/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Очень часто аналитики сталкиваются с неструктурированными файлами, которые необходимо обработать и проанализировать. Обычно базовых функциональных возможностей MS Excel хватает для выполнения подобных задач. Но что делать, если уровень обработки файла выходит за рамки этих возможностей? Ответ прост – использовать Python и библиотеку pandas, которая предназначена для обработки и анализа данных.
Представьте, что вы аналитик, который получил подобный файл.
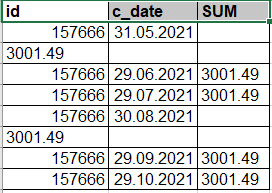
Задача, которая встает перед вами — привести файл в табличную форму для корректного анализа. Но как же это сделать? Чтобы решить данную задачу для начала нужно импортировать Pandas в свой скрипт Python, для этого добавить следующий код:
import pandas as pdПосле чего создать две переменные, которые будут соответствовать нашему начальную неструктурированному файлу и конечному исправленному.
path_in = r’C:\Users\19323727\Desktop\1.csv’
path_out = r’C:\Users\19323727\Desktop\1_.csv’
Затем «прочитать» наш изначальный файл, не забывая проставить разделитель. Важно помнить, что данное решение не является универсальным, а зависит от конкретной поставленной задачи.
df = pd.read_csv(path_in, sep = ‘;’)Так как файл содержит разрывы строк, необходимо заменить все переносы строк на знаки пробела, данную функцию выполняет нижеприведенный код. В квадратных скобках указываем наименование поля, по которому нарушается структура.
df[‘xxx’] = df[‘xxx’].str.replace[‘\r\n’,‘ ’]Вуаля, вы исправили наш изначальный файл!
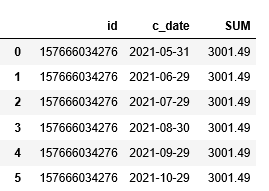
Последним шагом необходимо перезаписать результат в уже созданную нами ранее переменную path_out.
df.to_csv(path_out, sep = ‘;’, index = False)Отлично, мы справились с задачей, но что делать, если нам прислали файл, в котором пропущены не просто отдельные значения, а целые строки? Для этого существует простой метод «очистки» файла, который приведен ниже:
with open('arch.txt','r') as inf, open('arch1.txt','w') as out:
for line in inf:
if not line.isspace():
out.write(line)
Функция isspace() отлично подходит для решения подобного типа задач, поскольку она позволяет отсеивать строки, которые состоят только из пробелов. С помощью данного скрипта, мы проверяем все строки нашего файла, находим те, которые содержат хотя бы один символ и записываем их в итоговой файл. Рассмотрим еще один лайфхак для работы с неструктурированными данными. Допустим, вам необходимо обработать выборку, где присутствуют пустые значения, и вы хотите подсчитать их количество для дальнейшего анализа. Как же это реализовать? Для демонстрации данного кейса напишем следующий код.
import pandas as pd
import numpy as np
df = pd.DataFrame({ 'id_client': [123,254,354,543,321],
'request_november':['Negative','Negative','Negative','Affirmative',np.nan],
'request_december': [np.nan,'Negative',np.nan,'Negative','Negative'],
'request_january': ['Negative','Negative',np.nan,'Negative','Affirmative']})
print(df)
Выборка перед обработкой:
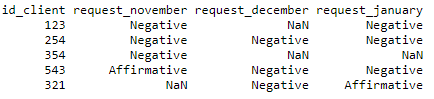
Решить поставленную задачу нам поможет нижеприведённый код:
df['count_nulls'] = df[['request_november', 'request_december','request_january']].isnull().sum(axis=1)В данной строке создается новый столбец датафрейма, каждым отдельным значением которого будет является функция суммирования всех нулевых значений по строкам. В результате модификаций наша итоговая выборка приобретет следующий вид:
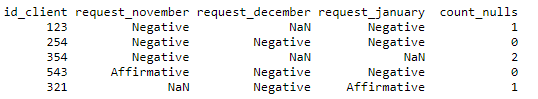
Данная функция очень проста и удобна для поиска отсутствующих значений и послужит отличным инструментом для быстрого и эффективного анализа данных. В заключении хотелось бы привести несколько фишек, используемых при сохранении подобных файлов. Одна из них — это проверка содержимого файла перед экспортом.
print(df[:5].to_csv())Вышеприведенная cтрока выведет первые 5 записей, которые будут записаны в файл, что в свою очередь поможет устранить возможность наличия некорректных записей в итоговой выборке. Итак, мы проверили файл перед его сохранением, но вдруг обнаруживаем, что по сравнению с начальной выборкой формат колонок изменился, к целочисленным значениям добавились «.0». Почему же так произошло?
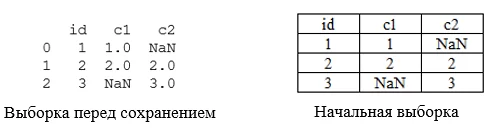
Дело в том, что, если колонка содержит и пропущенные значения, и целые числа, ее тип изменяется на float. Избежать подобного казуса позволит параметр float_format = ‘%.0f’, который принимает обычную строку форматирования с плавающей точкой. Добавление данного параметра при экспорте таблицы позволит округлить все значения до целых и сохранить первоначальный вид выборки. Таким образом, в данной статье были рассмотрены несколько методов и лайфхаков для обработки неструктурированных данных. Основное их преимущество – удобство и простота, что в свою очередь позволит использовать их людям даже с начальным уровнем IT-навыков.