/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Потенциал использования Computer Vision для аудита невозможно переоценить. Существует множество задач, где в силу ограниченности человеческого ресурса приходится жертвовать либо охватом (когда вместо всех ВСП анализируются лишь часть), либо временным интервалом проверки (исследование недельного архива видеозаписей вместо квартального). В этой статье я расскажу, как модель, собранная из нескольких нейронных сетей, позволила автоматически, без огромных затрат человеческого ресурса, выявлять случаи, когда сотрудники оставляют рабочие места без блокировки ПК, или даже позволяют работать коллегам под своими учетными данными.
В наше время, когда цифровизация уже прочно вошла во все сферы жизни человека, вопрос защиты личных цифровых данных становится всё более актуальным. Однако, несмотря на множество правил и рекомендаций, очень часто люди достаточно легкомысленно относятся к выполнению требований кибербезопасности и сохранности принадлежащих им и их организации данных. Мне предстояло выявить подобные случаи, когда сотрудники специально или непреднамеренно допускали возможность использования их учетных данных третьими лицами.
В моём распоряжении имелись кадры с камер наблюдения с разметкой, где непосредственно находятся конкретные рабочие места, а также выгрузка данных с Active Directory о времени блокировки и разблокировки компьютера. Мне предстояло найти случаи, когда во время активной сессии одного человека за компьютером оказывался другой человек.
Фактически, речь пойдет о такой задаче CV, как Re-Identification (ReID). Если сказать кратко, то эта задача сводится к повторной идентификации одного и того же объекта в разное время или в разных местах. В качестве объекта может использоваться что угодно, например, автомобили, дикие животные, объекты архитектуры, люди и другие сущности, обладающие идентичностью.
Для того, чтобы решить эту сложную задачу, я декомпозировал ее на несколько простых задач. Получилось 4 основных этапа, на каждом из которых остановимся подробнее:
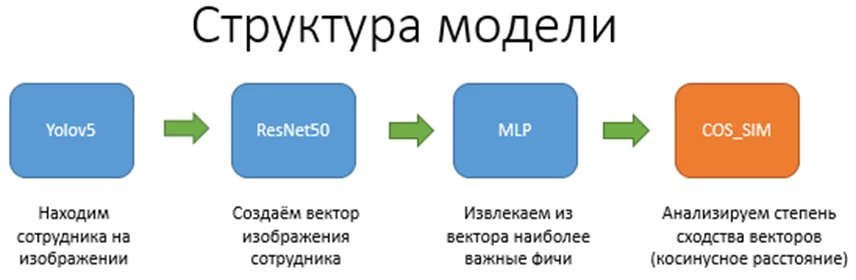
Начальным триггером для запуска последующих расчётов служит присутствие в рабочей зоне человека, поэтому первым делом я сфокусировалися на решении задачи поиска людей в ранее размеченных зонах интереса:

С этой задачей из коробки вполне легко справляется достаточно популярная модель Yolov5s. Данная модель даже без дополнительного обучения способна неплохо распознавать до 80 классов, среди которых есть и человек. Выяснить, на сколько область найденного на изображении человека соответствует одной из ранее размеченных зон интереса позволят простая функция пересечения прямоугольников:
# функция для расчета входит ли в зону интереса найденный объект
def comp_overlaps(interes_zone, obj_zone):
interes_zone = np.array(interes_zone).reshape(-1)
obj_zone = np.array(obj_zone).reshape(-1)
x1 = np.maximum(interes_zone[0], obj_zone[0])
x2 = np.minimum(interes_zone[2], obj_zone[2])
y1 = np.maximum(interes_zone[1], obj_zone[1])
y2 = np.minimum(interes_zone[3], obj_zone[3])
intersection = np.maximum(x2 - x1, 0) * np.maximum(y2 - y1, 0)
obj_area = (obj_zone[2] - obj_zone[0]) * (obj_zone[3] - obj_zone[1])
return intersection / obj_area
Функция возвращает число от 0.0 до 1.0. Чем ближе значение к единице, тем большая площадь контура найденного человека входит в зону интереса. Выбор границы зависит от качества разметки зон, угла камеры и прочих особенностей. В нашем случае в качестве такой границы я выбрал 0.8 (т.е. 80%).
