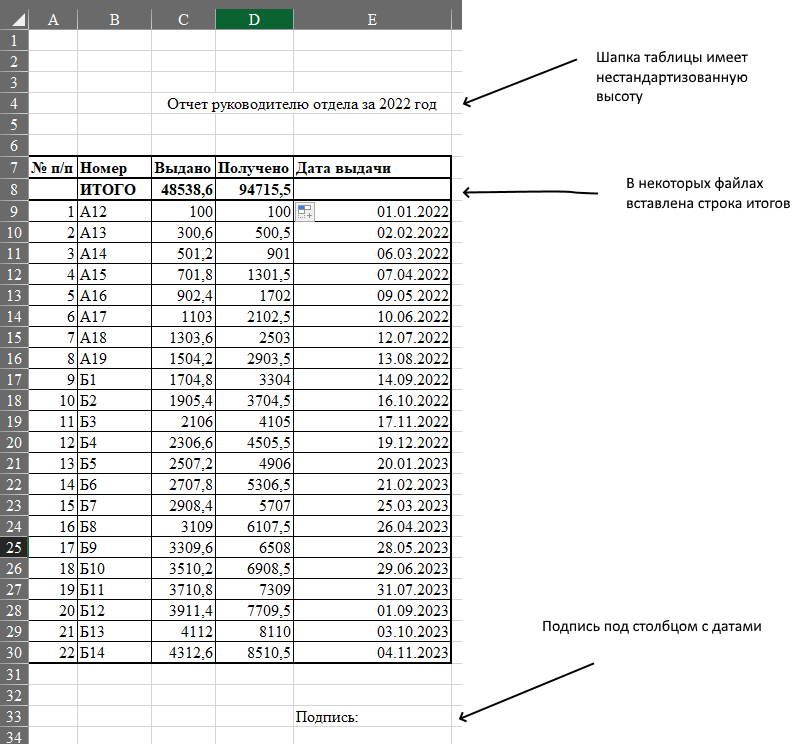
Отвлеченный пример ужасных исходных данных
Многие, наверное, сталкивались с подобными проблемами. Такие «рукописные» отчеты становятся головной болью для программистов, связанных с задачами их обработки, классификации или, например, заливки в базы данных.
Всё усложняется в разы, когда файл Excel был по какой‑то причине сохранен в формате XLSB или так называемой «двоичной книге Excel». Чтобы убедиться, что все данные считаны корректно, нужно иметь под рукой либо MS Excel, либо аналог, потому что ячейки в таких файлах хранятся в формате BIFF12, и без специального ПО прочитать содержимое файла не получится.
Для начала я решил рассмотреть имеющиеся инструменты, которые уже позволяют считывать файлы Excel, и попробовал их все в деле.
| Инструмент | Достоинства | Недостатки | XLSB | XLSX |
| PyXLSB | Умеренное потребление оперативной памяти | Не распознает даты автоматически | V | X |
| OpenPyXL | Считывает ячейки корректно | Большой перерасход оперативной памяти | X | V |
| XLSX2CSV | Считывает ячейки корректно | Требует тщательной настройки | X | V |
Как Pandas, так и Polars используют для считывания этих двух видов файлов только эти три движка. Когда я попытался приспособить их для считывания моих файлов – тех самых, ужасных в своей непредсказуемости – я столкнулся сразу с несколькими проблемами:
- почти невозможно заранее определить, где должен начинаться заголовок и сколько он займет строк;
- строки «подвала» таблицы Excel, где оставлены поля для подписи, приводили к тому, что весь столбец принимал строковый тип. Дополнительно, как оказалось, нет способа приспособиться к тому, что в одном столбце оказываются разные типы данных. Так, например, из некоторых столбцов исчезали даты из-за того, что были записаны в разном формате. Из некоторых, по той же причине, исчезали числа.
В плане сохранения данных лучше всех справился XLSX2CSV. Но его предварительно нужно тщательно настроить.
OpenPyXL, как оказалось, работает очень медленно по сравнению с конкурентом и тратит более чем в пять раз больше оперативной памяти. При этом зависимость явно была нелинейная: чем больше файл, тем соотношение используемых ресурсов было больше.
С трудом я прочитал все свои файлы, используя эти инструменты, и понял, чего не хватает мне в работе. Инструмента мечты, который мог бы:
- читать одинаково эффективно файлы XLSX и XLSB;
- тратить на это минимум ресурсов системы;
- корректно распознавать «временные» ячейки — дату, время, временной интервал;
- отсеивать лишние строки сверху и снизу таблицы.
Я принялся изучать стандарты Microsoft, посвященные форматам XLSX и XLSB, и попытался вникнуть в суть происходящего в коде их трех основных «читалок».
Оказалось, все их проблемы коренятся в изначально ненадежном подходе к чтению.
Что я имею ввиду:
- OpenPyXL обладает богатейшим функционалом для работы с файлам Excel и попросту не «заточен» на быстрое и эффективное чтение. Да, там есть режимы Read Only и Data Only, которые позволяют не так сильно загружать оперативную память, но в целом оптимизация его слабая. Кроме того, конвертация дат производится для каждой ячейки, что приводит к невероятным дополнительным затратам ресурсов.
