/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
Если коротко, Greenplum — это open source MPP СУБД, основанная на PostgreSQL. Архитектура СУБД укрупненно представляет собой систему, состоящую из n-го количества Segment Host — процессов/серверов, на которых производится хранение и обработка данных, и одного Master Host – процесса/сервера, являющегося точкой входа клиента, который также хранит внутри себя метаданные таблиц и распределяет обработку данных между сегментами. Такая архитектурная модель требует грамотной организации структуры таблиц и выбора способа её хранения для обеспечения эффективной и быстрой обработки данных. В публикации будет рассмотрен вопрос выбора оптимального способа хранения данных витрины.
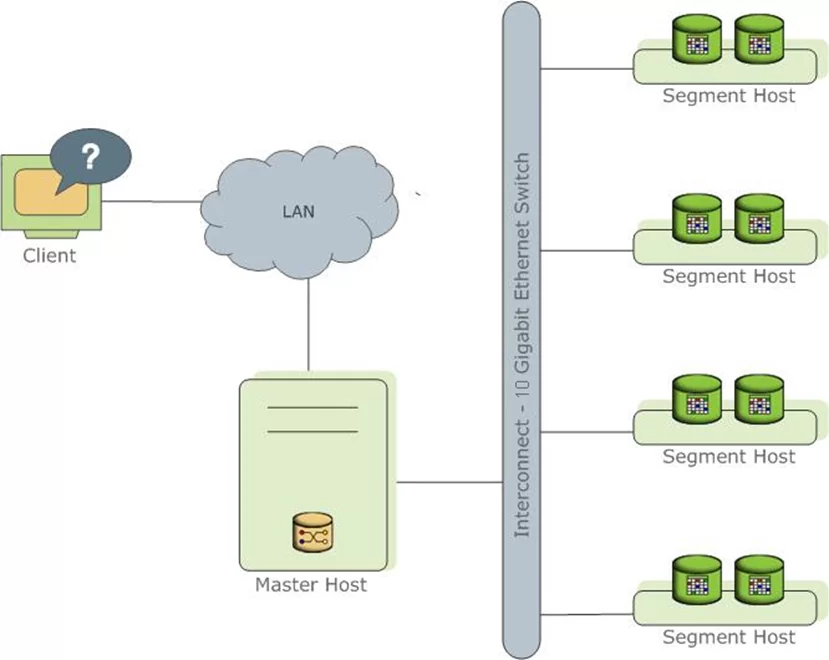
Рис 1. Визуализация архитектуры СУБД Greenplum
Вопрос выбора способа хранения данных для меня встал достаточно остро из-за относительно большого объема анализируемых данных. Кратко опишу набор таблиц витрины и примерное количество строк в них на данный момент:
- Таблица с пользователями маркетплейса (более 4 млн.);
- Корзина товаров (более 150 млн.);
- Покупки пользователей в маркетплейсе (более 40 млн.);
- Таблица с начислениями бонусов за покупки (более 20 млн.)
- И т.д. (суммарно еще около 5-10 млн. строк уходят на перечень продаваемых товаров, различные справочники и другую сопутствующую информацию)
Аналитические запросы, в особенности с объединением этих таблиц, занимают достаточно большое количество времени и ресурсов, что негативно складывается на работе СУБД, коллег и меня в частности. В связи с этим, оптимизация хранения таблиц является одним из основных вариантов оптимизации запросов (вкупе с объяснением того, как эти оптимальные запросы строить, но это уже совсем другая история). Рассмотрим задачу выбора оптимального способа хранения данных подробнее.
Саму задачу можно разделить на следующие этапы:
- Определение формата хранения данных в таблице;
- Определение оптимальной сегментации таблиц;
- Выбор ключей для партицирования и построения индексов (если в этом будет необходимость).
Распишу данные этапы подробнее.
Определение формата хранения данных
Под форматом хранения данных в таблице понимается выбор типа хранения данных и формата сжатия таблицы. В Greenplum существует 2 типа хранения:
- Heap storage – определяет row-oriented тип хранения данных в виде кучи, как и в PostgreSQL. Этот тип хранения наиболее эффективен при OLTP-нагрузках, а именно в тех случаях, когда данные достаточно часто изменяются.
