/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В процессе аудита часто приходится решать нестандартные задачи анализа данных. В этом может помочь язык SQL. Расскажу об одной из таких задач и о том, как я ее решил.
Мне предстояло, на основании информации о статусе клиентов на отчетную дату подсчитать длительность каждого периода, в котором этот признак был равен единице, и пронумеровать даты по порядку в рамках этих периодов.
Таблица с данными имеет следующий вид:
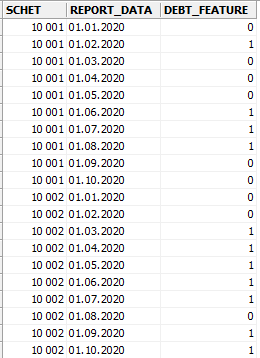
Поля – SCHET (номер счета клиента), REPORT_DATA (отчетная дата – первое число каждого месяца), DEBT_FEATURE (оцениваемый признак на дату отчета).
Я воспользовался оконной функцией row_number() и написал такой запрос:
select
new_table.*
,case
when
debt_feature = 1
then
row_number() over(partition by schet, debt_feature order by schet, report_data, debt_feature)
else
0
end
from
new_table
order
by schet, report_data, debt_feature
Получилось не совсем то, что нужно – нумерация была сквозной в рамках каждого счета. Мне же требовалось начинать подсчет заново в рамках каждого периода со статусом «1».
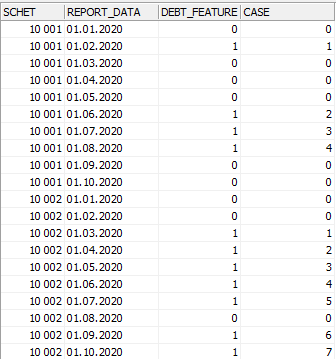
Необходимо добавить какое-то дополнительное поле, чтобы оконная функция корректно разделила таблицу.
Единственным вариантом для манипуляций в данной ситуации является поле, содержащее отчетную дату. Для начала я попробовал найти минимальную и максимальную даты, ограничивающие каждый период в рамках одного счета.
Логика для поиска минимальной даты такая – найти минимальную дату для каждого периода, которая будет больше максимальной даты для предыдущей группы, которая, в свою очередь, должна быть меньше даты в текущей строке. Звучит запутанно, но дальше станет понятнее.
Для нахождения минимальной даты я написал такой запрос:
select
nt.*
,(
select
min(nt_min.report_data)
from
new_table as nt_min
where
nt_min.schet = nt.schet
and nt_min.debt_feature = nt.debt_feature
and nt_min.report_data <= nt.report_data
and nt_min.report_data >
(
select
max(nt_.report_data)
from
new_table as nt_
where
nt_.schet = nt.schet
and nt_.debt_feature != nt.debt_feature
and nt_.report_data <= nt.report_data
)
) as min_data
from
new_table as nt
order
by schet, report_data
Вот что получилось:
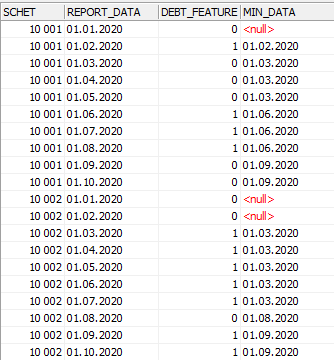
Видно, что для каждого периода, кроме тех, начало которых пришлось на первую запись в рамках счета, найдена минимальная дата. Например, для этой группы:

Минимальная дата равна 01.06.2020. Это значение проставляется для каждой записи, принадлежащей выбранной группе.
Те записи, с которых начинаются данные в рамках каждого счета не имеют предыдущих периодов. В связи с этим для них минимальная дата не может быть рассчитана – признаку присваивается значение null.
Теперь необходимо найти максимальную дату для каждой группы. Здесь логика проще – найти минимальную дату для следующей группы, большую, чем дата в текущей строке. Запрос получился такой:
select
nt.*
,(
select
min(nt_max.report_data)
from
new_table as nt_max
where
nt_max.schet = nt.schet
and nt_max.debt_feature != nt.debt_feature
and nt_max.report_data > nt.report_data
) as max_data
from
new_table as nt
order by
schet, report_data
Результат совместного выполнения двух запросов представлен на рисунке:
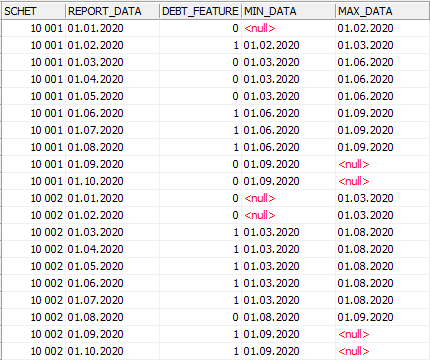
Посмотрим на тот же период для счета 10001:

Максимальной дате присвоено значение минимальной даты, следующей за рассматриваемой группой. Также для тех записей, которые не имеют следующей группы, значение признака равно null.
