/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Идея данного проекта состоит в том, чтобы создать модель машинного обучения, которая могла бы определять, являются ли заголовки новостей, представленные в интернете, правдой или нет. Для обучения модели в данной статье будем использовать данные из файла train.tsv, который содержит новостные заголовки взятые с https://panorama.pub и https://lenta.ru. В файле находится таблица, состоящая из двух колонок. В колонке title записаны заголовки новостей. В колонке is_fake содержатся метки: 0 – новость реальная, 1 – новость выдуманная (рисунок 1).
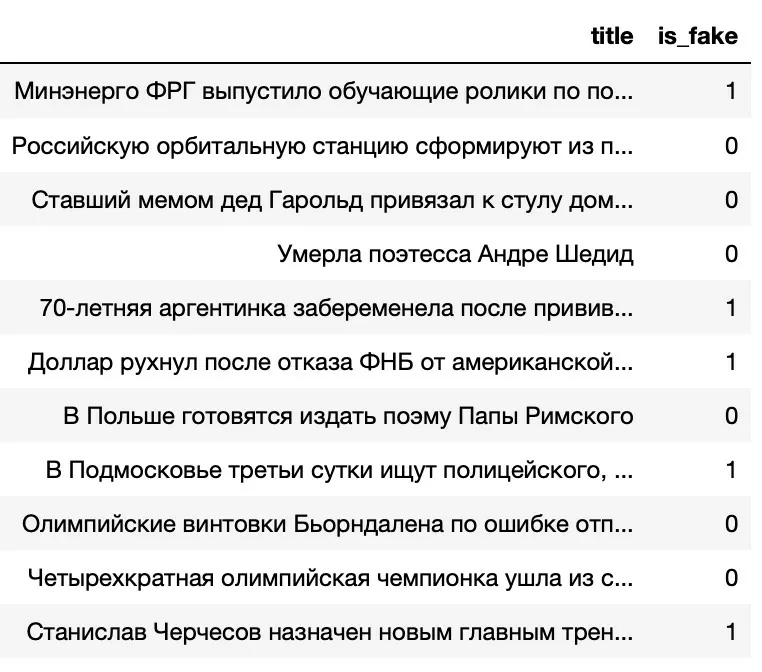
Рисунок 1 – Таблица с заголовками и метками из train.tsv
Для демонстрации работы модели используются данные тестового набора из файла test.tsv. В нем также есть колонка title, данные которой являются входными для модели.
Однако изначально колонка с метками заполнена значением 0. Прежде чем приступать к обучению модели, необходимо провести оценку или анализ данных. Так в первую очередь оценим соотношение реальных и фальшивых заголовков в исследуемом наборе данных (рисунок 2):
fig, ax = plt.subplots(figsize=(22,12))
sns.countplot(x=df[“is_fake”], palette=”Set2”)
ax.set(title=»Соотношение фейковых и реальных заголовков»)
plt.ylabel(«Кол-во заголовков»)
plt.xlabel(«Заголовок»)
plt.show()

Рисунок 2 – Соотношение меток фальшивых и реальных заголовков
Из рисунка 2 видно, что соотношение меток составляет 50% на 50%. Даже если это явно не заметно, проверим следующим способом:
#количество значений разными метками
df['is_fake'].value_counts()
Output:
1 2879
0 2879
Name: is_fake, dtype: int64
Видно, что количество реальных и фейковых заголовков в обучающем наборе у нас одинаковое.
Теперь приступим непосредственно к созданию модели. Прежде чем создавать «мешок слов» удалим стоп-слова с помощью набора stopwords от nltk для русского языка, а также проведем лемматизацию каждого слова в начальную форму.
Кратко о том, что такое «мешок слов» и лемматизация:
«Мешок слов» — наиболее распространенный метод преобразование текста в признаки. Данные методы выводят признак для каждого уникального слова в текстовых данных, но при этом каждый признак содержит количество вхождений в наблюдениях.
Например, в предложении «Бразилия — моя любовь. Бразилия!» имеет значение 2 в признаке «Бразилия», потому что слово Бразилия появляется два раза.
С помощью pymorphy2 приведем слова к начальной (нормальной) форме:
люди -> человек,
гулял -> гулять,
И т.д.
Начальную форму слова можно получить через атрибуты Parse.normal_form и Parse.normalized. Чтобы получить объект Parse, нужно первым делом разобрать слово и выбрать правильный вариант разбора из предложенных. Рассмотрим реализацию:
#импорт библиотек и загрузка модулей
from nltk.corpus import stopwords #импорт набора стоп-слов
import pymorphy2
import re #регулярные выражения
from string import punctuation #сборник символов пунктуации
stopWords = stopwords.words("russian")
morph = pymorphy2.MorphAnalyzer()
Проведем очистку текстовых данных от символов пунктуации, также приведем весь текст к нижнему регистру и выберем начальную форму каждого слова в заголовке:
def lemmatize(content):
review = re.sub('(?i)[^А-ЯЁA-Z]',' ',content)
review = review.lower()
review = review.split()
review = [morph.parse(word)[0].normal_form for word in review if not word in stopwords.words('russian')]
review = ' '.join(review)
return review
Далее применим функцию для очистки текста, это делается довольно просто:
df['title_normalize'] = df['title'].apply(lemmatize)На выходе получаем следующий результат (рисунок 3):

