/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Сегодня я рассмотрю алгоритм чтения и парсинга .pst файлов, написанный на python. Для работы с одним файлом и оставлю в стороне параллельную обработку, которую стоит использовать при работе с большим числом архивов.
Для открытия и чтения .pst файлов воспользуюсь pypff – python оберткой для библиотеки libpff, написанной на C. Эта библиотека позволяет работать с форматами PFF (Personal Folder File) и OFF (Offline Folder File), в которые как раз и входит формат .pst, наряду с форматами .pab (Personal Address Book) и .ost (Offline Storage Table).
# Установка библиотеки
pip install libpff-python
# Импортирование библиотеки
import pypff
Работа с файлом будет подобна работе с древовидным архивом. Поэтому в первую очередь после чтения файла необходимо получить корневую папку:
pst = pypff.file()
pst.open(“example.pst”)
root = pst.get_root_folder()
Дальше порядок действий будет отличаться в зависимости от задач. Например, вы можете посмотреть список дочерних писем или папок и выбрать из них нужные и обработать только их. В случае с задачей поиска идентификаторов, буду вынужден обрабатывать все письма из всех папок, так как обрабатываемые почтовые ящики имеют разную структуру папок (в первую очередь разные названия и степени вложенности).
Для получения списка всех писем воспользуюсь рекурсивным методом, который проходит по папке и собирает содержимое из нее и её дочерних папок:
def parse_folder(base):
messages = []
for folder in base.sub_folders:
if folder.number_of_sub_folders:
# Извлечение писем из дочерней папки
messages += parse_folder(folder)
# Обработка писем в текущей папке
for message in folder.sub_messages:
messages.append({
"folder": folder.name,
"subject": message.subject,
"sender_name": message.sender_name,
"sender_email": get_sender_email(message),
"datetime": message.client_submit_time,
"body_plain": get_body(message)
})
return messages
# Извлечение всех писем из файла
messages = parse_folder(root)
Как можно увидеть, письма сразу превращаю в словари, извлекая нужную информацию из объектов pff.message. Для атрибутов в классе message определены также get методы. Чтобы посмотреть полный список атрибутов, можно воспользоваться встроенной функцией __dir__(), вызвав её для соответствующего объекта. Ниже приведен список таких атрибутов и методов, для понимания возможностей работы с письмами:
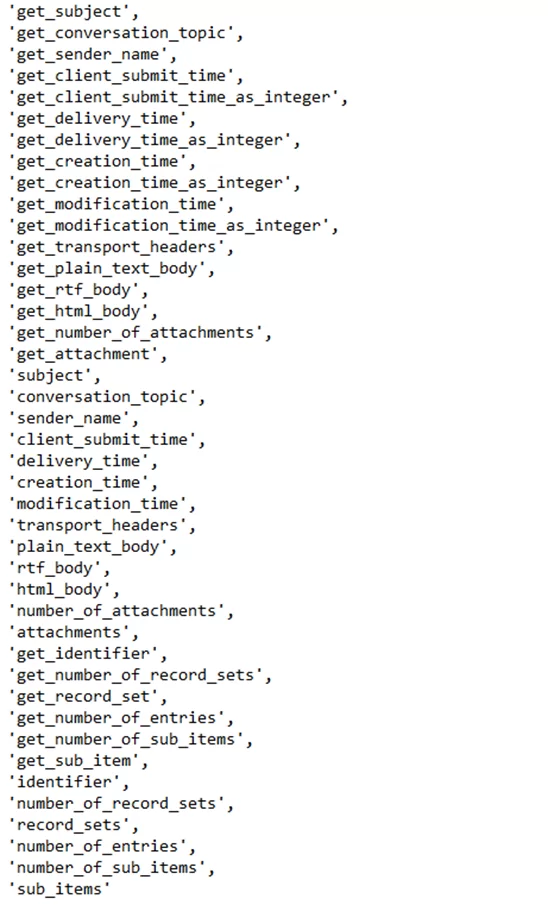
Для анализа была необходима следующая информация: тема письма, тело письма, папка, дата и время и данные об отправителе. Большую часть этой информации можно получить, просто взяв сами атрибуты объекта, но такой вариант не сработает для тела письма и почтового адреса отправителя.
Как можно видеть из списка атрибутов pff.message, письмо может иметь тело в трех форматах (plain_text, html, rtf), а точнее в одном из этих трех. Для задачи меня будет интересовать получение тела письма в формате текста, поэтому необходимо конвертировать html строки (которых оказалось больше всего). Для этого воспользуемся библиотекой BeautilfulSoup: создадим объект bs на основе нашего html_body и воспользуемся методом get_text(), чтобы получить очищенный от html тегов текст письма. На этом можно было бы остановится, но в результирующих строках оставались комментарии с описанием стилей и шрифтов, поэтому дополнительно производится их удаление с помощью регулярных выражений, а также замена двойных символов перевода строки на одинарные.