- XLSC2CSV уходит в другую крайность. Он совершенно не заботится о том, что происходит в файле Excel, и считывает его «построчно», преобразуя в формат CSV. Такой подход позволяет гибко настроить чтение, но не позволяет предварительно анализировать строки до их преобразования в CSV. Опять же, конвертация дат производится для каждой ячейки отдельно. Под капотом этот движок использует потоковый сканер PyExpat, что делает его самым быстрым из трех, но далеко не самым удобным.
- PyXLSB стоит особняком. У него просто нет конкурентов среди имеющихся в открытом доступе инструментов. Не считая платных или условно‑платных проприетарных аналогов, он единственный инструмент, способный читать файлы XLSB. Но он вовсе не заботится о конвертации дат. Разработчики добавили в основной модуль специальную функцию конвертации, чтобы после считывания вы сами могли конвертировать нужные ячейки. Обратите внимание, речь идет опять же о ячейках!
И то, что не бросается в глаза. Как мы видим обычно файлы Excel? И что предполагает их формат? Верно. Данные в 90% случаев выглядят как ровные колонки (а не строки). В таблице бывают колонки с датами, колонки, в которых есть какие‑то уникальные значения, будь то строки или числа, и куча другой информации, разложенной не по строкам — по колонкам! Как жаль, что сам формат не рассчитан на чтение по колонкам! Или…
Прочитать столбец, а затем преобразовать его, используя многопоточность и глубокую оптимизацию — возможно. Правда, попутно придется считать и остальные колонки.
Всё очень просто: строки состоят из ячеек, и столбцы состоят из ячеек. Вопрос в том, как их складывать при чтении. Все три инструмента, как назло, считывают данные построчно, причем, это делается вовсе не с целью оптимизации! Что проще: сразу сложить ячейки по столбцам или сначала сложить их в строку, а затем уже разобрать её по столбцам? Кажется, ответ очевиден.
Предвижу возражения. Как потом работать с данными, разложенными по столбцам? Представлю, что необходимо отсортировать всю таблицу, используя несколько столбцов, или убрать несколько строк. Ничего сложного на самом деле! Здесь в дело вступает PyArrow.
PyArrow — это библиотека для работы с форматом данных Apache Arrow, оптимизированным для хранения и работы с данными «столбчатой» ориентации. То, что нужно! Кроме того, формат Apache Arrow с самого начала используется в Polars, что делает дальнейшую интеграцию инструмента практически бесшовной. Что интересно, Pandas в последнее время тоже активно предпринимает шаги по постепенному переходу к использованию Apache Arrow. Получается, если возможно реализовать инструмент, использующий в своей работе PyArrow, то можно легко конвертировать полученную таблицу в любой современный инструмент обработки данных, где уже буду производить и сортировку, и фильтрацию, и все необходимые вычисления.
План работы
Прикинув в уме, что необходимо сделать, я записал общий план чтения файла в таблицу для обоих форматов:
- Считываю имена листов и открываю нужный по его имени или номеру.
- Считываю «измерения» листа – сколько он занимает строк и столбцов.
- Начинаю считывать ячейки.
- Отправляю полученные ячейки в столбцы.
- По завершении чтения анализирую столбцы, привожу их к единому формату.
- Составляю заголовки из верхних ячеек столбца.
- Составляю таблицу из готовых столбцов и их заголовков.
Второй шаг необходим для дополнительных этапов обработки, которые объединены под общими пунктами. Допустим, после реализации «ядра» читалки, можно добавлять условия считывания. Например, сколько строк пропустить в начале (это число не должно быть больше общего числа строк). Или даже задать номера нужных столбцов (они не должны быть меньше 0 и больше номера последнего столбца).
Оставалось разобраться, как всё это хранится внутри файлов книг XLSX и XLSB. Нужно иметь ввиду, что оба формата на самом деле являются ZIP архивами со строгой внутренней структурой.
С XLSX всё оказалось просто: внутри он состоит из файлов XML, которые легко и быстро считываются с помощью PyExpat. В сущности, я мог легко сохранять небольшие файлы XLSX, распаковывать их и изучать, как хранятся данные в ячейках, где найти имя и размеры листа и так далее.
С XLSB всё было гораздо сложнее. Файлы внутри имеют, по большей части, расширение .bin и содержат внутри двоичные данные в формате BIFF12. Этот формат Microsoft разработала специально, чтобы данные могли быть уложены в файл максимально компактно и при этом могли быть считаны максимально быстро. Стандарт [MS‑XLSB] занимает порядка 1000 страниц (страница для скачивания PDF) и описывает все возможности этого формата. На самом деле важность для нового инструмента имеют от силы 25 страниц этого документа. Те, на страницах которых изложены правила записи ячеек и правила записи метаданных листа (опять же, имени и размера). Я, конечно, оказался далеко не прав. Нужной информации по итогу оказалось намного больше.
Ознакомившись со стандартом, я понял, в чем именно проблема с датами у PyXLSB.
