/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 6 мин.
Для начала, что такое «Web-Scraping»? Это автоматизированный процесс извлечения данных с какой-либо веб-страницы. Когда не было возможности автоматизировано извлекать данные со страниц, извлекали данные вручную, что занимало достаточно большое количество времени. Сейчас же можно ускорить извлечение данных в разы при помощи различных языков программирования и специальных инструментов.
Информации в интернете становится все больше, как следствие, время на извлечение данных увеличивается. Возникает необходимость в решении данной задачи.
В данном случае рассмотрю способ с применением python библиотеки BeautifulSoup4 в связке с библиотекой asyncio.
Асинхронное программирование – это особенность современных языков программирования, которая позволяет выполнять операции, не дожидаясь их завершения. Библиотека asyncio предназначена как раз для этого.
Допустим, я буду извлекать данные из трёх страниц веб-сайта с применением привычных библиотек BeautifulSoup4 и Requests.
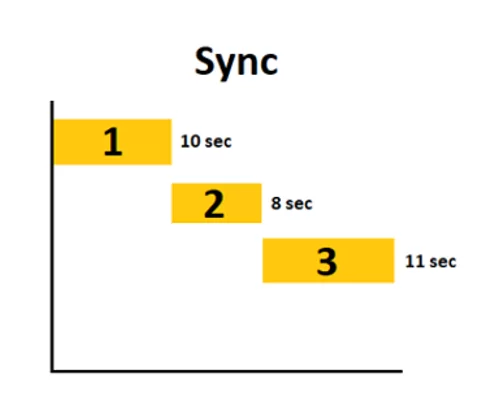
Сначала потребуется 10 секунд на извлечение данных с первой страницы, потом 8 со второй и 11 секунд с третьей страницы, что в итоге займет (10 + 8 + 11) 29 секунд.
При использовании библиотеки asyncio не надо дожидаться завершения извлечения данных с первой страницы, чтобы начать извлекать данные со второй. В итоге будет выиграно время.
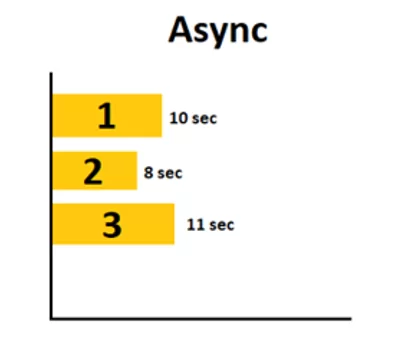
Время на извлечение данных сокращается до максимального времени выполнения сбора данных с какой-либо из страниц. В данном случае максимальным временем является время, возложенное на третью страницу (11 секунд).
Ниже приведен пример разницы во времени, затраченного на извлечение данных при помощи библиотек BS4 + Requests в сравнении с BS4 + Asyncio.
Первый скрипт:
import json
import time
import requests
from bs4 import BeautifulSoup
import datetime
import csv
start_time = time.time()
def get_data():
cur_time = datetime.datetime.now().strftime('%d_%m_%Y_%H_%M')
with open(f'labirint_{cur_time}.csv', 'w') as file:
writer = csv.writer(file)
writer.writerow(
(
'Название книги',
'Автор',
'Издательство',
'Цена со скидкой',
'Цена без скидки',
'Процент скидки',
'Наличие на складе'
)
)
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
url = 'https://www.labirint.ru/genres/2308/?available=1&paperbooks=1&display=table'
response = requests.get(url=url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
pages_count = int(
soup.find('div', class_='pagination-numbers').find_all('a')[-1].text)
books_data = []
for page in range(1, pages_count + 1):
url = f'https://www.labirint.ru/genres/2308/?available=1&paperbooks=1&display=table&page={page}'
response = requests.get(url=url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
books_items = soup.find(
'tbody', class_='products-table__body').find_all('tr')
for bi in books_items:
book_data = bi.find_all('td')
try:
book_title = book_data[0].find('a').text.strip()
except:
book_title = 'Нет названия книги'
try:
book_author = book_data[1].text.strip()
except:
book_author = 'Нет автора'
try:
book_publishing = book_data[2].find_all('a')
book_publishing = ':'.join([bp.text for bp in book_publishing])
except:
book_publishing = 'Нет издательства'
try:
book_new_price = int(book_data[3].find('div', class_='price').find(
'span').find('span').text.strip().replace(' ', ''))
except:
book_new_price = 'Нет нового прайса'
try:
book_old_price = int(book_data[3].find(
'span', class_='price-gray').text.strip().replace(' ', ''))
except:
book_old_price = 'Нет старого прайса'
try:
book_sale = round(
((book_old_price - book_new_price) / book_old_price) * 100)
except:
book_sale = 'Нет скидки'
try:
book_status = book_data[-1].text.strip()
except:
book_status = 'Нет статуса'
books_data.append(
{
'book_title': book_title,
'book_author': book_author,
'book_publishing': book_publishing,
'book_new_price': book_new_price,
'book_old_price': book_old_price,
'book_sale': book_sale,
'book_status': book_status
}
)
with open(f'labirint_{cur_time}.csv', 'a') as file:
writer = csv.writer(file)
writer.writerow(
(
book_title,
book_author,
book_publishing,
book_new_price,
book_old_price,
book_sale,
book_status
)
)
print(f'Обработана {page}/{pages_count}')
time.sleep(1)
with open(f'labirint_{cur_time}.json', 'w') as file:
json.dump(books_data, file, indent=4, ensure_ascii=False)
def main():
get_data()
finish_time = time.time() - start_time
print(f'Затраченное на работу скрипта время: {finish_time}')
if __name__ == '__main__':
main()
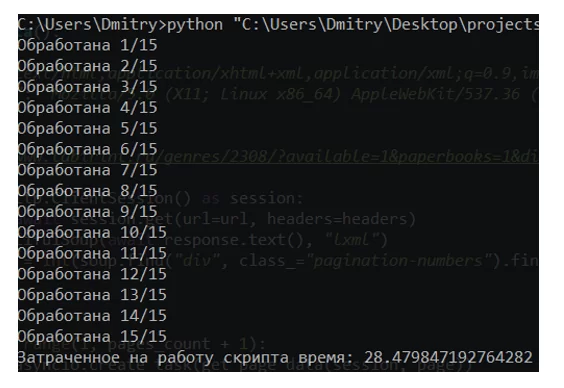
Время, отведенное на извлечение и обработку данных с веб-страницы при помощи BS4 + Requests, составило ~ 28 секунд.
