/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Как оптимально разделить набор данных на обучающую, валидационную и тестовую выборки?
У каждого подмножества данных есть цель, от создания модели до обеспечения её производительности:
Обучающий набор: это подмножество данных, которые я буду использовать для обучения модели.
Валидационная выборка: используется для контроля процесса обучения. Она поможет предотвратить переобучение и обеспечит более точную настройку входных параметров.
Тестовый набор: подмножество данных для оценки производительности модели.
Размер и соотношение данных для обучения.
Чтобы принять решение о размере каждого подмножества, я часто вижу стандартные правила и соотношения. Сталкиваюсь с разделением по правилу 80-20 (80 % для тренировочного сплита, 20% для тестового сплита) или по правилу 70-20-10 (70% для обучения, 20% для проверки, 10% для тестирования) и т.д.
Было несколько дискуссий о том, каким может быть оптимальное разделение, но в целом отсутствие достаточного количества данных как в обучающем, так и в проверочном наборе приведет к тому, что модель будет трудно изучить/обучить или определить, действительно ли эта модель работает хорошо или нет.
В BigQuery, как правило, можно создать только подмножество для обучения и тестирования, потому что проверка может быть выполнена при создании модели с DATA_SPLIT опцией.
Прежде чем разделить набор данных, необходимо знать о некоторых распространённых ловушках:
Низкокачественные данные: если входные данные, использованные для создания вашей модели, имеют выбросы, это скорее всего негативно повлияет на качество модели.
Переобучение: когда входных данных недостаточно, но построенная модель хорошо объясняет параметры из обучающей выборки, то считается, что любой выброс или колебания приводят к недостоверным прогнозам.
Несбалансированный набор данных: представьте, что вы хотите обучить модель, которая предсказывает покупку клиента, но у вас есть 500 тысяч потенциальных покупателей и 300 покупателей. Для начала нужно создать более равный набор данных (используя технику повторной выборки). Исследовательский анализ данных (EDA) поможет выявить несбалансированные данные.
Утечка данных: означает, что входные данные были изменены (масштабированы, преобразованы) перед созданием обучающего набора данных или во время их разделения.
Разделение набора данных с помощью SQL
Для эксперимента у меня есть следующий набор данных, состоящий из 11 тыс. строк и трёх полей идентификатора заказа, даты и связанного значения заказа.
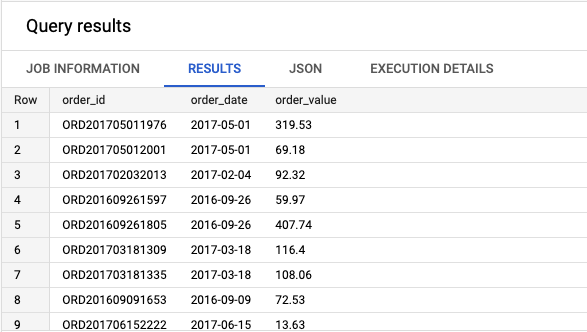
Разделю эту таблицу на обучающую и тестовую подгруппы.
Выбор правильного столбца для разделения
Чтобы сделать правильное разделение, используйте один столбец, который отличает каждую строку вашей базовой таблицы. В противном случае может быть трудно создать равномерно распределённое разделение.
Чтобы добиться уникальности, есть несколько вариантов в практических примерах:
- Создать новое поле с уникальными значениями (например, функция генератора случайных чисел, такая как RAND()или UUID())
- Создать хеш одного уже уникального поля или хеш комбинации полей, которая создает уникальный идентификатор строки
Для второго варианта наиболее распространенной хеш-функцией, является FARM_FINGERPRINT().
Почему именно этот, а не MD5() или SHA ()?
Это обусловлено двумя особенностями. Во-первых, он всегда даёт одни и те же результаты для одних и тех же входных данных, а во-вторых, он возвращает INT64 значение (число, а не комбинацию чисел и символов), которым можно управлять с помощью других математических функций, например, MOD () для получения коэффициента разделения.
