/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 6 мин.
В начале статьи расскажу о возможностях программы, а в конце будет ссылка на репозиторий. Программа запускается везде, где есть JVM (Java Virtual Machine), имеет простой и понятный интерфейс.
Итак, какую программу будем собирать? Ту, которая умеет:
- Писать, хранить, редактировать SQL запросы;
- Создавать подключения к различным СУБД;
- Исполнять SQL запросы;
- Выгружать результаты отработки запросов в Excel, обходя его ограничение в 1 млн строк (выборка автоматически разбивается по excel листам);
- Разграничивать роли пользователей (пользователь/администратор);
- Также программа имеет собственный механизм регистрации/авторизации, логирования действий пользователей;
- Для примера я также приложил сервер СУБД Postgres, развернутый через Docker, чтобы описанная программа запускалась «из коробки».
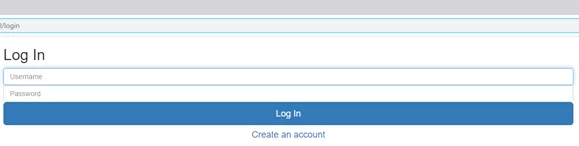
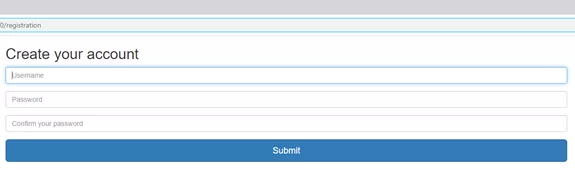
Итак, стартовое окно авторизации/регистрации нового пользователя выглядит так:
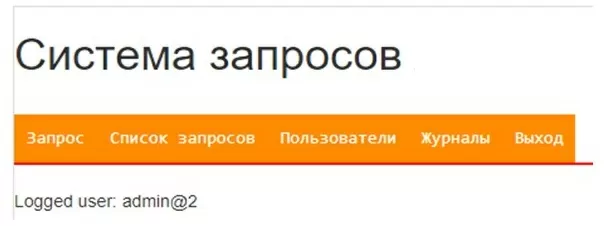
Начальное окно с пунктами меню выглядит так:
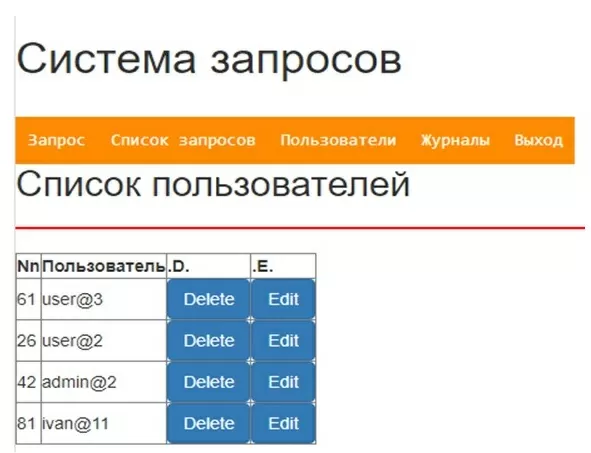
С правами “ADMIN” можно увидеть список пользователей, редактировать их или удалить
Далее подробнее остановлюсь на каждом разделе меню и расскажу о его возможностях.
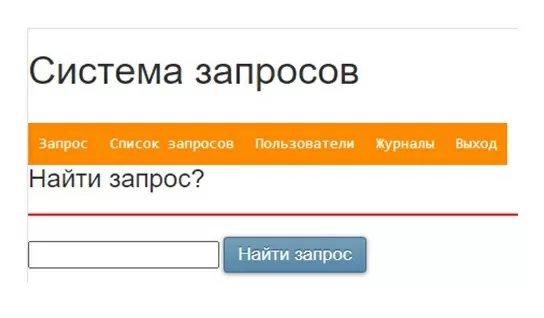
Пункт меню «Запрос». Здесь можно найти по наименованию «запрос» в списке запросов.