- AOT (append-optimized table) – тип хранения данных, подразумевающий редкие операции обновления. Эффективен при OLAP–нагрузках. Данный тип хранения позволяет создавать таблицы с row-oriented и column-oriented ориентацией таблиц.
- row-oriented – определяет построчное хранение данных в таблице. Row-oriented таблицы эффективны для запросов, подразумевающих выбор всех колонок из таблицы, и в тех случаях, когда данные часто изменяются, или же таблица является относительно небольшой.
- column-oriented – определяет колоночное хранение данных в таблице. Данный подход позволяет оптимизировать SELECT запросы к таблице с выбором ограниченного набора колонок, кроме того, column-oriented таблицы обладают большими возможностями и лучшим сжатием данных, чем row-oriented таблицы.
Для AOT таблиц существует возможность уменьшения хранимого размера данных посредством их сжатия. В Greenplum определены несколько типов сжатия данных: RLE_TYPE, ZLIB, ZSTD, QUICKLZ. Они отличаются друг от друга скоростью чтения и записи данных в таблицу, потреблением ресурсов CPU и RAM, и степенью сжатия данных:
| Тип сжатия | Размах уровней сжатия (min-max) | Комментарий к типу сжатия |
| None | Нет уровней | Сохранение данных без сжатия |
| QUICKLZ | 1 | Обладает достаточно быстрой скоростью чтения и сжатия, но обладает меньшей степенью сжатия (сжимает в среднем до 2-3 раз) |
| ZLIB | 1-9 | Один из первых типов сжатия данных, который лучше сжимает данные, чем QUICKLZ, но при этом затрачивает большее время на сжатие/распаковку данных и обладает большим потреблением CPU |
| RLE_TYPE | 1 – RLE 2 – RLE + ZLIB 1 3 – RLE + ZLIB 5 4 – RLE + ZLIB 9 | Хорошо работает для часто повторяющихся данных, в иных случаях алгоритмы ZLIB и ZSTD будут более эффективны |
| ZSTD | 1-19 | Алгоритм сжатия без потерь, обладает высоким коэффициентом сжатия данных, сохраняя при этом высокую скорость сжатия и распаковки данных, чем ZLIB |
Для каждого из типов, за исключением QUICKLZ, в Greenplum предусмотрена возможность выбора уровня сжатия данных. Чем выше уровень, тем выше степень сжатия данных.
Ниже приведу пример создания таблицы с определением типа таблицы и выбора формата сжатия:
create table orders
(
-- колонки
)
with (appendonly = true, -- Определение того, что таблица AoT
orientation = column, -- Ориентация таблицы
compresstype = zstd, -- Формат сжатия
compresslevel = 9 – Уровень сжатия
)
В рамках моей задачи данные обновляются редко. Кроме того, сами запросы предполагают выбор различных небольших наборов колонок из этой таблицы и построение по ним агрегированной информации о сумме заказов, их составе, количестве клиентов за месяц. В связи с чем, наиболее подходящим типом таблицы является AOT с колоночной ориентацией. Попробую сравнить различные типы сжатия данных на примере таблицы с заказами пользователей:
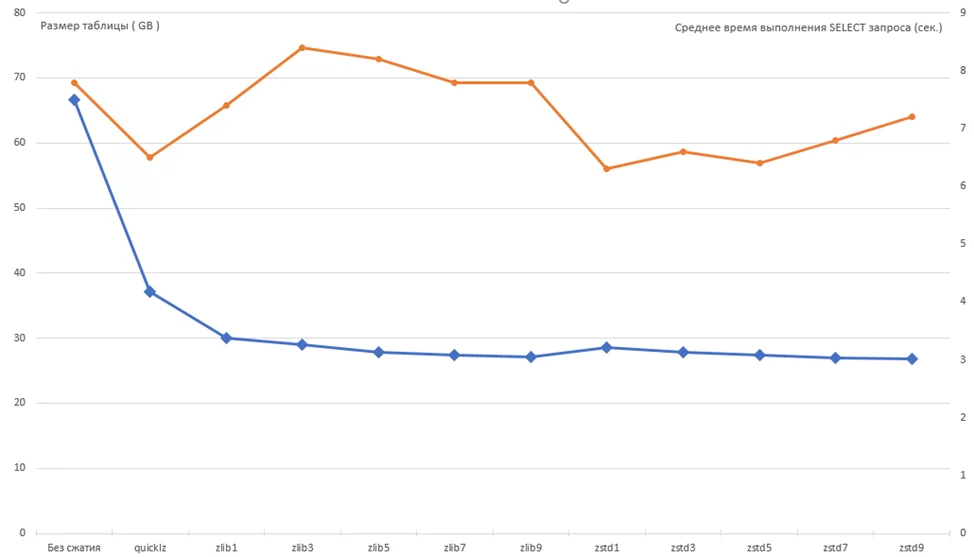
Рис 2. График сравнения типов сжатия QUICKLZ, ZLIB1-9, ZSTD 1-9 по размеру (синяя линия) и по средней скорости выборки данных из таблицы (оранжевая линия).
