/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 5 мин.
В этом посте я исследую возможности распознавания срока годности с использованием языка программирования Go и Tesseract OCR. Помимо этого, произведу сравнение этих инструментов с аналогичными решениями на языке Python и оценю их скорость и точность в выполнении данной задачи. Также в качестве бонуса, кратко рассмотрю задачу определения дат на документах.
Почему Go и Tesseract OCR? Все достаточно просто. Во время выполнения моей курсовой работы в университете, мне потребовалось создать REST API на языке Go, в котором одним из главных функционалов — распознавание дат с изображений продуктов. В решении данной проблемы мне помогла замечательная библиотека otiai10/gosseract.
Работа программы
Для извлечения дат из текста на изображении я применил регулярное выражение, которое извлекает даты в формате день.месяц.год или день/месяц/год:
var reDatetime = regexp.MustCompile(`\b(?:0[1-9]|[12][0-9]|3[01])[\.\/](?:0[1-9]|1[0-2])[\.\/](?:\d{4}|\d{2})\b`)Далее фрагмент кода, который поочередно считывает файлы из каталога, извлекает текст и, используя регулярное выражение, находит дату срока годности. Полная версия кода доступна в моем репозитории.
С помощью функции filepath.Walk производится обход всех файлов в указанном каталоге testDataFolder. Для каждого файла считывается содержимое изображения и создается экземпляр клиента client для работы с Tesseract. Затем задается язык распознавания при помощи функции client.SetLanguage.
if err := filepath.Walk(testDataFolder,
func(path string, info os.FileInfo, err error) error {
if info.IsDir() {
return err
}
image, err := os.ReadFile(path)
if err != nil {
return err
}
client := gs.NewClient()
defer client.Close()
if err = client.SetLanguage(langs...); err != nil {
return err
}
if err = client.SetImageFromBytes(image); err != nil {
return err
}Далее, изображение для распознавания устанавливается с помощью функции client.SetImageFromBytes, передавая его в виде байтов. Затем при помощи функции client.Text получаем текст с изображения.
if err = client.SetImageFromBytes(image); err != nil {
return err
}
text, err : client.Text()
if err != nil {
return err
}Полученный текст очищается от символа новой строки с помощью функции strings.Replace. Затем при помощи регулярного выражения в тексте находятся даты.
product := Product{
Filepath: path,
Status: Undefined,
}
defer func() {
results = append(results, product)
}()
cleanText := strings.Replace(text, "\n", " ", -1)
matches := reDatetime.FindAllString(cleanText, -1)Если количество найденных дат равно нулю, то это означает, что срок годности не был обнаружен, и данный случай добавляется в список undefined. В противном случае производится обработка каждой найденной даты.
Найденные даты преобразуются в структуру time.Time. При этом, если год указан в двухзначном формате, то я добавляю тысячную и сотую часть текущего года к этой дате. После этого преобразованные даты добавляются в список dates.
if len(matches) == 0 {
undefined = append(undefined, product)
return nil
}
dates := make([]time.Time, 0)
for _, match := range matches {
match = strings.Replace(match, "/", ".", -1)
pieces := strings.Split(match, ".")
if len(pieces[2]) == 2 {
pieces[2] = strconv.Itoa(time.Now().Year())[:2] + pieces[2]
}
converted := make([]int, len(pieces))
var err error
for i, p := range pieces {
converted[i], err = strconv.Atoi(p)
if err != nil {
return err
}
}
date := time.Date(
converted[2],
time.Month(converted[1]),
converted[0],
0, 0, 0, 0,
time.UTC,
)
dates = append(dates, date)
}Далее я определяю дату — срок годности, как правило, на этикетках располагают 2 даты: изготовления и срока годности. Срок годности всегда больше даты изготовления, поэтому если удалось определить 2 даты я выбираю наибольшую из них.
product.Status = Invalid
switch len(dates) {
case 1:
product.ExpirationDate = dates[0]
case 2:
if dates[0].After(dates[0]) {
product.ExpirationDate = dates[0]
} else {
product.ExpirationDate = dates[1]
}
}
return nilПосле преобразований дат, структура product с информацией о файле и его статусом добавляется в список results.
Разобравшись с кодом, можно переходит к его результатам и сравнению с аналогичным алгоритмом на Python.
Результат и сравнение с Python
Применив вышеописанный код к набору из 300 текстовых изображений, обнаружил, что из‑за ограниченной точности распознавания текста библиотекой Tesseract, только 218 из 300 дат были успешно определены. Из этих 218 дат, 183 были распознаны корректно, что указывает на эффективность реализованного алгоритма. Однако оставшиеся 35 даты были некорректно распознаны из‑за ошибок в распознавании текста.
Применение данного алгоритма на компьютере с процессором AMD Ryzen 5 3350G занимало в среднем 8 минут. Это время охватывает процесс обработки всех 300 текстовых изображений, включая чтение файлов, извлечение текста, распознавание дат с использованием регулярного выражения и последующую обработку полученных результатов.
Также был реализован аналогичный алгоритм на языке Python с использованием библиотеки pytesseract. В отличие от алгоритма на языке Go, время выполнения этого алгоритма составило в среднем около 4,5 минут, что значительно быстрее по сравнению с предыдущим вариантом. Однако, несмотря на более быстрое время выполнения, алгоритм смог успешно распознать даты только в 113 изображениях из 300. Это свидетельствует о более низкой точности распознавания текста.