Создайте уникальный идентификатор строки
Чтобы создать уникальный идентификатор строки, использую FARM_FINGERPRINT() функцию:
WITH
base_table AS (
SELECT
*
FROM
`datastic.train_test_split.base_table`)
-- Main Query
SELECT
*,
FARM_FINGERPRINT(order_id) AS hash_value_order_id,
TO_JSON_STRING(bt) AS full_json_row,
FARM_FINGERPRINT(TO_JSON_STRING(bt)) AS hash_value_full_row,
MOD(FARM_FINGERPRINT(order_id), 10) AS hash_mod,
ABS(MOD(FARM_FINGERPRINT(order_id), 10)) AS hash_abs_mod
FROM
base_table bt
То, что я буду продолжать разбивать в нашем наборе данных, это последний столбец (hash_abs_mod).
Следующая таблица иллюстрирует каждый шаг процесса хеширования слева направо.
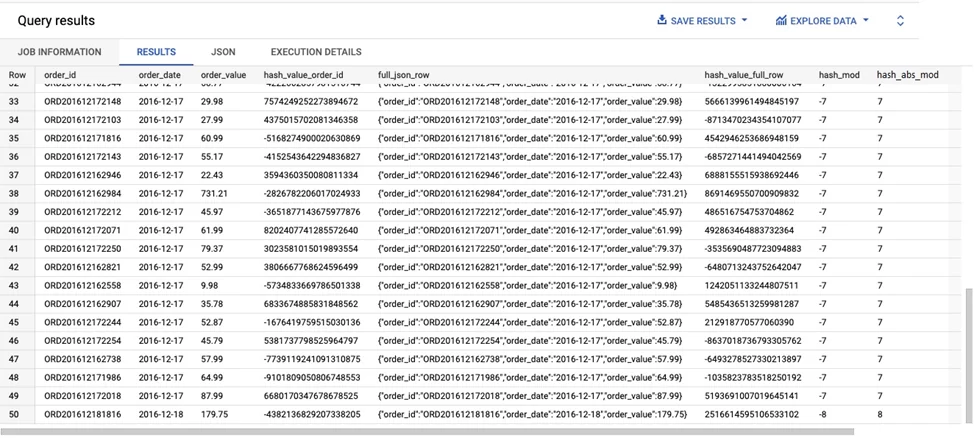
Влияние хеш-функции и функции по модулю на нашу базовую таблицу.
В базовой таблице уже есть уникальный идентификатор значения для каждой строки, это order_id поле. В этом случае мы можем просто хешировать его, а использовать ABS(MOD(x,10)) функции для классификации каждой строки в сегментах от 0 до 9.
Чтобы создать хеш всей строки, то есть всех столбцов, обозначим её bt, затем делаем JSON, используя TO_JSON_STRING (bt).
Затем хешировать? Цель этого метода избежать повторяющихся строк, которые всегда будут попадать в одно и то же разделение.
Создание неповторяемого разделения
Чтобы случайным образом разделить набор данных, можно использовать RAND () функцию. Это вернёт для каждой строки псевдослучайное десятичное число в интервале 0–1, включая 0 и исключая 1.
Эта функция обеспечивает равномерное распределение, что означает, что можно отфильтровать, например, все значения ниже 0,8-80% моих данных.
Но каждый раз, когда запускаем запрос, функция будет возвращать разные числа, поэтому наборы для обучения и тестирования будут разными.
Запущу случайное разделение для 80% обучения и 20% тестирования:
WITH
base_table AS (
SELECT
*
FROM
`datastic.train_test_split.base_table`)
-- Main Query
SELECT
*,
RAND() AS pseudo_random,
IF
(RAND() < 0.8,
'train',
'test') AS split_set,
FROM
base_table
view raw
Вы можете увидеть в результатах, что есть число со многими десятичными знаками, сгенерированное RAND () функцией, и метка, заданная IF () оператором.
Но, не сможете воспроизвести точно такое же разделение, если не сохраните результаты как есть.