На основании новых данных я рассчитал еще один признак. Для этого посчитал длину каждого периода и объединил ее с датой начала этого периода в виде строки. Также учел случаи, когда минимальная или максимальная дата периода не рассчитана в связи с отсутствием данных (начало или конец периода приходится на начальные или конечные записи в рамках счета). Получилась такая таблица:
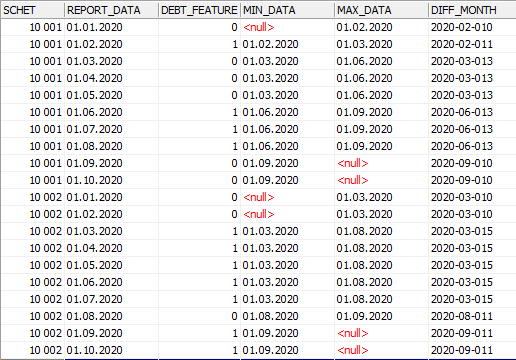
Видно, что новый признак уникален в рамках каждой группы, и можно проводить разбиение данных по нему. Итоговый запрос получился таким:
select
result.schet
,result.report_data
,result.debt_feature
,case
when
result.debt_feature = 1
then
result.number
else 0
end as count_debt
from
(
select
outer_query.*
,row_number() over(partition by outer_query.schet, outer_query.diff_month order by outer_query.schet, outer_query.report_data) as number
from
(
select
inner_query.*
,
case
when
cast(inner_query.min_data as varchar(10)) ||
cast(
(extract(year from inner_query.max_data) * 12 + extract(month from inner_query.max_data))
-
(extract(year from inner_query.min_data) * 12 + extract(month from inner_query.min_data))
as varchar(10)) is not null
then
cast(inner_query.min_data as varchar(10)) ||
cast(
(extract(year from inner_query.max_data) * 12 + extract(month from inner_query.max_data))
-
(extract(year from inner_query.min_data) * 12 + extract(month from inner_query.min_data))
as varchar(10))
when
inner_query.min_data is not null
then
cast(inner_query.min_data as varchar(10)) || cast(inner_query.debt_feature as varchar(10))
when
inner_query.max_data is not null
then
cast(inner_query.max_data as varchar(10)) || cast(inner_query.debt_feature as varchar(10))
end as diff_month
from
(
select
nt.*
,(
select
min(nt_min.report_data)
from
new_table as nt_min
where
nt_min.schet = nt.schet
and nt_min.debt_feature = nt.debt_feature
and nt_min.report_data <= nt.report_data
and nt_min.report_data >
(
select
max(nt_.report_data)
from
new_table as nt_
where
nt_.schet = nt.schet
and nt_.debt_feature != nt.debt_feature
and nt_.report_data <= nt.report_data
)
) as min_data
,(
select
min(nt_max.report_data)
from
new_table as nt_max
where
nt_max.schet = nt.schet
and nt_max.debt_feature != nt.debt_feature
and nt_max.report_data > nt.report_data
) as max_data
from new_table as nt
order by schet, report_data
) as inner_query
) as outer_query
order by schet, report_data
) as result
В нем я добавил фильтр по признаку, чтобы не выводить подсчет в рамках периодов со значением признака, равным нулю. Также оставил в выводе только столбцы с требуемой информацией без промежуточных расчетов. Результат получился такой, как и требовалось в задаче:
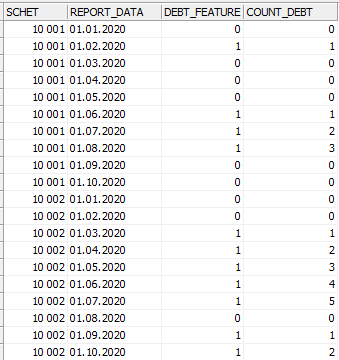
Запрос написан в среде IBExpert для СУБД Firebird 3.0.7.33374_1. При необходимости его можно переработать для любой другой СУБД, поддерживающей оконные функции, например, MS SQL Server.