Вторым шагом, согласно ранее представленной структуры модели, является преобразование имеющегося изображения человека в вектор. Для этого была задействованная другая, не менее известная модель, ResNet.
Поскольку эта модель является классификатором изображений, она изначально не предназначена для формирования вектора, её выводом является метка о принадлежности к тому или иному классу. Но это легко исправить «срезав» у модели последний слой:
# Замена softmax на identity function
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
trunk = torchvision.models.resnet50(pretrained=True)
trunk.fc = c_f.Identity()
trunk = nn.DataParallel(trunk.to(device))
Третьей компонентой предлагаемой модели является простая MLP-модель из входного и выходного слоя, задача которой сжать большой вектор, получаемый на выходе ResNet до более компактного, но без потери необходимой информации. Проще говоря, роль данного узла состоит в том, чтобы извлечь из вектора только те признаки, которые отличают на изображении одного человека от другого:
# Модель эмбеддера. Входной слой задаётся числом выходных параметров ResNet* модели, выходной - подбирается
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
trunk_output_size = trunk.fc.in_features
embedder = torch.nn.DataParallel(MLP([trunk_output_size, emb_size]).to(device))
В отличие от модели Yolov5s, которая уже из коробки хорошо умеет находить людей в кадре, модели ResNet* и MLP требуется обучить под конкретную задачу. Но не просто обучить, а «хитро» обучить. Дело в том, что при классическом обучении классификатор совершенно не заботится о том, чтобы находить сходства между объектами целевого класса. Я же заинтересован, чтобы наш классификатор решал задачу не только классификации, но и кластеризации. Это наделило бы выходные вектора таким свойством, что, к примеру, вектора одного и того же человека в n-мерном пространстве были бы близки друг к другу, а разных – далеки. Подобную задачу решает техника MetricLearning, примеры применения которой можно посмотреть тут. Для лучшего понимания проиллюстрируем, чем именно отличается классический подход обучения классификатора от «хитрого»:
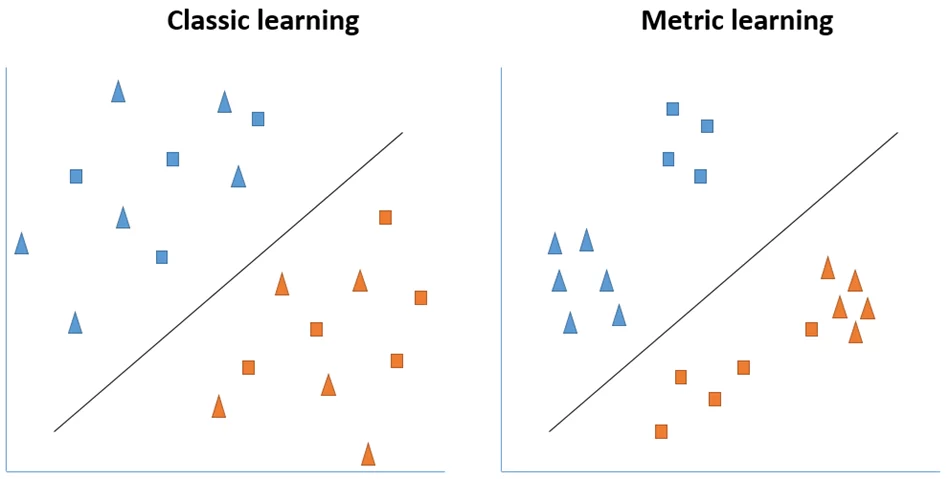
Как видно, в обоих случаях решается задача классификации, но в случае применения техники Metric Learning наблюдается группировка в разрезе подклассов. На практике это приводит к тому, что, сравнивая косинусное расстояние между двумя векторами, можно судить, принадлежат ли эти вектора одному и тому же сотруднику в кадре или нет. Собственно, четвертый этап, это и есть блок сравнения текущего вектора с опорным с помощью косинусного расстояния.