Как оказалось, все «временные» типы данных в Excel представлены в двух вариантах:
- в виде строк (у таких строк должен стоять специальный стиль);
- в виде чисел с плавающей точкой (этот вид наиболее распространен).
Числа указывают количество дней с 1900 года (причем, для обратной совместимости с одним старым форматом, 1900 год специально ошибочно считается високосным, и имеет лишний день 29 февраля). Время и временной интервал представляют собой числа в диапазоне от 0 до 1 и обозначают долю дня. Числа, обозначающие «временные» типы, имеют специальный стиль, который позволяет отличить их от обычных чисел.
OpenPyXL и XLSX2CSV «знают» об этом. Каждое такое число они преобразовывают по‑своему эффективно. Казалось бы. На самом деле, если использовать PyArrow, можно сначала упаковать числа в колонку, а затем произвести необходимые вычисления сразу над всем столбцом, используя хорошо оптимизированный многопоточный код, написанный на языке C. К этому я пришел не сразу и не тем путем, каким хотел бы. Но я реализовал эту механику, и она работает практически безупречно.
PyXLSB вообще не читает файл стилей и «не знает», какие числа представляют собой даты. Именно поэтому столбцы порой выглядят совсем не так, как должны бы.
Другой проблемой трех «читалок» Excel стало то, что они считывают пустые ячейки. Да, это совсем пустые ячейки, и приводятся к типу None. Но сколько занимает в памяти один объект None? Шестнадцать байт! Шестнадцать байт никому не нужной «пустоты» на каждую пустую ячейку. Представим себе огромный лист, на котором среди полных и красивых столбцов затесался один полупустой. А он будет отъедать ненамного меньше оперативной памяти! Такая трата ресурсов пришлась мне совсем не по душе, и я быстро придумал, как обойтись вообще без пустых ячеек. Благо, PyArrow позволяет это легко реализовать.
Особенность формата Apache Arrow для всех типов данных фиксированной величины состоит в том, что пустые значения хранятся в виде битовой маски отдельно. Так, например, столбец 32-битных беззнаковых чисел представляет собой два массива байт. Один массив представляет собой битовую маску пустых значений (по одному байту на восемь элементов массива), а второй массив хранит только непустые значения. Получается, если бы данные хранились в виде объектов None, то разница в используемом дисковом пространстве и в потреблении оперативной памяти составляла бы 128 раз на одну пустую ячейку!
В Apache Arrow столбец из десяти тысяч чисел и десяти тысяч пустых ячеек будет занимать в оперативной памяти примерно столько же, сколько и столбец из десяти тысяч чисел, чего не скажешь о «классическом» хранении пустых значений в виде элементов None. В этом случае тот же столбец будет занимать едва ли не больше места, чем если бы в нем были одни только числа!
Немного о XLSB и формате BIFF12
Определившись с планом и внутренним форматом хранения данных, я погрузился в изучение формата BIFF12 и его применения в XLSB. Формат XLSX был сравнительно легок, прост в изучении и интуитивно понятен. А вот с BIFF12 всё оказалось намного сложнее.
Начну с того, как хранятся числа в XLSB. В этом формате они представлены в двух вариантах: RkNumber и Xnum. С числами Xnum всё было совершенно понятно. Это были просто 64-битные числа с плавающей точкой, закодированные в little‑endian формате, согласно открытому стандарту IEEE 754. Тот же стандарт использует и Python, поэтому декодирование этих чисел не составило труда.
RkNumber же, напротив, оказался серьезной головной болью. Этот формат был специально разработан для XLSB с целью сократить необходимое для хранения числа дисковое пространство. Именно в виде RkNumber хранятся «временные» типы и большая часть обычных чисел.

Описание формата RkNumber в документации
В зависимости от значения первого бита число после считывания должно (или не должно) быть разделено на 100. В зависимости от значения второго бита число представляет собой знаковое целое либо число с плавающей точкой.
При этом, чтобы правильно считать число из RkNumber, необходимо:
- Считать бит «умноженности на 100».
- Считать бит «типа числа».
- Присвоить первым двум битам значение «0».
- В зависимости от типа, либо дополню число четырьмя нулевыми байтами (когда это число с плавающей точкой), либо сдвигаю на два бита.
- Декодирую получившийся массив из байтового представления в числовой.
- Если бит «умноженности на 100» равен «1», нужно разделить результат на 100.
Звучит немного запутанно, но в таком хранении чисел есть глубокий смысл. Преимущества состоят в том, что числа с плавающей точкой могут быть сохранены в 4 байтах с незначительной потерей точности (сохраняется знак, порядок и 18 старших бит мантиссы), что хорошо подходит для хранения «временных» типов данных. Кроме того, этот формат позволяет с идеальной точностью хранить «процентные» значения — когда требуется сохранить только два знака после запятой, число умножается на 100 и сохраняется в виде знакового целого. Это позволяет хранить довольно большие числа (от -5 368 709.12 до 5 368 709.12 включительно), что может быть довольно удобно в некоторых случаях.
Применяя вышеописанные шесть шагов к каждой считанной ячейке, используя Python, PyXLSB работает гораздо медленнее, чем если сначала записать все ячейки в «сыром» виде в столбец PyArrow, а затем преобразовать его целиком, используя хорошо оптимизированный код на языке C.