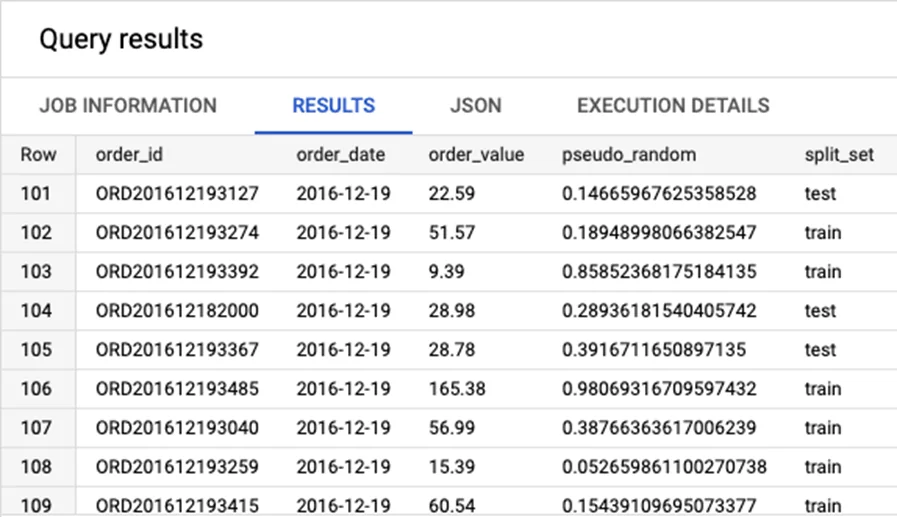
Разделить на обучение и тестирование с помощью RAND.
Создание повторяемого разделения
Чтобы создать разделение, которое можно использовать повторно, лучше всего использовать комбинацию функций MOD()и FARM_FINGERPRINT(), потому что выходные данные останутся одинаковыми для одних и тех же входных данных.
Использую уникальный ключ (order_id поле). Можно использовать оператор CASE WHEN со следующим диапазоном, чтобы сделать повторяемое разделение 80/10/10:
WITH
base_table AS (
SELECT
*
FROM
`datastic.train_test_split.base_table`)
-- Main Query
SELECT
*,
CASE
WHEN ABS(MOD(FARM_FINGERPRINT(order_id), 10)) < 8 THEN 'train'
WHEN ABS(MOD(FARM_FINGERPRINT(order_id), 10)) = 8 THEN 'validation'
WHEN ABS(MOD(FARM_FINGERPRINT(order_id), 10)) = 9 THEN 'test'
END
AS split_set
FROM
base_table bt
Разделение на 3 подмножества (обучение, проверка и тестирование).
Результат будет таким же, как и для предыдущего неповторяемого разделения, за исключением того, что этот запрос всегда будет производить одно и то же разделение.
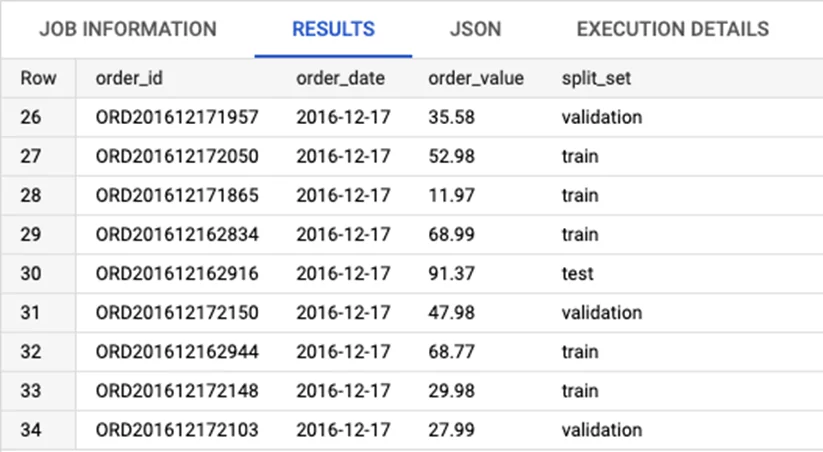
Разделить на обучение, проверку и тестирование с помощью MOD () и FARM_FINGERPRINT ().
Вывод:
Теперь вы знаете, как лучше разделить набор данных на подмножества, с возможностью повторного использования. Этот метод дает 2 преимущества:
1) Одни и те же результаты для входных данных.
2) Возвращает значение в виде числа, а не комбинацию чисел и символов, которым можно легко управлять, что позволяет сократить время обработки. Это означает, что необходимо проверить, какой временной диапазон покрывает 80% (в случае разделения 80/20) наших базовых данных.
Кроме того, строки с одной и той же датой имеют тенденцию быть коррелированными, поэтому эти строки должны оставаться в одном разбиении.