Я упомянул опорный вектор, но что это и как его получить? Опорный вектор – это наш эталон, это тот вектор, который ассоциируется с каждой пользовательской сессией и именно с ним я сравниваю остальные полученные вектора людей в рамках этой сессии в текущей зоне интереса. В момент, когда пользователь вводит свои учетные данные (напомню, на входе у меня была выгрузка из Active Directory) я делаю несколько его фотографий, преобразую их в вектора и усредняю. Это и есть наш опорный вектор – цифровой идентификатор пользователя в момент входа в систему.
Кстати, получение опорных векторов — это еще и отличный способ собирать автоматически размеченный датасет, поскольку у меня есть возможность связать сделанную фотографию с учетными данными того, кто логинится (этот подход работает, если каждый человек входит в систему исключительно под своими учетными данными). Делая по несколько фотографий пользователя в момент входа в систему мне удалось собрать целую коллекцию изображений каждого пользователя в разных позах и положениях. Данный датасет и был использован при тренировке ResNet* и MLP моделей с помощью Metric Learning.
Рассмотрим пример:
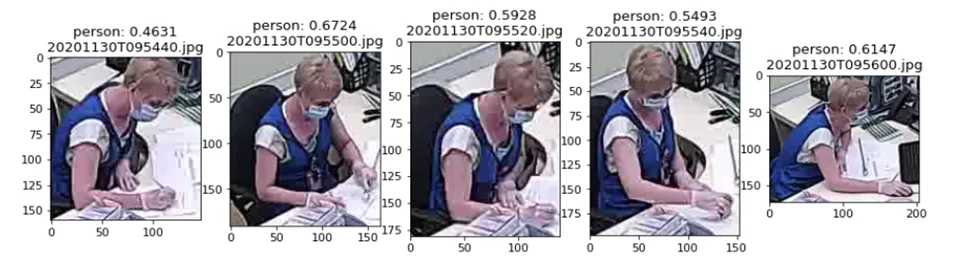
На изображении выше представлен набор из 5 изображений пользователя, снятых с небольшим интервалом в течении менее двух секунд с момента входа в систему. Эти кадры и лягут в основу опорного вектора. Мне известно, что пользовательская сессия на этом рабочем месте началась с 2020-11-30 09:54:21, а закончилась 2020-11-30 10:00:43. Взглянем на остальные вектора, полученные с этого же рабочего места в указанный период и сравним их косинусную близость к опорному вектору сессии (в качестве границы чувствительности cos_sim выбрано значение 0.7):

Как видно, спустя 4 минуты после входа в систему пользователь А покинул рабочее место не заблокировав компьютер и его место занял пользователь Б (метрика подобия значительно ниже выбранной границы и составляет 0.37 и 0.30). В данном случае ручной контроль показывает, что сотрудник Б не работает под учетными данными сотрудника А, а лишь занял его место, тем не менее признаки нарушения требований кибербезопасности можно зафиксировать, поскольку ничего не мешает сотруднику Б в подобной ситуации воспользоваться не заблокированным ПК.
Таким образом мне удалось избавить наших коллег от необходимости просматривать сотни часов не особо увлекательного видео. В дальнейшем я планирую улучшить модель – добавить в конец стека модель классификатора, возможно на базе все того же ResNet, которая бы делала вывод, работает сотрудник Б за компьютером, или же просто занял место. Это позволит еще больше разгрузить сотрудников и максимально снизить потребность в ручном контроле при выявлении случаев компрометации УЗ.
С основным пайплайном обучения моделей ResNet* и MLP с применением техники Metric Learning, а также примером их использования можно подробнее ознакомиться на Github.