Немного о строках в XLSX и XLSB
Как хранятся строки в файлах MS Excel? Как с ними работают уже имеющиеся инструменты?
Строки в обоих форматах — XLSX и XLSB — хранятся, как правило, в виде числа, являющегося порядковым номером строки в файле xl/sharedStrings. Это сделано для того, чтобы избежать дублирования строк. Но именно строки, как правило, являются наиболее «тяжелыми» элементами листа и порой могут достигать огромных размеров. К примеру, строки в файлах XLSB могут иметь размер вплоть до 4 294 967 294 символов.
Итак, что предпринимают OpenPyXL, XLSX2CSV и PyXLSB, чтобы приспособиться к такому формату хранения строк?
Во‑первых, они считывают полностью файл xl/sharedStrings, декодируют каждую из них и сохраняют в виде списка (list).
Затем, считывая ячейку строки, они подменяют для каждой ячейки числовое значение на значение соответствующей ему строки из файла. Это означает, что для каждой ячейки производится:
- Декодирование байтов в число (для BIFF12) либо еще более медленное интерпретирование строки в число (для XLSX).
- Взятие строки по индексу, по полученному числу.
Конечно, подход с PyArrow будет гораздо проще. Для BIFF12 буду записывать в PyArrow сразу байтовое представление (внутренний формат чисел в PyArrow, в байтовом представлении, ничем не отличается от формата BIFF12). Далее применю операцию взятия по индексу для считанных из файла xl/sharedStrings строк (функцией pyarrow.Array.take). Это позволит, во‑первых, полностью устранить затраты на декодирование ячеек, а во‑вторых, преобразовать в строки сразу весь полученный столбец примерно за то же время, которое уходит в традиционном варианте на преобразование десяти ячеек.
Для XLSX появляется промежуточный этап преобразования строковых чисел в числовой тип. Но так как этот этап производится с помощью PyArrow для всего столбца сразу, времени на это уходит гораздо меньше, чем если преобразовывать ячейки по‑отдельности.
Собственно, чтение
Освоившись с форматом BIFF12, научившись считывать ячейки из листа XLSB, имена листов и их размеры из файла книги, я принялся экспериментировать с реализацией «ридера». Я назвал его «RXLS», от сокращения «Read XLS(X/B)». В общем, RXLS должен был уметь делать следующее:
- пропускать строки сверху (если необходимо);
- пропускать ненужные столбцы (для экономии оперативной памяти);
- считывать корректно даты, числа и строки;
- находить первую строку заголовка по регулярному выражению, соответствующему значению одной из ее ячеек;
- считывать многострочный заголовок;
- использовать один из столбцов в качестве «индекса» (далее будет пояснение);
- считывать только определенное число строк.
Каждая ячейка, что в XLSX, что в XLSB, хранит свой стиль, определяющий, в том числе, и формат даты, в виде числа. Это число — порядковый номер стиля ячейки из файла xl/styles. Для корректного считывания дат мне пришлось потрудиться над правильным считыванием этого файла. В дальнейшем я решил включить информацию о стиле в саму ячейку в уже переработанном виде. То есть ячейка после считывания содержит в себе информацию о том, как она должна быть интерпретирована (как есть или в виде «временного» типа — временной отметки, даты, времени или временного интервала).
Чтение осуществляется следующим образом (для краткости я назвал кусочек столбца Excel, в котором все ячейки имеют одинаковый формат и представление, чанком):
- Считывается список листов, чтобы определить, какой лист требуется читать.
- Считывается файл xl/sharedStrings, сохраняется в столбец PyArrow.
- Создается объект таблицы. Таблица хранит словарь номеров и объектов столбцов и содержит в себе функции по работе с коллекцией столбцов.
- Начинается чтение ячеек из выбранного листа. Для каждой ячейки проверяется наличие столбца с нужным номером в таблице, и, если его нет, он создается.
- Создается пустой объект столбца. Он хранит в себе следующую информацию:
- список преобразованных чанков столбца (готовые к использованию фрагменты, имеющие один тип и репрезентацию);
- текущий чанк — список, в который попадают значения новых ячеек перед преобразованием в формат Apache Arrow;
- тип и репрезентация текущего чанка;
- номер первой строки и строки последней записанной ячейки;
- ссылку на массив строк, считанных из xl/sharedStrings;
- порог округления для определения целых чисел;
- форматы временных типов для строковых значений, содержащихся в столбце с датами;
- флаг, указывающий программе, как поступать с числами, находящимися в одном столбце с «временными» ячейками – интерпретировать ли и их в качестве «временных», или нет;
- количество пустых ячеек, которые необходимо добавить перед текущим чанком.
- Проверяется номер строки, тип и репрезентация поступившей ячейки. Если строка отличается от предыдущей ровно на 1, тип и репрезентация не изменились, значение ячейки, как есть, добавляется к текущему чанку.