Рисунок 3 – Очистка и лемматизация
Далее уже идет классический сценарий для обучения любой модели, а именно разделим набор данных на тренировочный и тестовый наборы:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(df['title_normalize'],
df['is_fake'],
test_size=0.2,
random_state=7)
print('Тренировочный набор:', x_train.shape)
print('Тестовой набор:', x_test.shape)
На выходе можем посмотреть сколько данных ушли для тренировки и для теста соответственно:
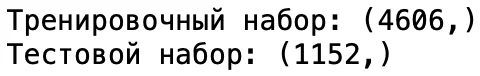
Импортируем необходимые библиотеки для обучения модели:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import PassiveAggressiveClassifier,LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score, confusion_matrix
Для «мешка слов» будут отбираться слова, взвешенные по их важности для наблюдения. То есть необходимо сравнить частоту слова в заголовке с частотой слова во всех других заголовках, используя статистическую меру словарной частоты — обратной документной частоты (tf-idf). Библиотека scikit-learn позволяет легко это делать с помощью класса TfidfVectorizer:
tfidf_vectorizer=TfidfVectorizer(stop_words=stopWords, max_df=0.7)Обучение и преобразование переменных x_train и x_test:
tfidf_train=tfidf_vectorizer.fit_transform(x_train)
tfidf_test=tfidf_vectorizer.transform(x_test)
Теперь перейдем к самому интересному и интригующему пункту — выбор классификатора и его оценка на тестовой выборке.
Мною были выбраны и рассмотрены, на мой взгляд, самые популярные классификаторы для NLP задач, а именно:
- PassiveAggressiveClassifier;
- MultinomialNB (Naive Bayes);
- Logistic Regression;
- Linear SVC.
Посмотрим на PassiveAggressiveClassifier и его точность по результатам обучения:
pac=PassiveAggressiveClassifier(max_iter=50)
pac.fit(tfidf_train, y_train)
y_pred=pac.predict(tfidf_test)
score_pac=accuracy_score(y_test, y_pred)
print(f'Точность PassiveAggressiveClassifier: {round(score_pac*100,2)}%')
На выходе получаем следующее:
Точность PassiveAggressiveClassifier: 82.29%В качестве метрики была выбрана Accuracy, так как данный показатель дает представление об общей точности предсказании моделей по всем классам. Поэтому знать это в данном проекте особенно полезно, так как каждый из классов важен. Данная метрика рассчитывается как отношение суммы правильных предсказаний к их общему количеству.
Однако при использовании данной метрики есть особенность, про которую необходимо помнить. Если распределение заголовков в обучающем наборе сильно смещено в сторону какого-то одного из классов, то при таком раскладе у классификатора есть больше информации по одному из классов и соответственно в рамках этого класса он будет принимать более верные решения. При такой ситуации, даже учитывая то, что accuracy может составлять, скажем, 80%, классификатор будет работать плохо и не определяя даже трети заголовков. Ниже показан отчет о классификации и матрица ошибок:
confusion_matrix(y_test,y_pred)Получаем:
array([[473, 101],
[103, 475]])
Что можно заметить по матрице ошибок? То, что 101 заголовок имеет ошибку 1-го рода, то есть модель предсказала положительный результат, а на самом деле он отрицательный. И 103 заголовка, которые имеют ошибку 2-го рода – модель предсказала отрицательный результат, но на самом деле он положительный. Теперь взглянем на результаты каждого классификатора и его точности:
data_result = pd.DataFrame()
data_result['classifier'] = ['PassiveAggressiveClassifier',
'MultinomialNB (Naive Bayes)',
'Logistic Regression', 'Linear SVC']
data_result['results'] = score_pac, score_NB, score_LR, score_L_SVC
data_result.sort_values(by='results')
Ниже будет приведен датафрейм, в котором указаны результаты каждого классификатора и из него можно заметить, что Наивный Байес показал себя чуть лучше остальных (рисунок 4):

Рисунок 4 – Результаты классификаторов
Из рисунка 4 видно, что лучшим из 4-х классификаторов оказался MultinominalNB, поэтому прогоним через эту модель тестовый датасет (test.tsv) и определим фейковый заголовок или нет.
#импортируем тестовый набор
df_new = pd.read_csv("../nlp_test_task_2022/dataset/test.tsv", sep='\t')
#приводим слова в заголовках к начальной форме
df_new['title_normalize'] = df_new['title'].apply(lemmatize)
tfidf_test=tfidf_vectorizer.transform(df_new['title_normalize'])
#определяем метку для заголовка
new_label_test = []
for doc, category in zip(df_new['title'], NB.predict(tfidf_test)):
print('%r => %s' % (doc, category))
new_label_test.append(category)
На выходе получаем:

В данной статье были рассмотрены классические подходы решения конкретной NLP задачи, для которой была получена достаточно хорошая точность, но все равно возникает вопрос: «возможно ли еще улучшить модель?». Ответ на этот вопрос «очевидно, да», так как данный проект имеет множество возможностей для улучшений и модификаций, которые хотелось бы рассмотреть в следующей статье.