/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В построении кросс-таблиц помогают функции библиотеки Pandas pivot_table() и crosstab(). На последней остановлюсь поподробнее в этой статье.
Импортирую необходимые библиотеки:
import pandas as pd
import numpy as np
Рассматривать процесс создания кросс-таблиц буду на примере датасета Титаника.
Например, надо посмотреть на количество выживших и погибших мужчин и женщин (столбец Survived, где 0 – пассажир погиб, а 1 – пассажир выжил). Если задачу решать через pivot_table(), то решение будет выглядеть следующим образом:
pd.pivot_table(titanic, index=['Survived'], columns=['Sex'],values='Fare', aggfunc='count') 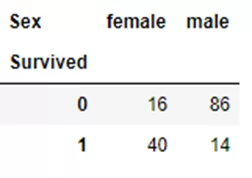
Аналогично через crosstab():
pd.crosstab(titanic.Survived,titanic.Sex)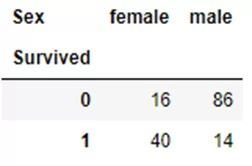
Как видно, результат вывода идентичен, а код через crosstab(), выглядит менее громоздким, чем через pivot_table(). В качестве обязательных аргументов в crosstab передаются два объекта Series
Если добавить аргумент margins=True, будут подсчитываться итоговые значения по строкам и столбцам:
pd.crosstab(titanic.Survived,titanic.Sex,margins=True) 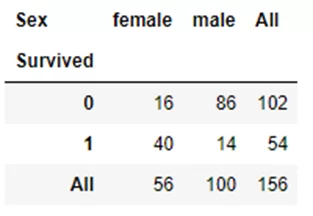
Если же необходимо посмотреть на данные в процентном соотношении, то надо передать в функцию crosstab аргумент normalize=True:
pd.crosstab(titanic.Sex, titanic.Pclass, normalize=True, margins=True)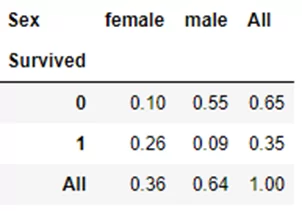
Получается, что чуть больше половины от всех пассажиров в выборке это погибшие пассажиры мужского пола (55%).
Но какое соотношение выживших и погибших среди мужчин и женщин? Ответить на этот вопрос нам поможет передача аргументу normalize значения columns:
pd.crosstab(titanic.Survived,titanic.Sex,normalize='columns').round(2) 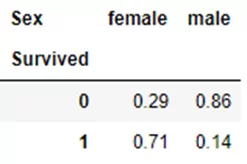
Как видно из полученных результатов большей доли (71%) пассажиров женского пола удалось спастись, в то время как большая часть мужчин погибла (86%).
А передав в normalize значение index можно посмотреть какая долю погибших и выживших отдельно среди всех пассажиров мужского и женского пола:
pd.crosstab(titanic.Survived,titanic.Sex,normalize='index').round(2)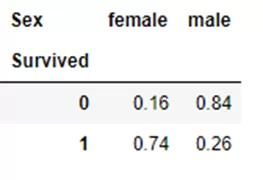
Среди погибших преобладают пассажиры мужского пола (84%), а среди выживших наоборот больше женщин (74%).
Если же необходимо посмотреть более детальную информацию, например, в разрезе классов, то во второй аргумент к половому признаку titanic.Sex можно добавить еще один объект Series titanic.Pclass:
pd.crosstab(titanic.Survived,[titanic.Sex,titanic.Pclass],normalize='index').round(2) 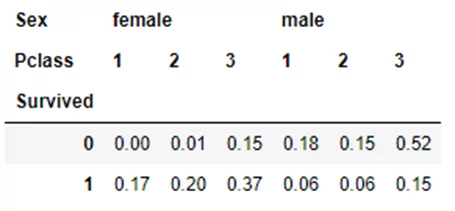
Тут уже видно, что среди погибших, чуть больше половины — это мужчины из 3 класс (52%).
По умолчанию агрегирование осуществляется при помощи аргумента aggfuncсо значениемcount. Передав значения sum и mean, можно увидеть суммарные и средние значения соответственно. Например, средний возраст пассажиров в разрезе пола и класса:
pd.crosstab(titanic.Sex, titanic.Pclass, values=titanic.Age, aggfunc='mean', margins=True).round(0).fillna('-') 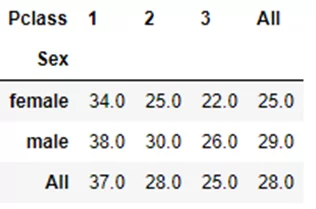
Обратите внимание, что при добавлении аргумента aggfunc (агрегирующая функция), необходимо добавить еще и аргумент values (агрегируемый столбец) и наоборот.
Хоть функционал инструмента crosstab и пересекается с pivot_table, в нём удобнее строить процентные соотношения показателей, в то время как для pivot_table необходимо писать отдельную функцию, что делает crosstab очень удобным и полезным инструментом для анализа данных.