- Если одно из этих трех значений изменено, текущий чанк обрабатывается в соответствии с его типом и репрезентацией и добавляется к списку преобразованных чанков, и начинается новый чанк. При этом, если есть разрыв в номерах строк, количество необходимых пустых ячеек запоминается. На этапе обработки чанка, по завершении преобразований, к началу чанка добавляются пустые значения.
Объект столбца имеет следующие функции, позволяющие легко манипулировать данными внутри:
- Защищенная функция _iter_raw, которая позволяет пройти по полученному списку чанков. Чанки могут иметь разный тип, поэтому не получится просто склеить их в целый столбец. К примеру, если в столбце есть заголовок, он гарантированно имеет строковый тип и попадет в отдельный чанк. А другие ячейки в столбце могут быть и строками, и числами, и датами, и т. д. и попадут в чанки других типов.
- Защищенная функция _iter_idx, которая позволяет пройти по полученному списку чанков, используя в качестве фильтра массив булевых значений (pyarrow.BooleanArray). Некоторые чанки могут быть полностью пропущены, если фильтр принимает значение False на всем их протяжении.
- Функция to_utf8, которая позволяет преобразовать определенный диапазон ячеек в строковый тип. Эта функция специально разработана для «умного» нахождения заголовка таблицы.
- Функция to_arrow, которая используется для преобразования определенного диапазона ячеек в цельный столбец PyArrow. При этом, если чанки имеют один тип, они будут просто склеены, а если в наличии два и более различных типов чанков, будут применены соответствующие эвристики:
- если столбец смешивает в себе строки и «временные» типы, и объект столбца содержит список возможных форматов распознавания «временных» строк, то будет предпринята попытка интерпретации строк в тот же «временной» тип;
- если столбец смешивает в себе строки и числа, то будет предпринята попытка интерпретации строк в числа;
- если столбец смешивает в себе «булевые» значения и числа, то булевые значения будут преобразованы в числа (1.0 для TRUE и 0.0 для FALSE);
- если столбец смешивает в себе чанки более двух типов, или попытка интерпретации в одном из вариантов выше провалилась, то весь столбец будет приведен к строковому представлению.
В сущности, эти три функции позволяют реализовать все механики, необходимые для реализации RXLS. Так, к примеру, чтобы найти первую строку заголовка, объект таблицы применяет к столбцам поочередно следующую последовательность шагов:
- Отступает нужное число строк (если пользователем указано, что несколько строк нужно отступить).
- Применяя функцию to_utf8 преобразует верхние 30 ячеек столбца в строки (длина преобразования может быть задана пользователем).
- Применяет к ним функцию pyarrow.compute.match_substring_regex, которая находит (или не находит) все подходящие под регулярное выражение ячейки.
- Если найдена хотя бы одна такая ячейка, возвращает номер строки для нее.
- Если ячейки не найдены, переходит к следующему столбцу.
- Если ни в одном столбце не нашлось подходящей ячейки, выдает ошибку поиска.
Затем, когда первая строка заголовка найдена, объект таблицы преобразовывает нужное количество ячеек сверху каждого столбца в строки и применяет к ним специальные эвристики для получения правильного многострочного заголовка. Или оставляет как есть, если заголовок не многострочный.
Имея на руках набор заголовков, хотя столбцы ещё не готовы к работе, можно применять фильтрацию к заголовкам на основании регулярного выражения или числового индекса. Это позволит выбрать один или несколько столбцов таблицы в качестве индекса всей таблицы.
Что я имею ввиду под индексом. Индекс таблицы в данном случае означает некоторый набор столбцов, которые не пусты для каждой строки таблицы. То есть, имея в наличии имя или номер такого столбца (или нескольких столбцов), можно пропустить не только пустые строки в таблице и устранить разрывы в данных, но и убрать лишние строки в «подвале» таблицы.
Обратите внимание, что так как чанки с лишними ячейками будут полностью проигнорированы, их тип данных никак не повлияет на тип данных всего столбца, что было огромной проблемой для всех трех уже имеющихся инструментов. Так, например, если в «подвале» таблицы некая строка оказалась в столбце с датами, в лучшем случае весь столбец принимает в них строковый тип. Кроме того, в RXLS чанки, которые после фильтрации содержат только пустые ячейки, приводятся к типу pyarrow.null на тот случай, если их тип данных может привести к некорректному распознаванию типа столбца.
Далее объект таблицы преобразовывает нужное количество строк под заголовком в правильные столбцы PyArrow и формирует полноценную таблицу, уже пригодную для конвертации в Pandas и Polars.
Тонкости реализации и оптимизации
Подготовив всю инфраструктуру, готовую принимать в себя считанные ячейки, я занялся разработкой парсеров для этих ячеек.
Парсер для файлов XLSX получился очень простым. Я использовал подход, схожий с XLSX2CSV: считывал лист с помощью PyExpat и обрабатывал XML теги потоком. Это на данный момент самый быстрый и наименее требовательный к ресурсам способ обработки XML файлов. Пусть PyExpat и считается небезопасным, поскольку не заботится о внутренней иерархии XML, но так как файлы XLSX являются строго стандартизированными по внутренней иерархии, этот минус «отпадает». Другой «минус» этого подхода в том, что открывающий тег, текст между тегами и закрывающий тег обрабатываются в отдельных функциях, отчего возникают некоторые сложности в их взаимодействии. Но, имея некоторый опыт по работе с PyExpat, я довольно быстро решил эту проблему.