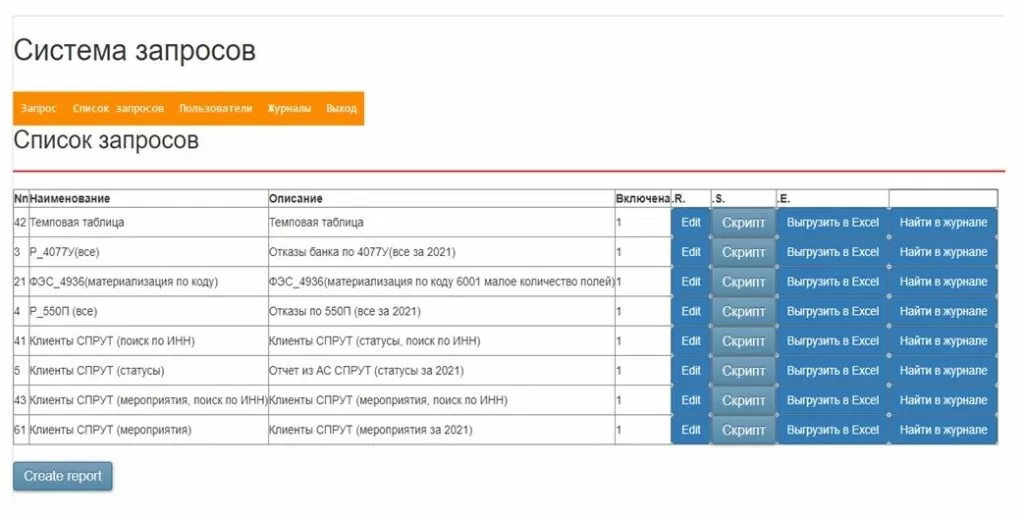
«Список запросов». Запросы, как я сказал ранее, можно редактировать. Возможно редактировать сам скрипт запроса, выгрузить его в Excel, найти в «Журнале» готовые выгрузки запроса. О «Журнале» расскажу далее.
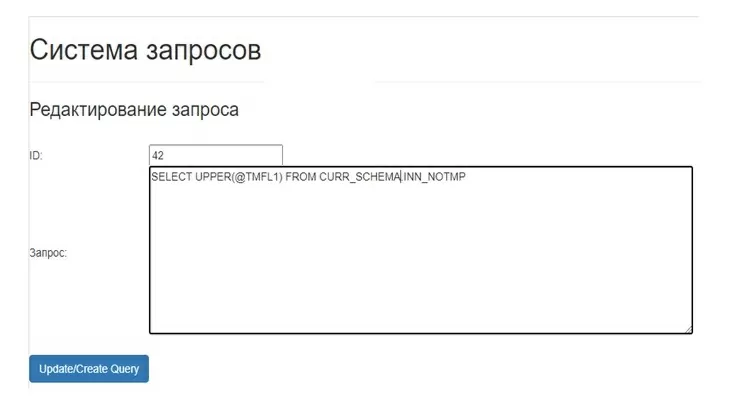
Если в тексте SQL запроса присутствует макрос подстановки (@TMFL1), то в это место подставляется построчный текст, загруженный из txt-файла. Программа попросит загрузить файл:
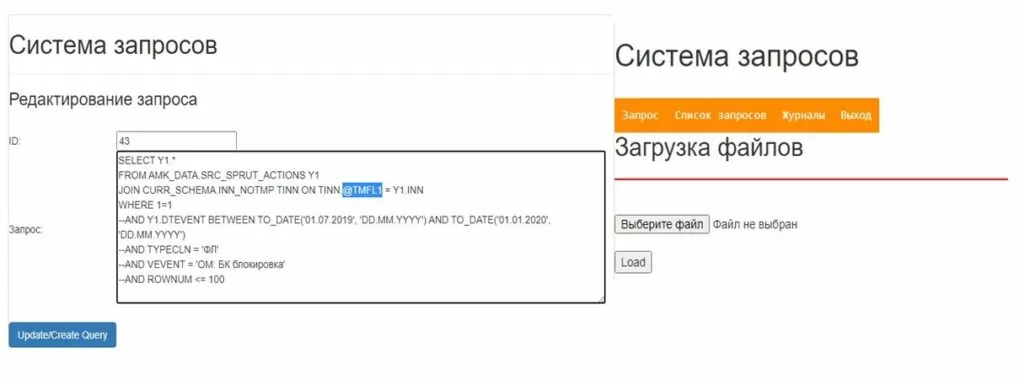
«Журнал запросов». В Журнале хранятся исполненные запросы, и журнал также позволяет экспортировать готовый отчет Excel пользователю.
