/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Огромную долю в восприятии информации человеком занимает визуальная информация. Практически всё в мире можно представить в виде изображения. Изображения и видео могут содержать в себе очень много данных — именно поэтому задачи по обработке изображений человек отдает машине.
Компьютерное зрение применяется во многих сферах, например, в детекции, классификации, сегментации объектов на изображении. И для каждой уникальной проблемы внутри этих сфер необходимо создать автоматизированное решение, научить компьютер.
В публикации речь пойдет об одном из важнейших этапов создания моделей компьютерного зрения – предварительной обработке изображений. Используя различные способы предобработки, можно достичь более высоких показателей качества и быстродействия обученной модели. Например, снизить или повысить до необходимого уровня качество картинок, расширить датасет в случае недостатка входных данных с помощью аугментации, выделить или затенить объекты, и так далее – все зависит от решаемой проблемы. Здесь мы рассмотрим некоторые из ключевых методик в предобработке изображений и задачи, в которых они могут применяться.
Но для начала попробуем разобраться, что такое изображение для компьютера?
Изображение можно определить как двумерную функцию F(x,y), где x и y — координаты на плоскости изображения, а амплитуда f называется интенсивностью или яркостью изображения в точке с этими координатами. В цифровых изображениях значение функции F(x, y) – конечно. То есть, цифровое изображение – это массив пикселей, расположенных в столбцах и строках. Пиксели — это элементы изображения, которые содержат информацию о насыщенности. Изображение также может быть представлено в 3D, где x, y и z становятся пространственными координатами. Пиксели расположены в виде матрицы. F(x,y) – черно-белое изображение, F(x,y,z) – цветное.
Отличие черно-белого изображения от цветного колоссально. Первое – это одномерное пространство черных и белых точек, пикселей. Цветное изображение обычно представляется в виде трех одномерных пространств, наложенных друг на друга:
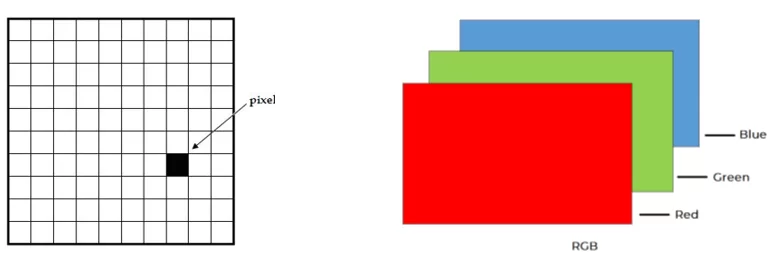
В процессе обработки изображений, кстати, чаще используют черно-белые картинки. Использование оттенков серого/черно-белого помогает упростить алгоритмы и увеличить скорость обработки. Плюс такие изображения легче воспринимать.
От слов перейдем к делу. Самый популярный инструмент для обработки изображений на Python – OpenCV. Для изучения данного инструмента написано много литературы, он довольно прост в установке и работе. Также установим модуль Matplotlib. С его помощью можно выводить изображения в интерфейсе Jupyter Notebook. Для установки выполним в командной строке две простые команды:
pip install opencv-python
pip install matplotlibТеперь попробуем преобразовать цветного тигра в черно-белого. Делается это просто. Для начала импортируем библиотеки, которые понадобятся для работы:
import cv2
import numpy as np
from matplotlib import pyplot as plt
Теперь «прочитаем» изображение, используя функцию cv2.imread(). А для преобразования цветных картинок в черно-белые используем функцию cv2.cvtColor с параметром cv2.COLOR_BGR2GRAY():
image = cv2.imread('tiger.jpg')
image = np.flip(image, axis=-1)
bw_img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Используем следующий код:
images = []
images.append(image)
images.append(bw_img)
titles = ['тигр','тигр чб']
for i in range(len(images)):
plt.subplot(1,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
В результате выполнения этих команд будут выведены изображения:

