/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В практике использования SQL Server для исследования данных, важным шагом является процесс ETL, который, например, может содержать преобразование одного типа данных в другой или очистку данных путем удаления пробелов. И тогда, если в исходных данных присутствуют непечатаемые (управляющие) символы ASCII (American Standard Code for Information Interchange), процесс ETL может осложниться при поиске и удалении этих символов.
В этой статье я расскажу о способах решения таких случаев, в т.ч. с применением созданной пользовательской функции.
Для начала рассмотрим пример того, как можно справиться с заменой печатаемых символов ASCII.
SQL Server, использующий ANSI, имеет встроенную функцию char, с помощью которой можно преобразовать числовой код символа ASCII в исходный символьный код. К примеру, числовой код ASCII 91 связан с символом открывающейся квадратной скобки [.
Пример ниже показывает, как преобразовывается числовой код 91 в символ [:
SELECT CHAR(91) as 'Symbol';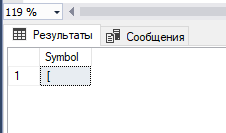
Используя функцию replace можно без труда заменить большинство печатаемых символов ASCII для решения задачи по обеспечению качества данных ETL-процесса.
Вот пример того, как очистить данные с адресом электронной почты от недопустимых символов ASCII, которые могут там присутствовать (!, #, $).
DECLARE @get_email VARCHAR(55) = 'mypostbox@em!ai#l.com$';Удаляем печатаемые символы (!, #, $), применяя функцию replace, и получаем допустимый адреса электронной почты:
SELECT REPLACE(REPLACE(REPLACE(@get_email, '!', ''), '#', ''), '$', '') as 'e-mail';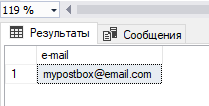
Далее посмотрим, как решить задачу очистки данных от непечатаемых символов ASCII, которые не всегда видны и которые трудно заменить, используя replace.
Предположим, мы имеем текстовый файл myrealpostbox.txt, который содержит адреса электронной почты, но верный формат только у одной первой строки из-за того, что остальные строки содержат непечатаемые символы ASCII. И, если открыть этот файл, например, в редакторе Notepad, то заметить эти символы ASCII невозможно.
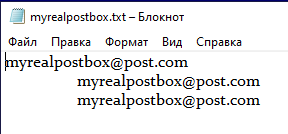
На первый взгляд может показаться, что в строках 2 и 3 есть пробелы, но утверждать, что они созданы символами горизонтальной табуляции или символами пробела затруднительно. И также кажется, что адреса электронной почты строк 1, 2 и 3 содержат одинаковое количество символов. Для того чтобы визуально убедиться, что это не так, откроем файл в редакторе Notepad ++ включив отображение всех символов:
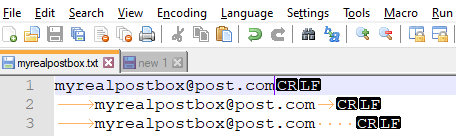
Импортируем данные из текстового файл myrealpostbox.txt в таблицу БД SQL Server [dbTest].[dbo].[myrealpostbox].
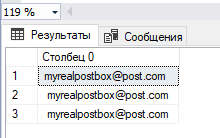
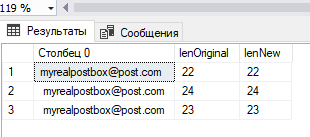
Теперь, если применить для очистки непечатаемых символов ASCII из таблицы [dbTest].[dbo].[myrealpostbox] функцию replace, то увидим из результата выполнения скрипта ниже, что попытка будет неудачной, т.к. длина данных в оригинальном столбце и длина данных в новом столбце, которая рассчитывается после применения replace и trim, одинаковая, т.е. не изменяется.
SELECT [Столбец 0],
LEN([Столбец 0]) lenOriginal,
LEN(REPLACE(REPLACE(LTRIM(LTRIM([Столбец 0])), ' ', ''), ' ', '')) lenNew
FROM [dbTest].[dbo].[myrealpostbox];
Рассмотрим другой вариант решения этой задачи для успешной очистки непечатаемых символов ASCII из данных таблицы [dbTest].[dbo].[myrealpostbox]. Выполним динамическую замену символов ASCII, создав пользовательскую функцию Rep_ASCII с циклом While, просматривающую заданную строку, идентифицирующую и затем заменяющую непечатаемые символы.
CREATE FUNCTION [dbo].[Rep_ASCII](@input_Str VARCHAR(8000))
RETURNS VARCHAR(55)
AS
BEGIN
DECLARE @bad_Str VARCHAR(100);
DECLARE @incr INT= 1;
WHILE @incr <= DATALENGTH(@input_Str)
BEGIN
IF(ASCII(SUBSTRING(@input_Str, @incr, 1)) < 33)
BEGIN
SET @bad_Str = CHAR(ASCII(SUBSTRING(@input_Str, @incr, 1)));
SET @input_Str = REPLACE(@input_Str, @bad_Str, '');
END;
SET @incr = @incr + 1;
END;
RETURN @input_Str;
END;
GO
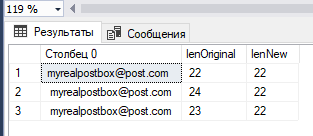
И далее применим функцию Rep_ASCII для задачи замены непечатаемых символов ASCII в данных таблицы [dbTest].[dbo].[myrealpostbox]:
SELECT [dbTest].[dbo].[myrealpostbox].[Столбец 0],
LEN([Столбец 0]) lenOriginal,
LEN([dbTest].[dbo].[Rep_ASCII]([Столбец 0])) lenNew
FROM [dbTest].[dbo].[myrealpostbox];
GO
В результате можно видеть, что новая длина строк 2 и 3 изменилась и стала такой же, как и у строки 1, которая содержит верный адрес электронной почты.
Рассмотренные способы очистки данных с применением функции replace и созданной пользовательской функцией Rep_ASCII (с использованием, поставляемых в составе SQL Server дополнительных встроенных функций CHAR и ASCII) позволяют упростить очистку данных от печатаемых и непечатаемых символов ASCII, что является наиболее сложным в процессе ETL.