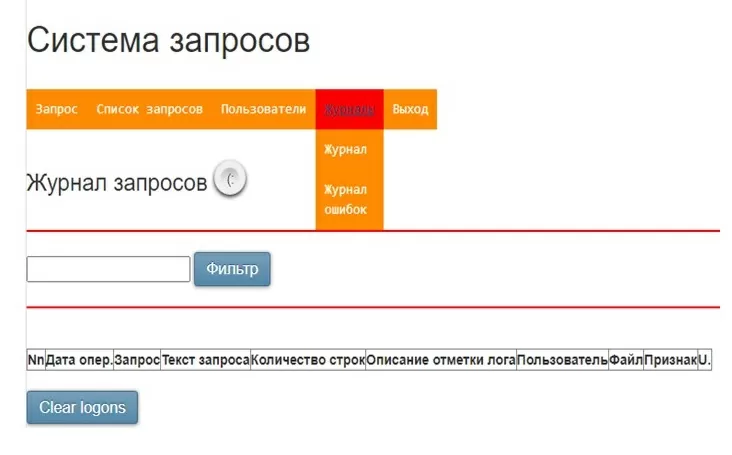
Возможен поиск готовых отчетов в журнале:
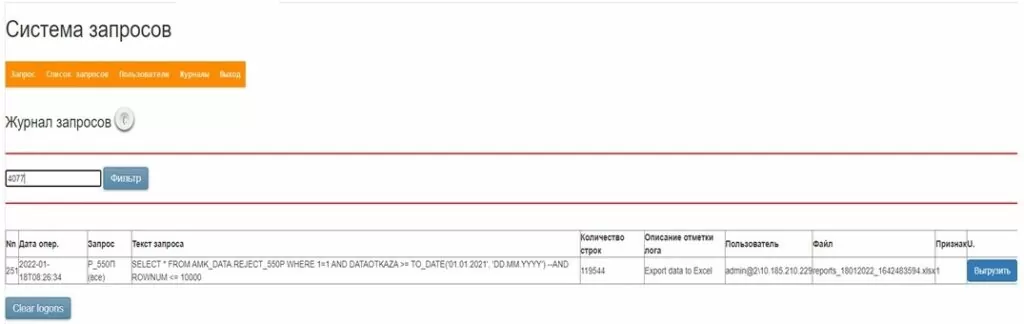
«Выгрузка пользователю». Когда отчет (файл Excel) сформирован в журнале появляется кнопка «Выгрузить».

Теперь перейдем к описанию некоторых частей кода программы.
Для работы c базами данных, системой доступа, REST API в pom.xml я использовал следующие зависимости.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.thymeleaf.extras</groupId>
<artifactId>thymeleaf-extras-springsecurity5</artifactId>
<version>3.0.4.RELEASE</version>
</dependency>
Работу приложения с Excel реализовывал так:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.0.0</version>
</dependency>
Для работы с СУБД Oracle. Зависимости в pom.xml для СУБД Oracle.
<dependency>
<groupId>com.oracle.ojdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>19.3.0.0</version>
</dependency>
<dependency>
<groupId>com.oracle.ojdbc</groupId>
<artifactId>orai18n</artifactId>
<version>19.3.0.0</version>
</dependency>
Файл с настройками application.properties Для работы с СУБД Oracle
#===========oracle
spring.datasource.driverClassName=oracle.jdbc.OracleDriver
spring.datasource.url=jdbc:oracle:thin:@curr_server.ru:1526/curr_bd
spring.datasource.shema=CURR_SCHEMA
spring.datasource.username=User_name
spring.datasource.password=************
#=====jpa
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.Oracle8iDialect
#==Схема по умолчанию
spring.jpa.properties.hibernate.default_schema = CURR_SCHEMA
#spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.SQLServer2012Dialect
spring.jpa.hibernate.ddl-auto=none
Легко перейти на любую другую БД изменив настройки и добавив соответствующе драйвера (зависимости в pom).
В БД создаем необходимые таблицы.