Парсер для файлов XLSB получился ещё более простым. Зная, какие виды записей BIFF12 нужны, я создал функцию, которая считывает только их. Достаточно указать ей идентификаторы этих записей, и она будет игнорировать все остальные. Далее, на основе парсера BIFF12, я создал функцию для чтения файлов «xl/styles.bin» и xl/sharedStrings.bin, а затем реализовал и парсер для листов Excel. Парсер принимает в качестве аргументов словарь: {номер стиля ячейки: номер «временного» типа данных} и выдает на выходе итератор по ячейкам листа.
def scan_biff(io: IO[bytes], only: set[int] | None = None) -> Iterator[record]:
try:
while True:
# read record id
id = io.read(1)[0]
if id & 0x80:
id |= io.read(1)[0] << 8
# read record size
sz = io.read(1)[0]
if sz & 0x80:
sz = sz ^ 0x80 | (io.read(1)[0] << 7)
if sz & 0x4000:
sz = sz ^ 0x4000 | (io.read(1)[0] << 14)
if sz & 0x200000:
sz = sz ^ 0x200000 | (io.read(1)[0] << 21)
# read record data if exists and id in x_only set, skip data otherwise
if not only or id in only:
if sz:
data = io.read(sz)
if len(data) != sz:
break
yield record(id, data)
else:
yield record(id, b"")
elif sz:
io.seek(sz, os.SEEK_CUR)
except IndexError: # , GeneratorExit, StopIteration
passНекоторые фрагменты кода, как оказалось, можно было дополнительно ускорить с помощью Numba — известной библиотеки, позволяющей компилировать код Python в код на языке C, и тем самым, ускорять его выполнение. Конечно, пришлось вынести эту библиотеку в «опциональные» зависимости, чтобы те, кто не хочет или не может ее установить, все равно могли использовать RXLS.
Так, например, удалось ускорить функцию получения номера столбца по его буквенному обозначению в XLSX. Прирост был примерно десятикратный. Также удалось ускорить функцию разбора «куска» BIFF12 на содержащиеся в нем записи (примерно в три раза).
В опциональные зависимости попала сама библиотека Polars. Это было сделано только для тех случаев, когда строковые значения в столбцах «временных» типов содержат доли секунды или имеют специфический формат (например, с указанием часового пояса, или времени суток по 12-часовым форматам — АМ/РМ). Дело в том, что PyArrow использует собственную реализацию функции strptime, основанную на стандарте языка C. В этой функции не поддерживаются времена суток и доли секунды, что может привести к неправильному считыванию столбцов. Polars же, как библиотека, основанная на формате Apache Arrow, способна считывать объекты pyarrow без копирования и какой‑либо дополнительной обработки, а объекты Polars можно также легко конвертировать обратно в PyArrow. Polars написана на языке Rust и использует функцию strptime из крэйта «chrono», поддерживающую богатейший набор возможных форматов даты/времени.
Как использовать RXLS
В настоящее время инструкция по применению, оставленная мной на GitHub, как и сам код, подлежит обновлению. Так что здесь я кратко опишу, как я использовал новый RXLS в своей работе.
Итак, начнем по порядку. Чтобы считать файл, необходимо импортировать модуль RXLS и вызвать функцию xl_scan:
from rxls.reader.reader import xl_scan
table = xl_scan('file.xlsx', head=True)Параметр head здесь указывает, что таблица имеет заголовок (если параметр выставлен как False, все столбцы получат название «Unnamed. {№ столбца}». Также здесь можно вместо булевого значения задать числовое:
table = xl_scan('file.xlsx', head=4)Это будет означать, что заголовок не только существует, но и имеет высоту в 4 строки.
Или можно вручную прописать имена столбцов:
xl_scan('file.xlsx', head=['№ п/п', 'ИНН', 'Номер договора'])Если неизвестно, где находится заголовок, то можно найти его с помощью двух параметров:
xl_scan('file.xlsx', head=4, lookup_size=30, lookup_head='^№ п/п$')Здесь lookup_size означает, что буду искать заголовок по 30 верхним строкам файла. Аргумент lookup_head может быть регулярным выражением или числом, означающим номер столбца. В первом случае, первой строкой заголовка таблицы будет та, которая содержит текст, подходящий под регулярное выражение. Во втором – первой строкой заголовка будет та, в которой столбец с указанным номером содержит первое непустое значение.
