/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Всё чаще в своей работе мы используем HiveQL, который на первый взгляд ограничен возможностями SQL. Хочу рассказать о нескольких встроенных в Hive функциях, которые окажутся очень полезны в работе с url, xml, json и помогут сэкономить нам массу времени.
Также мы рассмотрим функцию, которая позволит более оптимально работать с join при наличии небольших таблиц.
- PARSE_URL/PARSE_URL_TUPLE
Данная функция позволит нам с легкостью извлечь необходимую нам информацию из URL-адреса.
Синтаксис из официальной документации:parse_url(string urlstring, string parttoextract [, string keytoextract]).
Допустимые значения дляparttoextractэтоHOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILEиUSERINFO.
Наглядно увидеть принцип её работы мы сможем на примерах ниже:
select parse_url ('https:// randomnyjsajt.ru/path1/p.php?k1=v1&k2=v2#Ref1','HOST');
>>> randomnyjsajt.com
select parse_url ('https:// randomnyjsajt.ru/path1/p.php?k1=v1&k2=v2#Ref1','QUERY','k1');
>>> v1
Если нам необходимо извлечь несколько значений из URL одновременно, то оптимальным решением будет воспользоваться функцией parse_url_tuple.
Синтаксис из официальной документации: parse_url_tuple (string urlStr,string p1,…,string pn)
select parse_url_tuple ('https://randomnyjsajt.ru/path1/p.php?d1=v1&d2=v2#Ref1','QUERY:d1','QUERY:d2')
>>> v1 v2
2. XPATH
Функция для анализа XML-данных с использованием выражений XPath. С её помощью мы без труда сможем получить необходимую нам для работы информацию из xml-данных.
Синтаксис из официальной документации: xpath (xml_string, xpath_expression_string)
Пример использования:
select xpath('d1d2','c/*/text()') limit 1;>>> [d1″,»d2]
Более подробно с данной функцией и дополнительными возможностями можно ознакомиться в официальной документации по ссылке.
- GET_JSON_OBJECT/JSON_TUPLE
В своей работе мы часто сталкиваемся с данными, которые хранятся в формате json. Hive уже содержит несколько встроенных методов для взаимодействия с этим форматом. Для извлечения значений из json незаменима функцияget_json_object. Согласно данных, из официальной документации используется ограниченная версия JSONPath. Список поддерживаемых и недоступных операций указан в таблице.
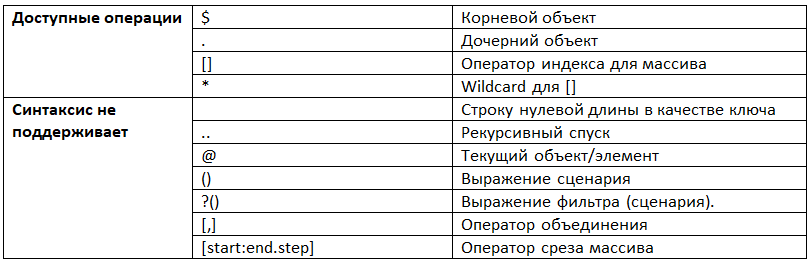
Предположим, что у нас уже есть готовая таблица test, которая состоит из одного столбца (указал json ниже) и строки.
{"shop":
{"vegetable":\[{"number":7,"view":" tomato"},{"number":3,"view":"cucumber"}],
"skateboard":{"price":20.60,"color":"blue"}
},
"e-mail":"petro@sberbang.ru",
"boss":"petro"
}
Пример использования:
select get_json_object(test, '$.e-mail') from test;
>>> {«number»:7,»view»:» tomato»}
select get_json_object(test, '$.shop.vegetable\[0]') from test;>>> petro@sberbang.ru
Нередко возникают ситуации, когда нам требуется извлечь более одного значения из json. Для этих целей лучше подойдет функция json_tuple:
select a1.e-mail, a1. boss
from test js
LATERAL VIEW json_tuple(js.test, 'e-mail', 'boss') a1
as e-mail, boss;>>> petro@sberbang.ru petro
- MAPJOIN
Ранее в одной из статей коллеги кратко упоминалиMapJoinкак один из методов оптимизации операцийjoin. Сегодня мы рассмотрим его чуть подробнее.
Довольно часто нам приходится объединять большие таблицы с небольшими справочниками. На текущий момент дляjoin‘а двух таких таблиц требуется несколькоMapReduceзадач. Исправить данную ситуацию можно с помощьюMapJoin. Для этого нам необходимо загрузить небольшую таблицу (25-30 мб) в оперативную память ноды. Сделать это можно двумя способами:
- Установить:
hive.auto.convert.join = true; - Указать
MapJoinвselect
select /*+ mapjoin(m) */ count(*)
from malaya_tablica m
join bolshaya_tablica b
on (m.key = b.key)
Стоит так же отметить, что с данным методом не работает right и full outer join.
Как мы видим hive это довольно самостоятельный инструмент для работы с большим количеством различных данных. Благодаря функциям, описанным в статье, нам не придется использовать сторонние инструменты для обработки большей части данных и облегчит работу тем, кто привык работать с SQL.