/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
В настоящее время все больше и больше развиваются технологии анализа программного кода. Разработано большое количество различных библиотек, методов и подходов для выявления уязвимостей и «узких» мест в коде. Это может быть нахождение лексических ошибок, переполнения буфера, уязвимостей форматной строки, использования открытых лицензий и прочих проблем. Для подобных случаев существует так называемая технология Code Mining, которая является своего рода автоматизированным решением для поиска аномалий программным путем в коде разработчика.
С целью «прокачки» технологии Code Mining мы приняли участие в соревновании DataScienceChallenge. Участникам данного соревнования предстояло провести анализ 3 риск-стратегий (кредитного потенциала кредитных карт; кредитного потенциала потребительских кредитов; стратегии принятия решения по участникам, объектам недвижимости и контрагентам ипотечной заявки) и выявить их уязвимости (возможные ошибки в логике кода, неисполняемые части, и др.), а также определить чувствительность и взаимосвязи переменных.
Для поиска отклонений были использованы следующие подходы:
- Динамический и статический анализ кода (анализ кода, производимый без реального выполнения исследуемых программ).
- Анализ схожести (clone detection) и заимствований.
- Оценка качества исходного кода.
- Анализ код-артефактов (комментарии, пул-реквесты, код-ревью, объем рефакторинга и т.д.).
В ходе анализа каждого отклонения определялись возможные причины по их возникновению:
- Некачественное форматирование кода.
- Низкое покрытие тестами.
- Немодульная архитектура.
- Сложность кода.
- Отсутствие документации.
- Дубликаты и заимствование.
А теперь подробнее расскажем о статическом анализе кода.
Инструменты, которые позволяют ускорить данный процесс, существуют уже достаточно давно, например, статические анализаторы кода, такие как Coverity и PVS-Studio.
Статический анализатор кода — это ПО, которое проводит анализ программы без её реального выполнения. Инструменты статического анализа проводят более глубокую проверку исходного кода, чем это делает компилятор, который обычно находит только синтаксические ошибки.
Алгоритм работы инструментов заключается в следующем:
- Входными данными является либо сам исходный код, либо его представление в байт-коде (если оно существует), в то время как его выходные данные зависят от цели, которую мы стремимся достичь.
- Исходный код преобразуется в специальную модель для дальнейшего анализа (AST, семантическая информация и так далее).
- Применяя к модели набор диагностических правил, в основе которых лежат различные методологии, определяются дефектные места.
- Все полученные предупреждения сохраняются в удобный формат.
- Остаётся только изучить отчёт и исправить все дефектные места.
Основной profit, который мы получаем при использовании статического анализа – это безусловно выявление в том числе критичных ошибок в анализируемых разработках, которые могут повлечь для компании возникновение серьезных проблем (например, негативного клиентского опыта, потерю деловой репутации, финансовых потерь и других). Приведем несколько примеров выявленных критичных ошибок:
- Многократное определение одной и той же функции с одним и тем же набором параметров в одном файле.

2. Вызов функции с недостаточным числом заданных аргументов.

Данное явление связано с нехваткой аргументов в вызове функции, что приводит к аварийной остановке работы процесса. Ошибочный вызов функции:
if boo.ncl_router(data): Определение функции:
def ncl_router(Local_Call_3, Local_Call_4,
Local_Calc_avg_conf_income_was_changed):
)
Использование статических анализаторов, которые имеют базу знаний о различных паттернах (размещена в открытых источниках в Интернете), описывающих наиболее часто встречающие проблемные зоны, помогло нам выявить ошибки в коде, о существовании которых мы и не догадывались. На картинке ниже отражена часть выявленных ошибок.