Далее предлагаю переписать скрипт с применением библиотек BS4 + Asyncio.
Второй скрипт:
import json
import time
from bs4 import BeautifulSoup
import datetime
import csv
import asyncio
import aiohttp
books_data = []
start_time = time.time()
async def get_page_data(session, page):
headers = {
'accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/,/*;q=0.8',
'user-agent': 'Mozilla/5.0'
}
url = f'https://www.labirint.ru/genres/2308/?available=1&paperbooks=1&display=table&page={page}'
async with session.get(url=url, headers=headers) as response:
response_text = await response.text()
soup = BeautifulSoup(response_text, 'lxml')
books_items = soup.find(
'tbody', class_='products-table__body').find_all('tr')
for bi in books_items:
book_data = bi.find_all('td')
try:
book_title = book_data[0].find('a').text.strip()
except:
book_title = 'Нет названия книги'
try:
book_author = book_data[1].text.strip()
except:
book_author = 'Нет автора'
try:
book_publishing = book_data[2].find_all('a')
book_publishing = ':'.join([bp.text for bp in book_publishing])
except:
book_publishing = 'Нет издательства'
try:
book_new_price = int(book_data[3].find('div', class_='price').find(
'span').find('span').text.strip().replace(' ', ''))
except:
book_new_price = 'Нет нового прайса'
try:
book_old_price = int(book_data[3].find(
'span', class_='price-gray').text.strip().replace(' ', ''))
except:
book_old_price = 'Нет старого прайса'
try:
book_sale = round(
((book_old_price - book_new_price) / book_old_price) * 100)
except:
book_sale = 'Нет скидки'
try:
book_status = book_data[-1].text.strip()
except:
book_status = 'Нет статуса'
books_data.append(
{
'book_title': book_title,
'book_author': book_author,
'book_publishing': book_publishing,
'book_new_price': book_new_price,
'book_old_price': book_old_price,
'book_sale': book_sale,
'book_status': book_status
}
)
print(f'Обработал страницу {page}')
async def gather_data():
headers = {
'accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/,/*;q=0.8',
'user-agent': 'Mozilla/5.0'
}
url = 'https://www.labirint.ru/genres/2308/?available=1&paperbooks=1&display=table'
async with aiohttp.ClientSession() as session:
response = await session.get(url=url, headers=headers)
soup = BeautifulSoup(await response.text(), 'lxml')
pages_count = int(
soup.find('div', class_='pagination-numbers').find_all('a')[-1].text)
tasks = []
for page in range(1, pages_count + 1):
task = asyncio.create_task(get_page_data(session, page))
tasks.append(task)
await asyncio.gather(*tasks)
async def main():
await gather_data()
cur_time = datetime.datetime.now().strftime('%d_%m_%Y_%H_%M')
with open(f'labirint_{cur_time}_async.json', 'w') as file:
json.dump(books_data, file, indent=4, ensure_ascii=False)
with open(f'labirint_{cur_time}_async.csv', 'w') as file:
writer = csv.writer(file)
writer.writerow(
(
'Название книги',
'Автор',
'Издательство',
'Цена со скидкой',
'Цена без скидки',
'Процент скидки',
'Наличие на складе'
)
)
for book in books_data:
with open(f'labirint_{cur_time}_async.csv', 'a') as file:
writer = csv.writer(file)
writer.writerow(
(
book['book_title'],
book['book_author'],
book['book_publishing'],
book['book_new_price'],
book['book_old_price'],
book['book_sale'],
book['book_status']
)
)
finish_time = time.time() - start_time
print(f'Затраченное на работу скрипта время: {finish_time}')
if __name__ == '__main__':
asyncio.run(main())
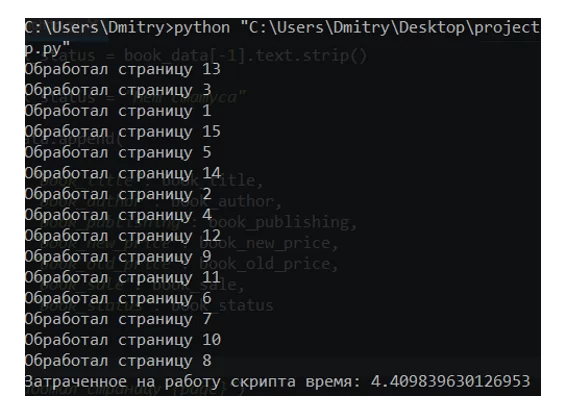
На извлечение и обработку одного и того же объёма данных в данном случае потребовалось всего 4 секунды, а не 28 секунд.
В заключении можно сказать, что применение такого сочетания библиотек, как BeautifulSoup4 и Asyncio, позволит сократить время на сбор и обработку данных при работе с большими данными до 7 раз.