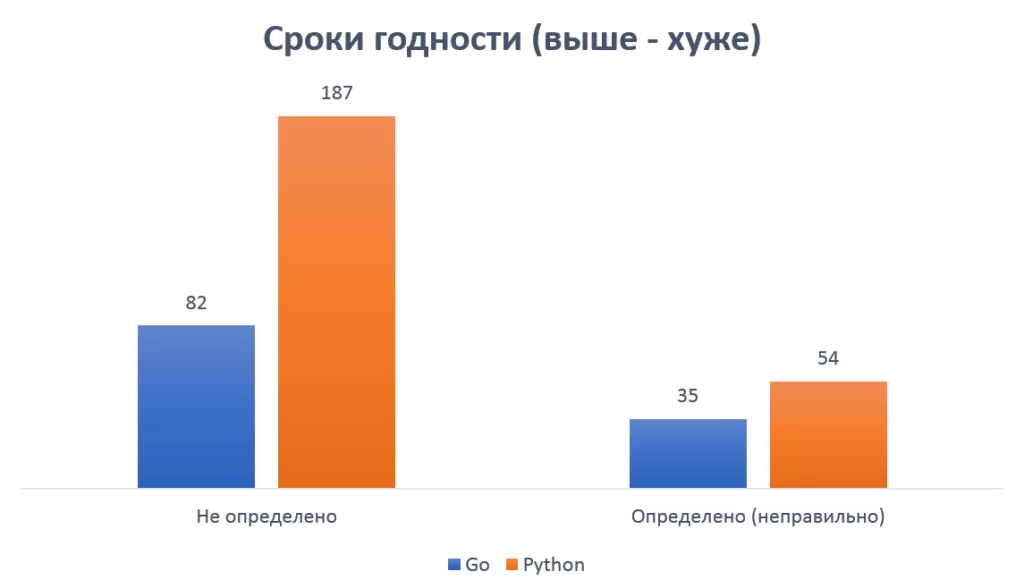
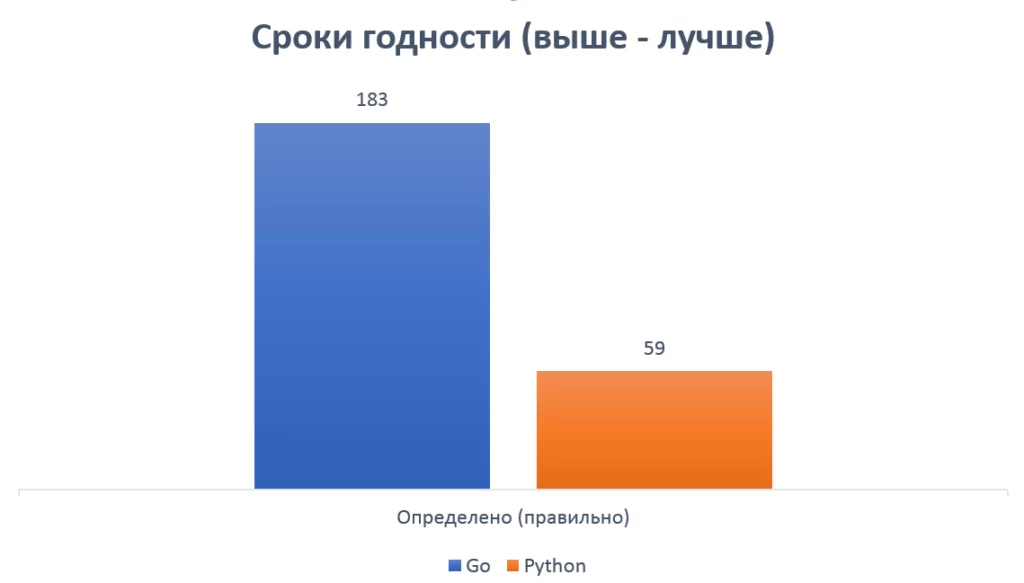
Из результатов сравнения двух алгоритмов для распознавания дат на изображениях, реализованных на языках Go и Python с использованием соответствующих библиотек, видно, что время выполнения и точность распознавания имеют определенные различия.
Важно отметить, что если оба алгоритма будут переработаны для обработки файлов параллельно, то разница в скорости выполнения между ними, вероятнее всего, будет не столь существенной.
Бонус: даты на документах
Как обещал, в качестве бонуса решил применить разработанный алгоритм для распознавания дат на изображениях документов. Для тестирования использовался следующий пример.

Процесс обработки данного изображения с помощью немного измененного алгоритма позволил выявить две даты, соответствующие заданному регулярному выражению: 18.05.2000 и 20.04.2000. Затем, применив алгоритм к реальным документам, которые имел под рукой в виде сканов, я получил ожидаемые результаты во всех случаях. Это позволяет сделать вывод, что при наличии хорошо сделанного скана документа определение дат становится достаточно простым процессом.
Итог
В конце хочется отметить, что даже не смотря на результат сравнения Go и Python, лучше для подобных задач использовать Python, так как, для него намного больше инструментов (keras‑ocr, EasyOCR) для обработки текста с изображений, которые работают намного лучше и способны дать более точные результаты, чем Tesseract OCR.