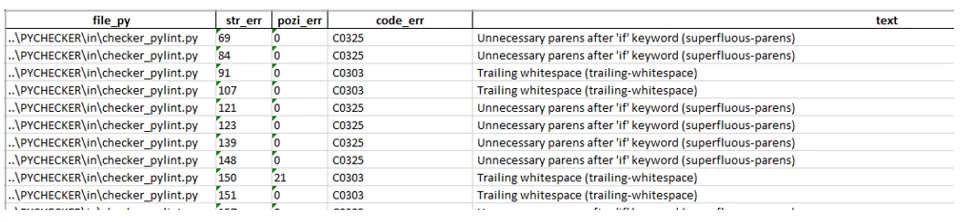
Одним из популярных анализаторов-линтеров (подтип статического анализатора кода, предназначенный для обнаружения потенциальных ошибок, ошибок, злоупотреблений и стилистических проблем) кода для Python является Pylint. Этот мощный, гибко настраиваемый инструмент для анализа кода Python отличается большим количеством проверок и разнообразием отчетов. Также pylint выполняет проверку стиля, чтобы убедиться, что код соответствует стандарту pep8. Анализ файлов программного кода выдает подробный отчет, состоящий из списка найденных в ходе анализа недочетов, статистических данных, представленных в виде таблиц, и общей оценки кода. Для вывода подробного отчета можно использовать ключ командной строки
--reports=yPylint использует маркировку проблемных мест в коде:
- [R]efactor — требуется рефакторинг.
- [C]onvention — нарушено следование стилистике и соглашениям.
- [W]arning — потенциальная ошибка.
- [E]rror — ошибка.
- [F]atal — ошибка, которая препятствует дальнейшей работе программы.
При каждом запуске pylint выводит оценку качества кода по десятибалльной шкале. Также позволяет по каждой ошибке запросить более подробную справку, используя название правила из конца строки с ошибкой или команду
--help-msg=missing-docstring
--help-msg= W0311или, например, игнорировать как отдельные ошибки, так и все ошибки из категорий
--disable=W0311,C0301Pylint настраивается через файл .pylintrc в корне проекта. Создать дефолтный файл конфигурации можно через консольную команду
pylint.exe --generate-rcfile > .pylintrcСозданный файл содержит все поддерживаемые pylint опции для текущей версии с довольно подробными комментариями. Также можно использовать заранее подготовленный файл из интернета (размещены в свободном доступе).
Pylint поддерживает плагины для расширения базовой функциональности, позволяющие, например, вводить дополнительные проверки кода, комментариев, использовать его совместно с иными фреймворками, и т.п. Для статического анализа кода проекта был создан класс с использованием библиотеки pylint, на вход которого подается директория с кодом, а на выходе получаем excel-файл с отчетом об ошибках:
# -*- coding: utf-8 -*-
from pylint.lint import Run
from pylint.reporters.text import TextReporter
import os
import fnmatch
from collections import Counter
import re
import pandas as pd
import openpyxl
class WritableObject(object):
def __init__(self):
self.content = []
def write(self, line):
#
self.content.append(line)
def read(self):
#
return self.content
#
class CheckerPylint(object):
SCORING_VALUES = {
'E':5,
'W':4,
'R':3,
'C':2,
'I':0.1,
}
dirname = os.path.dirname(os.path.realpath('__file__'))
#
def __init__(self, path_py, file_rep_excel):
self.contetn_py = [path_py]
self.total_counter = Counter()
self.full_sintax = []
self.name_file = file_rep_excel
self.df_sintax_stra = pd.DataFrame()
#
def find_files(self, directory, pattern):
"""
Find files from pattern
"""
for root, dirs, files in os.walk(directory):
for basename in files:
if fnmatch.fnmatch(basename, pattern):
filename = os.path.join(root, basename)
yield filename
#
def run_pylint(self, filename):
"""
Run pylint for py file
"""
#args = ['-r', 'n', '--rcfile=pylintuva.pylintrc', '--disable=W0311,C0301',]
args = ['-r', 'n', '--rcfile=.pylintrc', '--disable=C0301',]
pylint_output = WritableObject()
Run([filename] + args, reporter = TextReporter(pylint_output), exit=False)
lines = []