Если нужно отфильтровать строки таблицы так, чтобы остались только нужные (например, те, которые содержат ИНН или номер договора, или другую ключевую информацию), можно легко отфильтровать их с помощью параметра idx_filters:
xl_scan('file.xlsx', head=4, lookup_size=30, lookup_head='^№ п/п$', idx_filters='^ИНН.*$')С помощью регулярного выражения можно выбрать один или несколько столбцов, хотя бы один из которых содержит непустую ячейку для нужных строк. Также можно напрямую передать список столбцов:
xl_scan('file.xlsx', head=4, lookup_size=30, lookup_head='^№ п/п$', idx_filters=['ИНН', 'Номер договора'])Можно пропустить некоторые столбцы, используя их номера (начинающиеся с 0):
xl_scan('file.xlsx', head=4, lookup_size=30, lookup_head='^№ п/п$', idx_filters=['ИНН', 'Номер договора'], skip_cols=[5, 7])Нужно быть осторожным, чтобы не пропустить столбцы, которые указали в idx_filters. Потому что этап отбрасывания ненужных столбцов происходит на этапе чтения файла, а этап фильтрации строк относится к постобработке, что означает, что эти столбцы попросту не будут найдены в получившейся таблице.
В случаях, когда необходимо пропустить несколько строк до заголовка, можно указать нужное количество в параметре skip_rows. Если нужно пропустить одну или несколько строк после заголовка, то используйте параметр drop_rows. Есть параметр take_rows, который может пригодиться для чтения определенного числа строк (не больше этого параметра). Эти три аргумента могут пригодиться, когда вы точно знаете пропорции шапки и/или самой таблицы. Всё же поиск заголовка с помощью lookup_head более требовательная к ресурсам операция, чем простой пропуск столбцов.
Так как в MS Excel все числа на самом деле представляют собой числа с плавающей точкой (меняется только формат отображения). Я добавил параметр int_threshold, который проверяет, является ли число, округленное до определенного знака после запятой, равным тому же числу, но с отброшенной дробной частью. Если все числа в столбце подходят под это условие, то столбец будет сконвертирован в целочисленный тип. Вычисления такого рода производятся сразу на всём столбце и могут быть дополнительно ускорены с помощью Numba.
Для столбцов, имеющих смешанный формат данных (например, даты и строки или даты и числа с плавающей точкой), возможно приведение к общему типу. Такое поведение включено по умолчанию с помощью аргумента temporal_data. Числа и строки теоретически могут быть преобразованы в дату или время, но если такое преобразование невозможно для некоторых участков столбца, то весь столбец конвертируется в строковый тип данных. Дополнительные форматы даты или времени для проверки строковых ячеек можно задать с помощью аргумента temporal_fmts.
Столбцы, содержащие дату или время, можно дополнительно округлить до секунд, минут, часов или дней, с помощью аргумента temporal_unit. Такая возможность была добавлена в связи с некоторой потерей точности, в случаях, когда временная отметка в MS Excel была сохранена в числовом формате RkNumber (ошибка округления таких чисел приводит к появлению лишних миллисекунд).
Если столбец полностью строковый, но содержит только числовые значения, функция xl_scan может определить такой столбец при включении флага detect_string. Если этот аргумент установлен в «True», то для каждого строкового столбца будет предпринята попытка конвертации в числовой тип. Если такая попытка провалится, то столбец останется строковым. Если удастся, то будет также выполнена проверка на целочисленность, согласно аргументу int_threshold и, если столбец содержит только целые числа, он будет преобразован в целочисленный.
Аргументы lookup_head и idx_filters позволили мне разом избавиться и от шапки файла, имеющей рандомную высоту, и от подвала, который начинался и заканчивался также случайно. Кроме того, я смог отфильтровать и те лишние строки с «итогами», которые кто‑то вставил и забыл между заголовком и данными — столбец с ключевыми данными был пуст.
Получившуюся таблицу я преобразовал в датафрейм Polars (с помощью polars.from_arrow — без копирования данных), выбрал из него нужные столбцы с помощью регулярных выражений. Весь процесс я завернул в цикл по файлам, и таблицы считались настолько удачно, что даже распознанные типы данных в столбцах совпали. Соединить датафреймы с помощью polars.concat было уже самым простым этапом, после которого данные были уже полностью готовы к работе!
Подведение итогов
Полученный в ходе экспериментов модуль я протестировал на разнообразных входных данных и сравнил его скорость и потребление оперативной памяти с тремя другими инструментами. Как оказалось, в плане скорости RXLS ненамного уступает устоявшимся инструментам, а в плане потребления оперативной памяти – сравнима с лучшим из них (которым оказался XLSX2CSV).
Завершив предварительный этап разработки, я оценил сложность и скорость выполнения исходной задачи – с помощью традиционных инструментов и с помощью моего инструмента RXLS. Результаты я занес в табличку:
| Инструмент | Место по скорости | Место по потреблению ОП | Место по простоте в применении | Примечание |
| Polars+XLSX2CSV | 1 | 3 | 3 | Сложности в настройке. Невозможно считать все файлы в цикле: каждый файл требуется считывать по-отдельности с подбором наилучшей конфигурации |
| Polars+OpenPyXL | 3 | 1 | 2 | Данные в столбцах исчезали при совмещении в одном столбце «строковых» и «числовых» дат Excel (пропадали либо те, либо другие, непредсказуемо). Потребление оперативной памяти в десятки раз превосходит XLSX2CSV и RXLS. Работает гораздо медленнее конкурентов (примерно в 5 раз) |
| Polars+PyXLSB | 1 | 1 | 2 | Необходимость дополнительно конвертировать даты повышает сложность использования. |
| Polars+RXLS | 2 | 2 | 1 | Ненамного уступая по скорости XLSX2CSV и PyXLSB, RXLS корректно и автоматически распознает даты и числовые столбцы. При этом потребление памяти минимальное (совсем ненамного больше, чем у XLSX2CSV). |
Касательно исчезновения данных при считывании файлов Excel с помощью OpenPyXL — это и есть основная причина для такого названия поста. Это неочевидная проблема. С ней легко можно столкнуться и не заметить, поскольку уже сложилось доверие к давно существующим инструментам, без перепроверки и сравнения с исходником вы можете остаться с некорректно сформированным датафреймом. Эта проблема касается, в первую очередь, Pandas, поскольку там OpenPyXL считается самым передовым инструментом для чтения файлов Excel, тогда как пользователи Polars до недавнего времени имели дело только с XLSX2CSV.