# Обработка plain_text тела
def process_plain_text_body(message):
return re.sub(r'([\r\n]+ ?)+', r'\r\n', message.plain_text_body.decode('utf-8'))
# Обработка html тела
def process_html_body(message):
soup = bs(message.html_body(), "lxml")
plain_text = soup.get_text()
# Удаление html комментариев
plain_text = re.sub(r'(<!--.*-->)+', r'', plain_text, flags=re.S)
plain_text = re.sub(r'([\r\n]+ ?)+', r'\r\n', plain_text)
return plain_text
def get_body(message):
if message.get_plain_text_body():
return process_plain_text_body(message)
if message.get_html_body():
return process_html_body(message)
Остается получить адрес отправителя, для которого, в отличие от имени, выделенного атрибута не оказалось. Внимательный читатель мог заметить, что в pff.message имеется поле с интригующим названием «transport_headers». Обратившись к данному атрибуту, я увидел бы содержимое, описывающее путь электронного письма (изображение взято из интернета для примера).
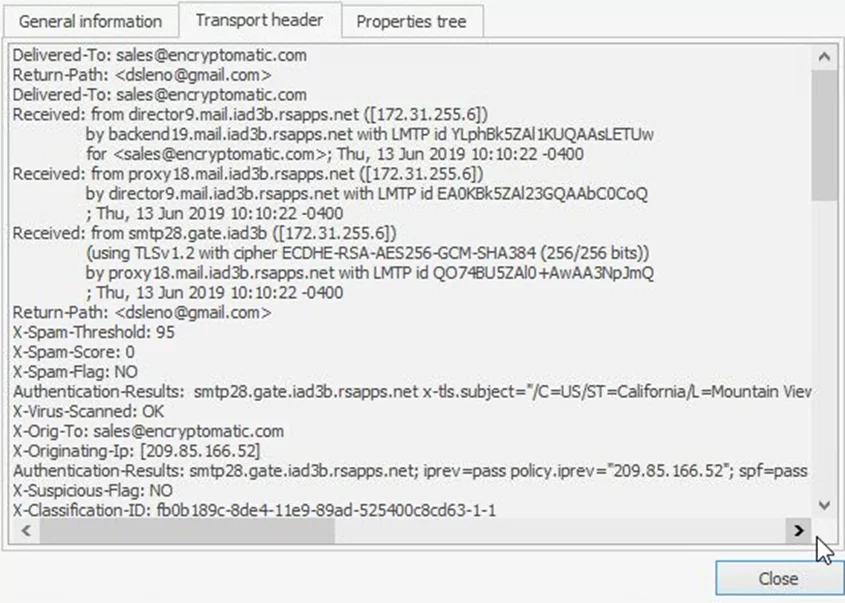
Интересующее значение можно найти по ключу «Return-Path», с тем отличием, что электронный адрес не был обрамлен треугольными скобками.
Собрав все воедино, получичился один объект словаря, содержащий интересующие нас атрибуты исходного письма, а в результате обработки всего ящика получин список словарей. Не забываем закрыть файл после чтения списка писем.
def extract_messages_from_file(filename):
pst = pypff.file()
pst.open(filename)
root = pst.get_root_folder()
messages = parse_folder(root)
pst.close()
return messages
Полученный список можно обрабатывать по своему усмотрению, например, искать определенные строки в темах или телах писем, или выбрать все письма от одного отправителя.
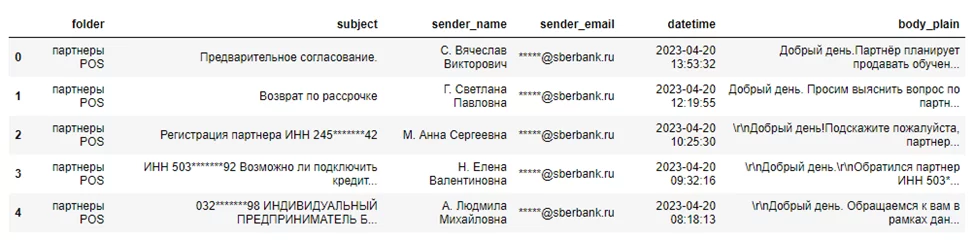
Для дальнейшего визуального анализа писем и извлеченных из них данных можно конвертировать список в pandas DataFrame и воспользоваться методом «to_excel()» для записи в файл. Ниже приведён пример итоговых записей из DataFrame:
Подводя итоги, скажу, что задача обработки архивов почтовых ящиков – не частый гость, и порой бывает гораздо проще открыть .pst файл через Outlook и вручную найти интересующую информацию. Но если речь заходит про обработку десятков .pst файлов и поиск данных в каждом из них, то без автоматизации такая задача может стать настоящей пыткой.
Предложенный алгоритм позволяет прочитать архив почтового ящика и извлечь из него интересующее содержимое для всех писем. Полученные данные очищены от метатегов и приведены к единому формату, пригодному для чтения аналитиком. Этот алгоритм может быть использован для обработки одного ящика или для обработки нескольких, путем последовательного вызова или с использованием методов мультипроцессинга для повышения скорости обработки.