Получившуюся картинку можно сохранить, используя функцию cv2.imwrite():
cv2.imwrite('bw_tiger.jpg', bw_tiger)Теперь перейдем к более сложным алгоритмам обработки изображений.
Морфологическая обработка изображений:
Этот метод позволяет удалить дефекты из бинарных изображений. Иногда области, созданные в результате простой обработки, могут быть искажены шумом. Морфологическая же обработка позволяет сглаживать изображения.
Морфологические операции отображаются на структуре черно-белых изображений. Этот метод изменяет изображение, используя некоторый шаблон или фильтр, структурирующий элемент. Он помещается в различные места на изображении и сравнивает между собой разные области с группами пикселей, преобразуя их в зависимости от задачи.
Есть два вида морфологического преобразования:
1. Дилатация (морфологическое расширение) – это свертка изображения или выделенной области изображения с шаблоном. В шаблоне выделяется единственная ведущая позиция (anchor), которая совмещается с текущим пикселем при вычислении свертки. Во многих случаях в качестве шаблона выбирается квадрат или круг с ведущей позицией в центре. Такая операция вызывает рост светлых областей на изображении.
2. Эрозия (морфологическое сужение) – операция, обратная дилатации. Эта операция вызывает уменьшение светлых областей на изображении.
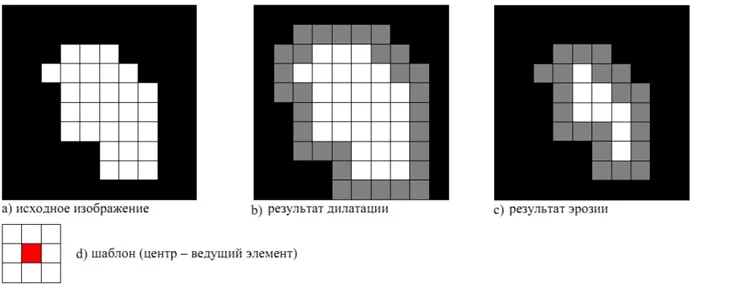
Применение этих операций может повысить «читаемость» текста.
Посмотрим, как это работает, используя функции cv2.dilate(), cv2.erode() с заранее заданным ядром (kernel) размером 3х3 пикселя:
# чтение изображения
img = cv2.imread('letters.jpg')
# определение ядра свертки
morph_kernel = np.ones((3, 3))
# применение функций к изображению
# параметр iterations означает, сколько раз будет применена операция
dilate_img = cv2.dilate(img, kernel= morph_kernel, iterations=1)
erode_img = cv2.erode(img, kernel= morph_kernel, iterations=1)
Код для вывода изображений на экран или их сохранения можете адаптировать из предыдущего примера. Результат выполнения функций:

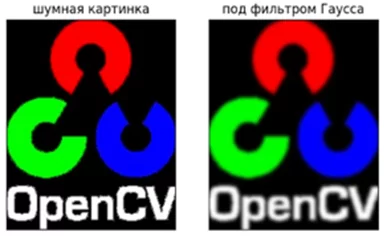
Фильтр размытия по Гауссу:
Блюр (размытие) часто используется для сглаживания неравномерных значений пикселей изображения, обрезая самые высокие значения. В алгоритмах компьютерного зрения данный метод используется для улучшения структуры изображения в различных масштабах, для уменьшения размера изображения.
Итак, пусть исходное изображение будет задано яркостью x(m,n). Гауссово размытие с радиусом r считается по формуле:
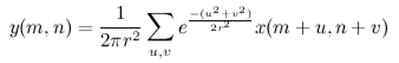
Вывод формулы займет слишком много места и не так важен в этой статье. На хабре есть подробное описание (https://habr.com/ru/post/151157/), как из формулы получается такое ядро фильтра:

Размытие по Гауссу на изображении в OpenCV происходит в два этапа. В первом проходе так называемое ядро фильтра Гаусса размывает изображение по одной из плоскостей (горизонтальной или вертикальной). А во втором проходе размывает по оставшейся плоскости.
Применим фильтр Гаусса в OpenCV, используя функцию cv2.GaussianBlur():
img = cv2.imread('distorted.png')
# параметром ksize=(11, 11) зададим размер ядра фильтра размытия 11х11 пикселей:
# параметры sigmaX/Y 0, 0 отвечают за сдвиг ядра при проходе по осям X, Y
blurred_img = cv2.GaussianBlur(img, ksize=(11, 11), sigmaX =0, sigmaY=0)
Результат выполнения функций:
Повышение резкости изображения:
В процессе обработки изображений могут возникать сценарии, когда изображение размыто и для выполнения задачи необходимо его «восстановить». То есть, увеличить резкость.
К сожалению, как в старых голливудских фильмах не получится. Нельзя просто взять и преобразовать мелкий кадр номера авто, находящегося в километре от камеры с разрешением 0.3 мегапикселя, во что-то читаемое. Но можно попытаться. И для этого есть метод в OpenCV! И он предполагает применение фильтра к изображению. Кстати, подробнее о других фильтрах для обработки можно почитать на Вики (https://en.wikipedia.org/wiki/Kernel_(image_processing)).
Процесс увеличения резкости обычно используется для улучшения видимости краев изображения. Есть много фильтров, которые мы можем использовать, но наиболее популярный из них можно представить в виде следующей матрицы:

Суть та же, что и раньше: проходим последовательно по каждой оси изображения и модифицируем группы пикселей для достижения желаемого результата.
Сначала зададим ядро фильтра (матрицу), после чего применим ее к изображению, используя функцию cv2.filter2D():
img = cv2.imread('blurred.jpg')
sharp_filter = np.array([[-1, -1, -1], [-1, 9, -1], [-1, -1, -1]])
# параметр ddepth отвечает за «глубину» картинки
# ddepth=-1 означает, что глубина получившейся картинки будет как у исходной
sharpen_img = cv2.filter2D(img, ddepth=-1, kernel=sharp_filter)
Результат выполнения функций:

Определение границ объектов на изображении:
Да, есть и такие задачи. Данный метод может пригодиться для извлечения «полезной» информации о форме объекта из изображения. Для определения формы объекта, человек подсознательно ищет резкие переходы между уровнями яркости частей объектов. Сделаем точно также и в машинном алгоритме.
Наиболее распространенным алгоритмом обнаружения краев является фильтр (оператор) Собеля. Этот оператор основан на свёртке изображения небольшими сепарабельными целочисленными фильтрами в вертикальном и горизонтальном направлениях, поэтому его относительно легко вычислять. С другой стороны, используемая им аппроксимация градиента достаточно грубая, особенно это сказывается на высокочастотных колебаниях изображения. Оператор вычисляет градиент яркости изображения в каждой точке. Так находится направление наибольшего увеличения яркости и величина её изменения в этом направлении. Результат показывает, насколько резко или плавно меняется яркость изображения в каждой точке, а значит, вероятность нахождения точки на грани, а также ориентацию границы.
Оператор использует 2 ядра 3х3, которыми сворачивают исходное изображение для вычисления приближённых значений производных по горизонтали и по вертикали. Пусть А —исходное изображение, а Gx и Gy— два изображения, на которых каждая точка содержит приближённые производные по x и y. Они вычисляются следующим образом (* — операция свертки):
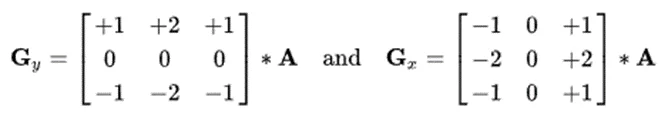
Координата x здесь возрастает «направо», а y — «вниз». В каждой точке изображения приближённое значение величины градиента можно вычислить путём использования полученных приближенных значений производных:

Для более корректного выделения объекта рекомендуется немного уменьшить четкость изображения. Здесь используем упомянутый ранее cv2.GaussianBlur(). За применение оператора Собеля в OpenCV отвечает функция cv2.Sobel():
img = cv2.imread('tiger.jpg')
# для использования оператора собеля сразу по 2 осям зададим параметры dx=1, dy=1
# используя параметр ddepth=cv2.CV_64F, зададим глубину изображения в 64 бита
sobelxy = cv2.Sobel(img, ddepth=cv2.CV_64F, dx=1, dy=1, ksize=5)
Результат выполнения функций:

Благодарю за прочтение. В заключение хочется напомнить, что в данной статье описаны только некоторые часто используемые алгоритмы обработки изображений. Естественно, их гораздо больше. Для решения разных задач могут понадобиться разные алгоритмы или их комбинации. Постарайтесь применять их там, где это действительно нужно, и помните главное правило при разработке моделей – «garbage in, garbage out».