/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Хочу представить нашим читателям, пару методов обработки исходных PDF-файлов, успешно внедренных мной.
- Иногда текст из файлов можно извлечь напрямую
На практике довольно часто встречаются PDF-файлы, которые были созданы конвертированием из doc/docx, из них можно извлечь текст напрямую с помощью библиотеки pdfminer.
Для начала хорошо бы определить такие файлы из всей выборки (рис.1):
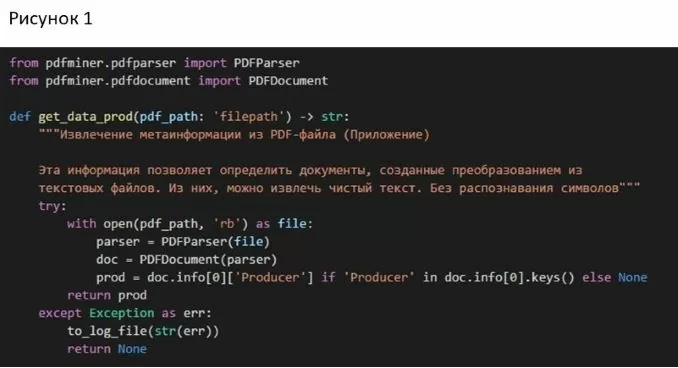
С помощью функции, реализованной выше мы извлекаем параметр Producer из метаинформации файла, если же конечно он присутствует. Он соответствует строчке «Приложение» при просмотре свойств pdf-файла (рис.2).
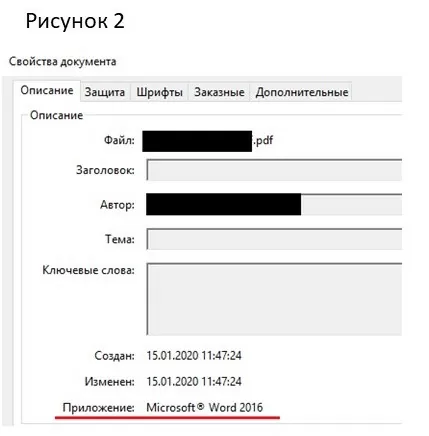
Отбираем те документы, которые были созданы с помощью Microsoft Word, извлеченный из них текст будет идеального качества.
Отмечу, что можно извлечь текст из документов, созданных с помощью программ ABBYY Finereader / PaperPort (такие документы уже содержат текст, распознанный с помощью встроенных в ПО алгоритмов). Однако этот текст уже был получен с помощью распознавания текста, а не конвертированием. И может быть ниже необходимой точности. Решать брать этот текст или самому «тюнить» Tesseract – решать вам.
С помощью этой функции из отобранных файлов можно постранично извлечь текст (рис.3):
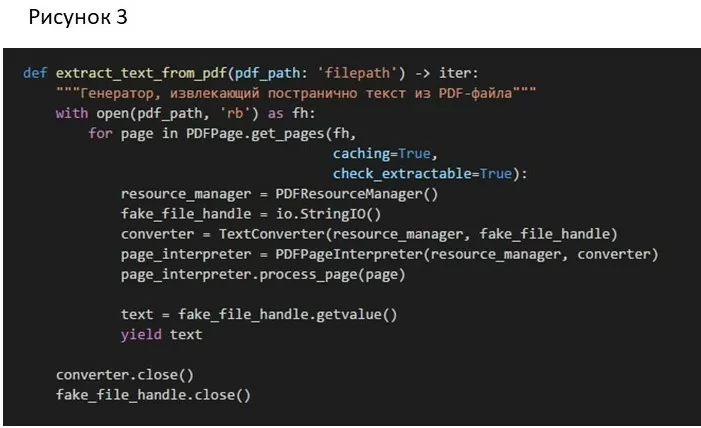
Для тех же файлов, где извлечь текст нельзя – будем действовать так:
- Преобразуем файл постранично в png;
- Препроцессинг изображений (поворачиваем если нужно, убираем блики/засветы);
- Определяем текст на изображении с помощью Tesseract.
2. Параллельные запуски
Ещё один способ ускорить обработку файлов – это параллельное выполнение. Моя реализация была осуществлена с помощью библиотеки concurrent.futures, а именно класса ProcessPoolExecutor – использующего многопроцессорность. Мы получаем пул процесса, отправляем туда задачи. Пул назначит задачи доступным ресурсам и запланирует их выполнение. ProcessPoolExecutor использует модуль multiprocessing и не подвержен блокировке GIL.
Распараллелить можно любую стадию из нашего пайплайна, я же рассмотрю только параллельную проверку на возможность извлечения текста из файла.
Делим весь список с путями к файлам на части по 64 элемента, чтобы не забивать пул задачами, то есть по сути устанавливаю этап синхронизации после каждых 64 элементов.
Каждому элементу из пачки файлов я применяю свою функцию обработки — get_data_prod. Пул назначит задачи доступным ресурсам и запланирует их выполнение. Параметр max_workers – это максимально допустимое число одновременно работающих процессов.
Модуль tqdm – нужен лишь как «обертка» над итератором для отрисовки прогресс бара в командной строке (рис.4).
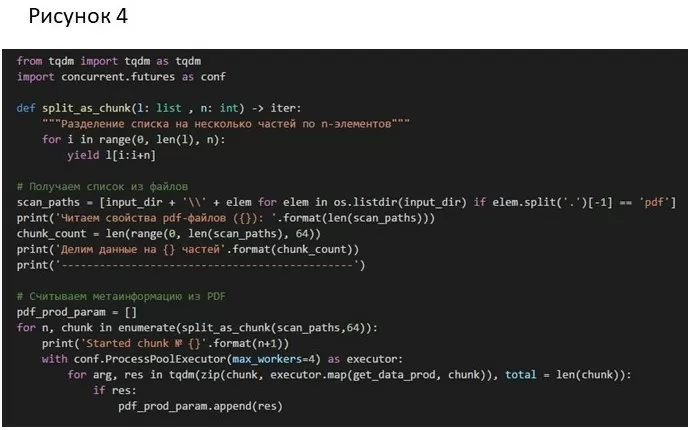
Подобным образом можно распараллелить каждый этап из обработки PDF-файлов, и значительно ее ускорить. Но при этом следует иметь ввиду, что при параллельном запуске tesseract в разных процессах будут подняты сразу несколько экземпляров tesseract.exe, и доступной ОЗУ будет все меньше.
Общие советы о параллельности:
- Не рекомендуется ставить число max_workers больше чем число физических ядер процессора
- Также нужно следить за ОЗУ, так как при обработке огромных изображений 19200х22000 пикселей (встречался реальный случай) может возникнуть Exception. Он связан с тем, что при считывании изображения в оперативную память мы по сути создаем структуру numpy array, который реализован на C на основе массива. Если у нас одновременно запущена обработка нескольких таких больших изображений (max_workers), вполне вероятно, что мы не сможем выделить в ОЗУ непрерывный блок памяти соответствующего размера. В этом случае мы получим MemoryError. Эту проблему можно решить масштабированием подобных изображений.
О том, как извлечь информацию из PDF вы сможете в статье по ссылке