Самый простой пример такого исчезновения данных можно обнаружить, если попытаетесь повторить примеры из моего файла с бенчмарком на GitHub. Для этого бенчмарка, я скачал данные OurWorldInData по статистике COVID-19 в формате CSV (ссылка на скачивание есть в файле бенчмарка), импортировал их в MS Excel и сохранил, без каких‑либо изменений в форматы XLSX и XLSB.
Кто знает, может, если поколдовать над параметрами, все столбцы будут считаны корректно. Но в моем случае простое выполнение polars.read_excel(path, engine=»openpyxl») приводило к исчезновению данных из столбца «median_age» и к огромному перерасходу оперативной памяти. Откуда неискушенному человеку знать, исчезнут данные или нет? Проблема возникает, если в исходных данных большие участки столбца имеют различные типы данных. Например, 100 000 ячеек — даты и еще 100 000 — какие‑то числа или строки. Polars в сочетании с OpenPyXL молчаливо съест из них 100 000 ячеек. Но я не уверен, что это будут за ячейки, хоть я и знатно покопался в исходном коде обеих библиотек, чтобы это выяснить. Никакой ошибки или предупреждения не будет. Вы просто теряете кусок данных и всё!
Как возникает перерасход оперативной памяти при использовании Polars в сочетании с OpenPyXL? OpenPyXL, при определенных параметрах открытия книги Excel, способен считывать файл «построчно», без какой‑либо ощутимой нагрузки на ОЗУ. Тем не менее разработчики Polars по какой‑то причине не используют данный вариант считывания, предпочитая полностью загрузить весь файл в оперативную память, а затем преобразовать в датафрейм. Как объяснил один из разработчиков, это необходимо для корректной работы некоторых «фич» Polars, которые иначе не работают, так что исправлять такое поведение пока что и не планируется. Вспомним, что я говорил про то, сколько памяти съедает одно единственное пустое значение (None). Числа и строки съедают намного больше, так что один файл XLSX весом 40 МБ запросто может потребить один‑два гигабайта ОЗУ.
Стоит обратить внимание, что в уровень простоты в использовании вошла и постобработка. Так, например, для PyXLSB я учел необходимость дополнительной конвертации временных типов. С точки зрения постобработки, RXLS на голову выше конкурентов за счет возможности быстро и эффективно находить первую строку заголовка и формировать многострочный заголовок из структуры с объединенными ячейками и корректно считывать временные типы ячеек.
Кроме того, возможность предварительно отфильтровать все столбцы по содержимому одного или нескольких, до преобразования столбцов в общий тип данных, позволяет сохранить тип данных для «проблемных» столбцов, в которых помимо данных содержатся и ненужные строки из «подвальчика» листа Excel. Ни один другой инструмент не позволяет заранее отсеять строки из конца файла, из‑за чего на этапе постобработки возникает необходимость дополнительной фильтрации лишних строк и «ручного» преобразования столбцов в нужные типы данных.
В ходе разработки я столкнулся со множеством проблем и неочевидных нюансов, а также бросил вызов множеству задач по оптимизации, что позволило мне поднять общий уровень понимания языка Python и использовать полученные знания в решении других задач.
Получившийся инструмент, возможно, не скоро получит завершенную версию для общего использования, но исходный код предварительной версии RXLS, а также подробный бенчмарк для сравнения RXLS с его аналогами можно найти на GitHub. Инструмент еще подлежит совершенствованию, и я уверен, он уже скоро окажется быстрее всех своих конкурентов.
В ходе разработки модуля я связался с разработчиками Polars и даже создал Issue на GitHub, посвященную чтению XLSB файлов. После изучения бенчмарков в репозитории RXLS, разработчики Polars приняли решение включить поддержку PyXLSB в своем инструменте. Так что, хоть RXLS пока и сыроват, и уступает конкурентам в скорости, его разработка оставила свой след в истории одного из самых известных инструментов обработки данных. Более того, сообщество Polars пообещали изучить возможность добавления поддержки RXLS после того, как мой инструмент достигнет версии релиза, пройдет тестирование, и я создам для него страничку на PyPi.org.
Надеюсь, моя работа подаст пример всем, чтобы сложные задачи, с которыми приходится сталкиваться порой, становились проще за счет плодов личного или командного исследования вопросов их оптимизации.