Как видно из графика выше, сжатие алгоритмом ZSTD с уровнем сжатия, равным 9, для задач длительного хранения подходит, поскольку обеспечивает наилучшее сжатие данных и оптимальное время выполнения среднестатистического запроса к данной таблице. Часто используемые таблицы лучше сжимать алгоритмом QUICKLZ, поскольку скорость чтения, наряду со скоростью компрессии/декомпрессии, намного выше, чем у остальных типов, при этом алгоритм обладает достаточно неплохим сжатием данных, по сравнению с хранением данных без сжатия.
Сегментация таблиц
Следующий этап – определение сегментации таблиц. Данный этап является наиболее важным, поскольку неэффективное распределение данных по сегментам может значительно замедлить скорость выполнения запроса, так как время выполнения запроса напрямую зависит от времени выполнения задачи на самом медленном сегменте.
В Greenplum существует 3 способа сегментации таблиц:
- Distributed replicated
- Distributed by (key)
- Distributed randomly
Остановлюсь на каждом способе поподробнее:
Distributed replicated производит копирование таблицы на каждый из сегментов, что значительно увеличивает итоговый размер таблицы. Данный тип распределения эффективен для хранения небольших таблиц-справочников, которые часто используются для join-ов с другими таблицами, поскольку в таком случае join таблиц производится сразу на сегментах, в связи с чем уменьшаются расходы на передачу данных сети с последующим их перераспределением по всем сегментам.
Distributed by (key) распределяет данные по ключу (колонке из таблицы). Данный способ эффективен в случаях, когда:
- Ключ является уникальным, и позволяет равномерно разделить табличку по сегментам;
- Ключ используется для объединений с другими таблицами, распределенными по такому же ключу (аналогично таблицам с распределением replicated уменьшает затраты ресурсов СУБД);
- Ключ никогда не используется для фильтрации данных.
Distributed randomly – равномерно распределяет данные по каждому из сегментов. Данный вариант эффективен, когда нет подходящего ключа для распределения данных.
Ниже приведен пример запроса с сегментацией по ключу:
create table transactions
(
-- колонки
)
with (appendonly = true, orientation = column, compresstype = quicklz)
distributed by (trans_uuid) – Уникальный ключ транзации, использующийся для сегментации таблицы
Подробнее о сегментации можно прочитать тут и тут.
Партицирование и индексирование таблиц
Следующим способом организации данных на сегментах является партицирование данных. Партицирование данных по своей сути представляет собой логическое разделение данных внутри сегментов, которое позволяет уменьшить количество просматриваемых строк на каждом из сегментов. Всего доступно 3 варианта партицирования данных:
- Партицирование по диапазону значений (PARTITION BY RANGE(KEY));
- Партицирование по определенному списку значений (PARTITION BY LIST(key));
- Партицирование по HASH-значению (PARTITION BY HASH(key)).
Выбор ключа партицирования во многом зависит от того, какие поля используются наиболее часто при фильтрации данных. Стоит также обратить внимание на то, что применение каких-либо функций к партицированной колонке в фильтре может значительно ухудшить скорость обработки данных.
Для того, чтобы оценить целесообразность партицирования таблицы, создам 2 таблицы, первую таблицу партицирую по полю accepted_date_time (orders_wp), а вторую создам без партиций (orders_p):
create table orders_wp
(
-- колонки
)
with (appendonly = true, orientation = column, compresstype = quicklz)
distributed by (o_trans_uuid)
create table orders_p
(
-- колонки
)
with (appendonly = true, orientation = column, compresstype = quicklz)
distributed by (o_trans_uuid)
partition by range (accepted_date_time)
(
partition p2023_01_01 start ('2023-01-01 00:00:00'::timestamp without time zone) end ('2023-01-02 00:00:00'::timestamp without time zone),
partition p2023_01_02 start ('2023-01-02 00:00:00'::timestamp without time zone) end ('2023-01-03 00:00:00'::timestamp without time zone),
...
