/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
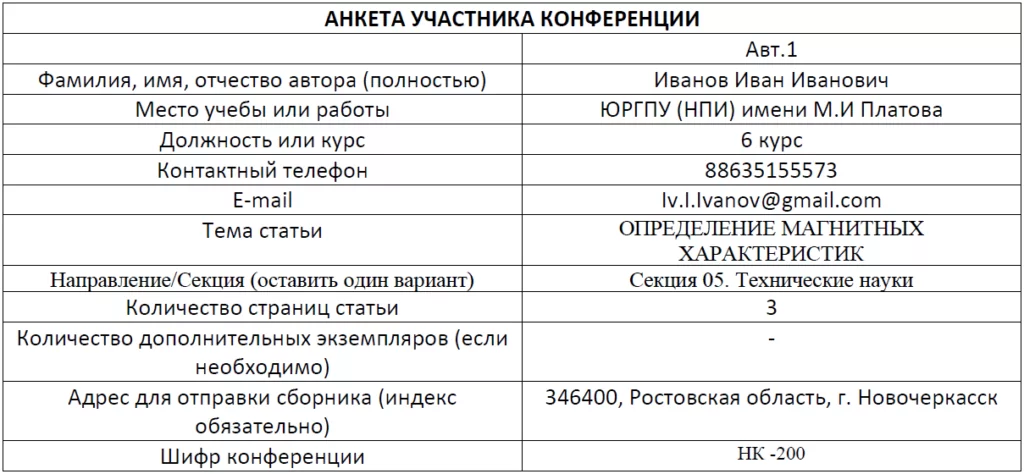
Предположим у нас есть набор из 30-страничных pdf-документов, каждый из которых содержит в себе различные листы, подписанные клиентом, при оформлении кредита или любого другого продукта. И лишь один лист содержит информацию (ФИО, паспортные данные, мобильный телефон и др.), которую необходимо извлечь. С помощью пары библиотек в Python, возможно реализовать алгоритм, который будет искать информативный лист и извлекать из него необходимую информацию. В качестве примера, для реализации алгоритма будет использоваться следующая страница из pdf-файла, которая содержит в себе таблицу с заголовком «Анкета участника конференции»:
Как и всегда реализация алгоритма начинается с импорта необходимых библиотек:

Библиотека fitz и PIL помогут в загрузке pdf-файлов и последующем разбиении на отдельные страницы. На библиотеку pytesseract возлагается основная задача, именно она будет просматривать каждую страницу и находить необходимую информацию.
Для того чтобы загрузить pdf-файл и разбить его на отдельные страницы воспользуемся функцией get_page_from_pdf:

На вход функции (path_to_pdf) нам нужно указать расположение pdf-файла, который мы хотим обработать, для этого создадим переменную, с указанием пути:

После вызова функции мы получим массив, который состоит из отдельных страниц обрабатываемого файла, массив обозначим переменной list_image:

Если бы все документы содержали одинаковую структуру (последовательность листов в документе), нам осталось бы указать номер страницы в документе и получить необходимую информацию. Однако, в большинстве случаев, это не так и нам приходиться просматривать страницу за страницей, пока не найдем нужную. С помощью функции find_target_page будем осуществлять поиск необходимой страницы:
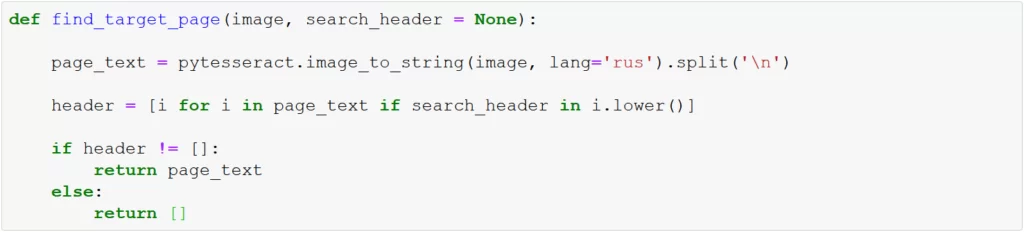
Как правило, каждая страница содержит заголовок, который характеризует к какому из пунктов относится страница, в данном примере: «Анкета участника конференции». В первый параметр (image) – указываем страницу из list_image, второй параметр (search_header) – содержит название заголовка, по которому будет осуществляться поиск необходимой страницы.
Далее реализуем функцию, которая извлечет необходимую информацию:

Функция get_info принимает на вход два параметра. Первый (page_text) — текст из страницы, которую функция find_target_page нашла по заголовку. Второй (search_object) – необходимая информация, которую хотим извлечь из текста. Реализация функции get_info зависит от формата страницы и расположения текста, таким образом, предобработку текста – строку с (prepare_text) необходимо переделать под конкретный пример.
Раннее, в переменную list_image постранично загрузили файл «Example.pdf». Осталось объединить реализованные функции, и обработать файл:

В цикле осуществляем поиск страницы, на наличие искомого заголовка с помощью функции find_target_page. Как только страница будет найдена, текст с этой страницы передаем на функцию get_info. Для начала найдем ФИО, для этого в параметр search_object передадим слово «фамилия», по которому алгоритм определит расположение искомого значения. Повторим процедуру, но уже для нахождения «контактный телефон». По завершении обработки, должен появиться следующий результат.

Резюме: для загрузки pdf-файла вам понадобится функция get_page_from_pdf. Если необходимо загрузить изображения (сканы документов), в этом поможет библиотека PIL, в интернете можно найти множество примеров, как это сделать. Для извлечения текста из картинки потребуется всего одна строчка кода:

Остальное – творческий процесс, ограниченный только вашими потребностями.