Таблица для списка отчетов:
-- Create table
create table REPORTLIST
(
id NUMBER default "CURR_SCHEMA"."SEQ_REP".nextval not null,
namequery VARCHAR2(1000),
description VARCHAR2(2000),
repenabled NUMBER
)
Таблица для хранения SQL-запросов
-- Create table
create table REPORTSCRIPT
(
id NUMBER default "CURR_SCHEMA"."SEQ_SKRP".nextval not null,
script VARCHAR2(4000),
idreport NUMBER
)
Таблица для хранения журнала запросов.
-- Create table
create table LOGREPORT
(
id NUMBER default "CURR_SCHEMA"."SEQ_LOGREP".nextval not null,
datein DATE,
procname VARCHAR2(1000),
script VARCHAR2(4000),
nrowcount NUMBER,
logtext VARCHAR2(1000),
vusername VARCHAR2(100),
vfileout VARCHAR2(200),
nflagout NUMBER
)Ниже приведу пример использования классов в приложении:
Для работы со списком отчетов – класс ReportsEntity:
@Entity
@Table(name = "REPORTLIST", schema = "CURR_SCHEMA")
public class ReportsEntity {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "report_sequence")
@SequenceGenerator(name = "report_sequence", sequenceName = "SEQ_REP", schema = " CURR_SCHEMA", initialValue = 1, allocationSize = 1)
@Column(name="ID")
private Long id;
@Column(name="NAMEQUERY")
private String nameQuery;
@Column(name = "DESCRIPTION")
private String description;
@Column(name = "REPENABLED")
private int enableReport;
Для работы с запросами – класс QueryEntity:
@Entity
@Table(name = "REPORTSCRIPT", schema = "CURR_SCHEMA")
public class QueryEntity {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "script_sequence")
@SequenceGenerator(name = "script_sequence", sequenceName = "SEQ_SKRP", schema = " CURR_SCHEMA ", initialValue = 1, allocationSize = 1)
@Column(name="ID")
private Long id;
@Column(name="SCRIPT")
private String query;
//@OneToOne(mappedBy = "queryEntity", cascade = CascadeType.ALL)
@Column(name = "IDREPORT")
private Long idReport;
Сервис для выгрузки отчетов в Excel. Для выгрузки данных в Excel написан отдельный класс с учетом формирования файлов с большим объемом данных. Для ограничения расхода памяти, при очень больших объёмах данных использую разбивку выгрузки по 2000+- записей (строка ((SXSSFSheet) sheet).flushRows(2000);).
@Service
public class ExportServiceImpl implements ExportService {
private static final Logger log = LoggerFactory.getLogger(ExportServiceImpl.class);
private final ResultSetToExcelLoc resultSetToExcelLoc;
private long countRow;
private String repositoryPath;
@Autowired
public ExportServiceImpl(ResultSetToExcelLoc resultSetToExcelLoc) {
this.resultSetToExcelLoc = resultSetToExcelLoc;
this.repositoryPath = this.resultSetToExcelLoc.getRepositoryPath();
}
@Override
public void exportExcelLoc(ResultSet rs, String filename) {
log.info("=Start execution of scheduled task");
try {
log.info("====start export excel====");
this.repositoryPath = this.resultSetToExcelLoc.getRepositoryPath();
log.info("==repositoryPath==" + this.repositoryPath);
resultSetToExcelLoc.setResultSet(rs);
//
resultSetToExcelLoc.writeIntoExcelSXSSFMulti(filename);
//count rows
countRow = resultSetToExcelLoc.getiRow();
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
log.error(e.getMessage(), e);
}
log.info("=Complete execution of scheduled task");
}
@Override
public long getCountRow() {
return countRow;
}
@Override
public String getRepositoryPath() {
return repositoryPath;
}
}
Логирование. Все логи собираются в log-файл (ежедневно в новый файл, название файла с датой). Файлы с логами хранятся на сервере в папке Logs.
<appender name="File" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>.\Logs\applic.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>.\Logs\applic_%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>15</maxHistory>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{dd.MM.yyyy HH:mm:ss.SSS} [%thread] %-5level %logger{20} - %msg%n</pattern>
</encoder>
</appender>
Ввиду того что код программы объемен – я разместил его в GitHub – ссылка.
В репозитории проект настроен на работу с БД PostgreSql, которая разворачивается через Docker
Буду рад, если моя программа будет полезна при решении ваших задач.