)
Оценку целесообразности произведу на основе сопоставления плана запроса с выборкой по полю accepted_date_time. Ниже приведены примеры плана выполнения запроса с выборкой по ключу партицирования и выборке данных без партиций:

Выборка массива заказов с фильтрацией по непартицированной таблице

Выборка того же массива заказов с фильтрацией по партиции accepted_date_time
Как видно по планам выполнения запроса, использование партиций в условиях фильтрации значительно уменьшает стоимость выполнения запроса и, как следствие, уменьшает общее время работы запроса.
И последний способ увеличения скорости выполнения запросов в Greenplum — индексирование. Индексирование позволяет ускорить выполнение запросов с высокой селективностью. В Greenplum реализованы 3 вида индексов:
- Btree (сбалансированное дерево) — эффективен при фильтрации данных операторами сравнения, операторами like, between, is null, is not null;
- Bitmap – эффективен для редко читаемых, часто повторяющихся значений (зачастую берут те колонки, количество уникальных значений у которых не превосходит 100 000);
- Gist – особый btree индекс, используемый для редких типов данных, таких как геоданные, текстовые документы, графические файлы и т.п.
Использование индексов в Greenplum должно применяться с осторожностью и в самом крайнем случае, поскольку:
- Индексы занимают место на диске;
- Эффективность индексов заметна только для запросов с высокой селективностью, что зачастую не свойственно аналитическим запросам.
- Greenplum достаточно быстро обрабатывает запросы и без использования индексов.
Пример создания индекса приведен ниже:
create index if not exists app_date on appeal ((created_date::date));
В рамках решаемой мною задачи индексирование является малоэффективным методом повышения скорости выполнения запроса из-за дополнительных расходов на хранение индекса (особенно критично для больших таблиц) и низкой селективности предполагаемых аналитических запросов к таблице.
Используя приведенную информацию, для решения задачи построения витрины данных с отчетами некоего маркетплейса, можно выделить следующий подход к хранению таблиц:
- Выбор AOT таблиц наиболее предпочтителен в случаях, когда данные изменяются достаточно редко. В противном случае наиболее предпочтительны HEAP таблицы.
- Для AOT таблиц выбор колоночной ориентации (column-oriented tables) предпочтителен в случаях, когда в SELECT запросах используются ограниченные наборы колонок в таблице, в противном случае лучше использовать строковую ориентацию (row-oriented tables).
- Обязательное сжатие данных. Для редко читаемых таблиц лучше использовать сжатие ZSTD (наилучший уровень сжатия для построения данных в рамках решения моих задач — 9). Для часто читаемых данных предпочтительнее использовать тип сжатия QUICKLZ.
- Выбор ключа сегментирования таблиц (distribution) должен равномерно распределять данные и, по возможности, входить в ключи, по которым идет объединение (join) таблиц. В случаях же, когда такого ключа в таблице нет, лучше использовать случайное распределение данных (distributed randomly). Исключением являются небольшие справочники, которые можно расшарить по всем сегментам для лучшей производительности (distributed replicated).
- Если есть необходимость, использовать партицирование данных по тем колонкам, по которым наиболее часто фильтруются данные.
Ниже представлены примеры запросов, реализующих описанный выше подход:
- DDL таблицы с транзакциями (заказами) пользователей:
create table orders_parts
(
<Какие-то колонки с типами данных>
)
with (appendonly = true, orientation = column, compresstype = quicklz)
distributed by (order_id) -- уникальный идентификатор заказа
partition by range (accepted_date_time)
(START(‘<дата начала>’) inclusive end (‘<дата окончания>’) exclusive every (INTERVAL ‘<период>’))
;
- DDL таблицы справочника типов операций:
create table oper_types (
oper_type text,
oper_name text
)
with (appendonly = true, compresstype = quicklz)
distributed replicated;
Таким образом, я рассмотрел различные способы хранения таблиц и вывел для себя общие правила создания таблиц для построения витрин данных. На их основе мне удалось успешно сформировать витрину данных и значительно улучшить скорость обработки данных в витрине. Надеюсь, данная публикация была вам полезна.