for line in pylint_output.read():
if not line.startswith('*') and line != '\n':
lines.append(line)
return lines
#
def parse_pylint_outpyt(self, pil_output):
"""
Parse report pylint
"""
lookup_key = '-{10,}|Your code'
cyr_arr = []
for text in pil_output:
if(len(re.findall(r''+ lookup_key, str(text))) <= 0):
stripped_out = [x for x in text.split() if x != '']
if stripped_out:
cyr_arr.append(stripped_out[1])
stripped = [x[0] for x in cyr_arr]
counter = Counter(stripped)
return counter
#
def parse_pylint_rep(self, pil_output):
"""
Parse report pylint
"""
lookup_key = '-{10,}'
cyr_arr = []
for text in pil_output:
if(len(re.findall(r''+ lookup_key, str(text))) <= 0):
text = re.sub(r'^[A-Za-z]:', '..', text)
#stripped_out = [x for x in re.split(r':|: ', text)]
stripped_out = list(re.split(r':|: ', text))
if stripped_out:
cyr_arr.append(stripped_out)
return cyr_arr
def print_scoring(self):
"""
Scoring error pylint
"""
score_val = 0
statement = 0.01
print(self.total_counter)
for count, stat in enumerate(self.total_counter):
koef = self.SCORING_VALUES[stat]
statement += self.total_counter[stat]
score_val += self.total_counter[stat]*koef
print('' + str(score_val) + ' / ' + str(statement))
#evaluation=10.0 - ((float(score_val) / statement) * 10)
evaluation=10.0 - (float(score_val) / statement)
print('========Scoring :=' + str(evaluation))
def run_checker_pyfiles(self):
"""
Run py files to pylint
"""
self.full_sintax = []
self.total_counter = Counter()
for path_tx in self.contetn_py:
python_files = self.find_files(path_tx, '*.py')
for python_file in python_files:
print("=====file " + python_file)
pil_output = self.run_pylint(python_file)
#
rep_pylint = self.parse_pylint_rep(pil_output)
if(len(rep_pylint) > 0):
for curr_rep in rep_pylint:
print(curr_rep)
if(len(re.findall(r'Your code', str(curr_rep))) != 0):
print(curr_rep)
continue
self.full_sintax.append(curr_rep)
# print error
self.print_rep_error(pil_output)
# scoring my
counter = self.parse_pylint_outpyt(pil_output)
self.total_counter += counter
#
def print_rep_error(self, pil_output):
"""
Print report error
"""
lookup_key = 'E0001:|E0102:|E1120:|E0401:|E1101'
for text in pil_output:
if(len(re.findall(r''+ lookup_key, str(text))) != 0):
print(text)
#
def get_max_len(self, a_list=[]):
"""
Max len fields list
"""
max_lm = 0
for fgg in a_list:
if(max_lm < len(fgg)):
max_lm = len(fgg)
return max_lm
def export_to_excel(self):
"""
Export to excel
"""
try:
if(self.get_max_len(self.full_sintax) > 5):
self.df_sintax_stra = pd.DataFrame(self.full_sintax, columns=['file_py', 'str_err', 'pozi_err', 'code_err', 'text', 'Unkn',])
else:
self.df_sintax_stra = pd.DataFrame(self.full_sintax, columns=['file_py', 'str_err', 'pozi_err', 'code_err', 'text',])
self.df_sintax_stra.to_excel(self.name_file, index=False)
except Exception as ex:
print(ex)
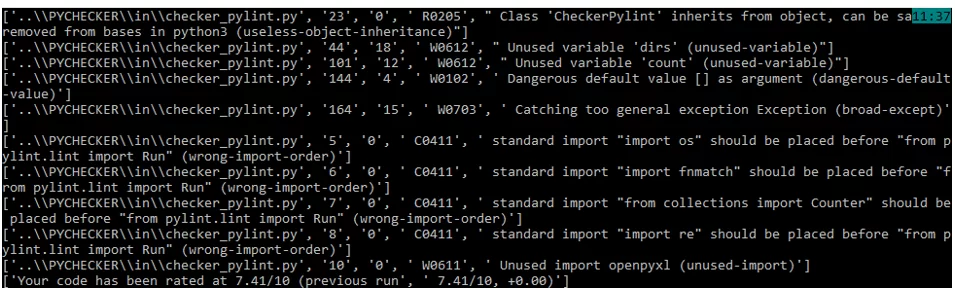
Время отработки проекта и формирование отчета с помощью pylint занимает считанные секунды, что в разы меньше, чем при ручном разборе.
На картинке ниже отражен лог работы класса.
Резюме
Использование статических анализаторов для «Code Mining» исходного кода однозначно целесообразно для любого проекта. Они значительно сокращают время, потраченное на код-ревью, так как отлавливают тривиальные ошибки автоматически, уменьшают вероятность появление критических ошибок, позволяют контролировать общее качество кода, строго следовать определённому стандарту разработки.